[알고리즘] 문자열 매칭 알고리즘 KMP (Java)
문자열 매칭 알고리즘
특정한 글이 있을 때 그 글 안에서 하나의 문자열을 찾는 알고리즘이다. 워드파일 또는 웹 브라우저 DB에서 문자열을 검색할 때 패턴 매칭 알고리즘을 사용하여 검색 결과를 표시한다.
단순 문자열 알고리즘
가장 간단한 문자열 매칭 알고리즘으로, 말 그대로 하나씩 확인하는 방법을 사용한다.
- 검색할 문자열 ABDEGH
- 찾는 문자열 DE
가장 앞부분부터 찾는 문자열이 매칭될 때 까지 탐색을 시작한다.
| 검색할 문자열 | A | B | D | E | G | H |
| 찾는 문자열 | D | E |
매칭이 이루어지지 않았다면 한 칸씩 옆으로 이동시킨다.
| 검색할 문자열 | A | B | D | E | G | H |
| 찾는 문자열 | D | E |
매칭이 이루어졌으면 탐색을 종료한다.
| 검색할 문자열 | A | B | D | E | G | H |
| 찾는 문자열 | D | E |
코드
이 알고리즘은 이중포문으로 시간복잡도는 O(N*M)이 된다. 효율적이지는 않지만 코드가 직관적이라서 간단하게 사용하기 좋다.
import java.io.*;
public class SimpleStringMatching {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String s1 = br.readLine();
String s2 = br.readLine();
System.out.println(findString(s1,s2));
}
static int findString(String parent, String pattern) {
int n1 = parent.length();
int n2= pattern.length();
for(int i=0; i<=n1-n2; i++) {
boolean flag = true;
for(int j=0; j<n2; j++) {
if(parent.charAt(i+j) != pattern.charAt(j)) {
flag = false;
break;
}
}
if(flag) {
return 1; // 문자열을 찾으면 1
}
}
return 0; // 찾지 못했으면 0
}
}
KMP(Knuth-Morris-Pratt) 알고리즘 ⭐
위와 같은 단순 문자열 매칭 알고리즘은 긴 문자열을 탐색할 경우 최악의 경우가 발생하면 엄청난 시간이 소요될 것이다. 그래서 모든 경우를 다 비교하지 않아도 되는 KMP 문자열 매칭 알고리즘을 공부해보자 (참고)
KMP는 접두사와 접미사의 개념을 활용하여 모든 경우를 계산하지 않고 반복되는 연산을 줄여나가 매칭 문자열을 빠르게 점프하는 기법으로 효율적으로 문자열 매칭을 이루어나간다.
KMP 알고리즘을 동작시키기 위해서는 접두사도 되고 접미사도 되는 문자열의 최대 길이를 저장해주는 table을 미리 정의해줘야한다. table[]은 pattern이 어디까지 일치했는지가 주어질 때 다음 시작 위치를 어디로 해야할지를 말해주기 때문에, 이를 흔히 부분 일치 테이블이라고 부른다.
- table[i] = pattern(0...i)의 접두사도 되고 접미사도 되는 문자열의 최대 길이
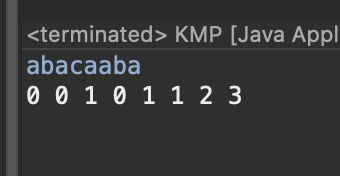
예를 들어, abacaaba가 있을 때 다음과 같다.
| i | pattern(0...i) | 접두사이면서 접미사인 최대 문자열 | table[i] |
| 0 | a | (없음) | 0 |
| 1 | ab | (없음) | 0 |
| 2 | aba | a | 1 |
| 3 | abac | (없음) | 0 |
| 4 | abaca | a | 1 |
| 5 | abacaa | a | 1 |
| 6 | abacaab | ab | 2 |
| 7 | abacaaba | aba | 3 |
a b a c a a b a
‣ table[] 0 0 1 0 1 1 2 3
일치하는 접두사와 접미사의 최대길이는 aba로 3이다. 해당 탐색한 결과를 table[] 배열에 저장하면 다음과 같이 저장된다.
static int[] makeTable(String pattern) {
int n = pattern.length();
int[] table = new int[n];
int idx=0;
for(int i=1; i<n; i++) {
// 일치하는 문자가 발생했을 때(idx>0), 연속적으로 더 일치하지 않으면 idx = table[idx-1]로 돌려준다.
while(idx>0 && pattern.charAt(i) != pattern.charAt(idx)) {
idx = table[idx-1];
}
if(pattern.charAt(i) == pattern.charAt(idx)) {
idx += 1;
table[i] = idx;
}
}
return table;
}
접두사와 접미사가 일치하는 최대길이를 구한 부분 일치 테이블을 구했다면 이후 동작 과정은 간단하다. 이제 table함수를 이용하여 parent 문자열과 find 문자열을 index=0부터 비교해주면 된다.
2-1) KMP 알고리즘의 전통적인 구현 방식
다음은 KMP 알고리즘의 전통적인 구현 방식이다.
- 문자열 맨 앞부분인 begin, matched = 0부터 탐색을 시작한다. (matehed는 일치하는 문자열의 수를 나타낸다.)
- 만약 pattern과 parent의 해당 글자가 일치한다면 if(matched < n2 && parent.charAt(begin+matched) == pattern.charAt(matched))
- matched 카운트를 증가시켜 준다. matched++;
- match된 글자가 pattern글자의 총 길이와 일치했다면 답에 추가한다.
- 만약 pattern과 parent의 해당 글자가 일치하지 않는다면
- matched가 0인 경우 다음 칸에서 계속한다.
- begin의 위치를 옮겨준다. begin += matched - table[matched-1];
- 옮겼다고 처음부터 다시 비교할 필요가 없다. table[matched-1]만큼은 항상 일치하기 때문이다.
static void KMP(String parent, String pattern){
int[] table = makeTable(pattern);
int n1 = parent.length(), n2 = pattern.length();
int begin =0, matched=0; // begin = matched = 0
while(begin <= n1-n2) {
// 만약 짚더미의 해당 글자가 바늘의 해당 글자가 같다면
if(matched < n2 && parent.charAt(begin+matched) == pattern.charAt(matched)) {
++matched;
// 결과적으로 m글자가 모두 일치했다면 답에 추가한다.
if(matched == n2) {
System.out.println(i-idx+1 + "번째에서 찾았습니다. ~" + (begin+1) );
}
}else{
// 예외 : matched가 0인 경우에는 다음 칸에서부터 계속
if(matched ==0) {
++begin;
}else {
begin += matched - table[matched-1];
// begin을 옮겼다고 처음부터 다시 비교할 필요가 없다.
// 옮긴 후에도 table[matched-1]만큼은 항상 일치하기 때문이다.
matched = table[matched-1];
}
}
}
}2-2) KMP 알고리즘의 다른 구현 방식 (이게 더 선호됨)
전통적인 구현은 KMP 알고리즘을 처음 제안한 논문에서 보인 구현으로 이해가 조금 까다롭다. 해당 알고리즘은 더욱 간결하기 때문에 자주 볼 수 있으며 KMP 알고리즘을 응용해 다른 알고리즘을 만드는 기반으로도 더 유용하게 쓰일 수 있다.
a) idx>0, parent의 i번째 문자 != find의 j(idx)번째 문자
- idx = table[idx-1];
문자열 매칭이 시작된 후 연속적으로 매칭이 되지않을때 다시 매칭을 시작해야 하므로 idx값을 다시 돌려준다.
그런데 만약 문자열 매칭된 부분이 접두사와 접미사가 같은 구간이라면 idx는 0이아닌 그 일치하는 길이만큼의 값을 받게된다. 그러므로 앞에 접두사부분을 생략하고 다시 재빠르게 탐색이 가능해진다.
b) parent의 i번째 문자 == find의 j(idx)번째 문자
- if( idx == find문자열 길이-1) : 탐색 종료
- else : idx값 1증가
idx값이 (find문자열 길이-1)까지 도달했다면 문자열 매칭을 성공한 것이므로 탐색을 종료한다. 아니면 일치할 때마다 idx값을 1증가하여 다음 문자를 매칭하도록 한다.
- i = matched + begin, idx = matched 라고 생각하면 위와 동일하다.
static void KMP(String parent, String pattern) {
int[] table = makeTable(pattern);
int n1 = parent.length();
int n2 = pattern.length();
int idx = 0; // 현재 대응되는 글자 수
for(int i=0; i< n1; i++) {
// idx번 글자와 짚더미의 해당 글자가 불일치할 경우,
// 현재 대응된 글자의 수를 table[idx-1]번으로 줄인다.
while(idx>0 && parent.charAt(i) != pattern.charAt(idx)) {
idx = table[idx-1];
}
// 글자가 대응될 경우
if(parent.charAt(i) == pattern.charAt(idx)) {
if(idx == n2-1) {
System.out.println(i-idx+1 + "번째에서 찾았습니다. ~" + (i+1) );
idx =table[idx];
}else {
idx += 1;
}
}
}
}
KMP 알고리즘 탐색과정
KMP 알고리즘은 접두사와 접미사가 일치하는 경우에 문자열 매칭을 탐색할 때 점프를 할 수 있어서 굉장히 효율적으로 작동하게 된다. 직접 예시를 풀어나가보면서 이해해보자.
먼저 두 문자열을 비교하여 접두사와 접미사의 일치하는 최대의 길이를 찾아준다.
- 검색할 문자열(pattern): ababacabacaaba이고, 찾는 문자열(find): abacaaba 이라고 하자.
pattern의 테이블을 다음과 같이 구해준 다음 위의 로직과 같이 반복문을 돌려준다.
- pattern: table배열 [ 0 0 1 0 1 1 2 3]
- 반복문 i: 0 ~ parent문자열 길이(n1)
1) i=0, idx =0 → idx 1증가
a 일치
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | a | b | a | c | a | a | b | a | ||||||
| idx | 0 |
2) i=1, idx =1 → idx 1증가
b 일치
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | a | b | a | c | a | a | b | a | ||||||
| idx | 0 | 1 |
3) i=2, idx =2 → idx 1증가
a 일치
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | a | b | a | c | a | a | b | a | ||||||
| idx | 0 | 1 | 2 |
4) i=3, idx =3 → idx = table[idx-1] = table[2] = 1
b != c 불일치
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | a | b | a | c | a | a | b | a | ||||||
| idx | 0 | 1 | 2 | 1 |
5) i=4, idx =1 → idx 1증가
- 이전 탐색에서 불일치 되어도 idx=1부터 시작하는 이유는 pattern 접두사 a와 접미사 a가 일치하므로 idx=1 (b)부터 탐색하는 것이다. 이것이 kmp 알고리즘이 빠르게 동작하는 이유다.
a 일치
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | b | a | c | a | a | b | a | |||||||
| idx | 1 | 2 |
6~7 ) c, a 일치 → idx 증가
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | b | a | c | a | a | b | a | |||||||
| idx | 1 | 2 | 3 | 4 |
8) i=7, idx= 5 → idx =table[4] = 1
b != a 불일치
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | b | a | c | a | a | b | a | |||||||
| idx | 1 | 2 | 3 | 4 |
9) i=8, idx= 1
- 8)에서 불일치되었으므로 다시 탐색을 시작한다. 이번에도 접두사 접미사 a가 일치하므로 탐색 b(idx=1)부터 재탐색을 시작한다.
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | b | a | c | a | a | b | a | |||||||
| idx | 1 |
나머지) i = 9 ~ 14
| parent | a | b | a | b | a | c | a | b | a | c | a | a | b | a |
| pattern | b | a | c | a | a | b | a | |||||||
| idx | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
이렇게 끝까지 탐색하면 idx = 7 ( pattern문자열 길이-1)에 도달한다. 이는 매칭이 되었다는 뜻이므로 탐색을 완료해준다.
* 만약 계속 탐색하려면 idx = table[idx]를 해줘서 idx를 다시 돌려주면 된다.

정리
정리하자면 접두사가 일치하는 길이만큼만 j인덱스를 이동시키면 된다.
- j=0, aba (0~2) >> src: aba
ba... <-> find : abac... - c에서 어긋나므로 j = table[j-1] = table[2] =1이므로, b부터 다시 탐색한다
- j=1, (a생략) baca (2~6) len=5 >> src : ababacaba <-> find : abacaaba
- b에서 어긋나므로 j = table[j-1] = table[5] =1 , b부터 다시 탐색한다
- j=6, abacaaba (6~13) len=8
- 일치하므로 종료
KMP 문자열 매칭 알고리즘은 탐색시간을 위와 같은 방식으로 줄여준다. 그래서 시간복잡도도 기존 단순 문자열 매칭 알고리즘은 O(n*m)이지만 KMP는 table생성할 때 반복문 한번, kmp 매칭할 때 한번 해서 O(n+m)으로 굉장히 줄여준다.
KMP 알고리즘 문제 풀어보기
❈ 참고
알고리즘 문제 해결 전략 (종만북)