[Spring] 조회 API 성능 최적화하기 2 - 컬렉션 조회 최적화 : ToMany 매핑
조회 API 성능 최적화하기 2 - 컬렉션 조회 최적화 (ToMany 매핑)
2편은 Order 테이블을 기준으로 ToMany으로 연관관계 매핑되어있는 테이블을 조회할 때 발생하는 N+1문제와 그에 대한 대책에 대해서 다뤄본다. 이전 글에서는 Member와 Delivery에 관한 데이터만 조회를 했기 때문에 fetch join이나 dto 최적화로 가볍게 풀어나갈 수 있었다. 그런데 ToMany 관계를 가지고 있는 테이블과 함께 조회할 경우에는 ToOne 때 했던 방법으로는 쉽게 해결되지 않는다.
- Order을 n개 조회한다고 할 때 이전 글에서 다뤘던 것 처럼 ToOne으로 매핑되어 있는 Member와 Delivery는 fetch join으로 묶어서 조회해주면 된다.
- 그런데 ToMany 매핑은 fetch join을 하면 안된다(이유는 본문에서). 그래서 ToMany 매핑부분은 엔티티를 hibernate에서 제공하는 fetch_batch_size로 N개의 쿼리 발생을 1개로 묶은 다음 Dto로 내보내는 방식을 사용할 수 있고 처음부터 Dto에 맞춘 최적의 쿼리를 만들어 조회하는 방식 등을 사용한다.

조회 API 최적화 1에서는 XtoOne (OneToOne, ManyToOne)관계만 있었다. 이번에는 컬렉션이 일대다 관계(OneToMany)를 조회하고 최적화는 방법을 알아보자.
- Order - OrderItem (1:N)
- OrderItem - Item (N:1)
Order.java
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List<OrderItem> orderItems = new ArrayList<>();
OrderItem.java
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "item_id")
private Item item;
주문 조회 V1: 엔티티 직접 노출
주문내역에서 추가로 주문한 상품 정보를 추가로 조회하자. Order 기준으로 컬렉션인 OrderItem과 Item이 필요하다.
OrderApiController.java
// hibernate5Module을 이용해 Lazy 프록시 객체 강제 초기화
@GetMapping("/api/v1/orders")
public List<Order> ordersV1(){
List<Order> all = orderRepository.findAll(new OrderSearch());
for (Order order : all) {
order.getMember().getName();
order.getDelivery().getAddress();
List<OrderItem> orderItems = order.getOrderItems();
orderItems.stream().forEach(o -> o.getItem().getName());
}
return all;
}
데이터 조회 결과는 다음과 같다.

조회 API 최적화 1- 지연 로딩과 페치 조인 V1과 동일한 문제가 있다. 엔티티를 직접 노출하고 모든 데이터를 조회해야 하는 것은 좋지않다.
- orderItem, item 관계를 직접 강제 초기화하면 Hibernate5Module설정에 의해 엔티티를 JSON으로 설정한다. (조회 API 최적화 1- 지연 로딩과 페치 조인 V1과 동일)
- 양방향 연관관계면 무한 루프에 걸리지 않게 한곳에 @JsonIgnore를 추가해야 한다. (그런데 @JsonIgore 사용은 웬만하면 지양되어야 한다. 직렬화도 안되고 나중에 코드 읽기도 헷갈려서 유지보수면에서 불리하고 엔티티를 그대로 노출하는 부담도 있기 때문이다. DTO 사용 권장!)
- 엔티티를 직접 노출하므로 좋은 방법은 아니다.
주문 조회 V2: 엔티티를 DTO로 변환
OrderItem과 Item 엔티티 모두 DTO로 변환하여 원하는 데이터만 조회해보자.
OrderApiController.java
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2(){
List<Order> orders = orderRepository.findAll(new OrderSearch());
List<OrderDto> collect = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return collect;
}
//...
@Data
static class OrderDto{
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemDto> orderItems; // new! OrderItem도 꼭 Dto로 받아야 함
public OrderDto(Order order) {
orderId = order.getId();
name = order.getMember().getName();
orderDate = order.getOrderDate();
orderStatus = order.getStatus();
address = order.getDelivery().getAddress();
orderItems = order.getOrderItems().stream()
.map(orderItem -> new OrderItemDto(orderItem))
.collect(toList());
}
}
@Data
static class OrderItemDto{
private String itemName; // 상품명
private int orderPrice; // 주문 가격
private int count; // 주문 수량
public OrderItemDto(OrderItem orderItem) {
itemName = orderItem.getItem().getName();
orderPrice = orderItem.getOrderPrice();
count = orderItem.getCount();
}
}
데이터 조회 결과는 다음과 같다.

문제 발생 (N+1 문제)
데이터 조회 결과는 깔끔해졌지만 지연 로딩으로 너무 많은 SQL이 실행된다. N+1문제가 발생되는 것이다.
- SQL 실행 수
- order n개 조회 - 쿼리 1번
- member, delivery, orderItem N번(order 조회 수 만큼) - 쿼리 n*3번
- item M번(orderItem 조회 수 만큼) - 쿼리 m번
- order n개 조회 - 쿼리 1번
- 총 1 + 3*N + M = 1 + 3*2 + 2*2 = 11번 실행된다.
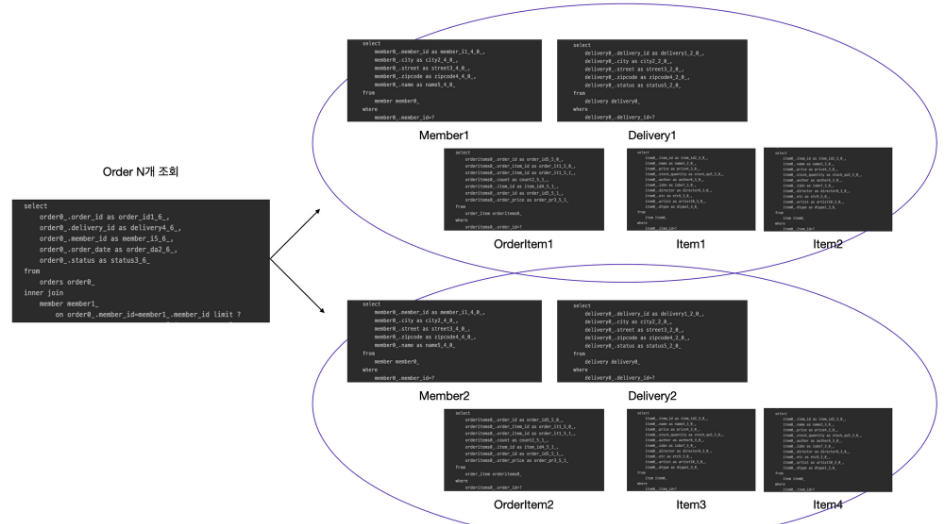
수많은 네트워크가 오가는 실무에서 이러한 N+1가 발생하면 성능 저하가 발생한다. 따라서 이러한 성능 문제를 해결하기 위해서 페치 조인 최적화 작업이 필요하다.
주문 조회 V3: 엔티티를 DTO로 변환 - 페치 조인 최적화
조회하는 엔티티에 페치 조인(Fetch Join)을 사용해서 쿼리 1번에 조회해보자.
OrderApiController.java
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3(){
List<Order> orders = orderRepository.findAllWithItem();
List<OrderDto> collect = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return collect;
}
OrderRepository.java
public List<Order> findAllWithItem() {
return em.createQuery(
"select distinct o from Order o" +
" join fetch o.member m"+ // toOne
" join fetch o.delivery d"+ // toOne
" join fetch o.orderItems oi"+
" join fetch oi.item i", Order.class)
.getResultList();
}
데이터 조회 결과는 V2와 같다. 실행된 SQL을 보면 페치 조인으로 쿼리가 1번만 실행되는 것을 확인할 수 있다.
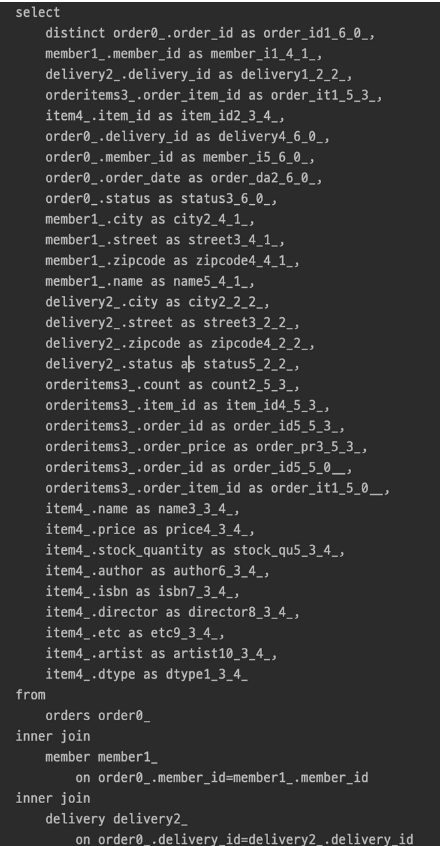
distinct
distinct 를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가한다. 그 결과 같은 order 엔티티의 조회 수도 증가하게 된다. JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러준다. 이 예에서 order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다.
distinct X

distinct O

DB 데이터
그러나 DB에서는 Distinct를 해도 중복된 데이터가 압축이 되지 않는 문제가 아직 남아있다.

문제 발생 (DB 데이터는 distinct 압축 불가능)
toOne관계는 패치조인 해도 데이터 뻥튀기되지 않지만, toMany관계는 패치조인하면 위에서 봤던 것처럼 데이터가 뻥튀기 된다. (2개 → 4개)
- 그래서 JPA의 distinct를 사용하여 애플리케이션 레벨까지는 최적화가 가능하지만 DB의 성능까지는 최적화가 불가능하다.
페이징 불가
이러한 문제로 인해 발생하는 치명적인 단점이 있다. 컬렉션 페치 조인을 사용하면 페이징이 불가능하다. Hibernate는 경고 로그를 남기면서 모든 데이터를 DB에서 읽어오고, 메모리에서 페이징 해버린다(매우 위험하다).

이렇게 동작하는 이유는 클라이언트가 기대하는 Order는 2개이지만 DB에서는 4개가 생성된다. 그래서 DB에서 페이징 조회를 하면 원하는 데이터가 반환되지 않기 때문에 경고 메세지와 함께 메모리에서 조회하는 것이다.
컬렉션 페치 조인 (toMany)은 1개만 사용하자
- 컬렉션 페치 조인은 1개만 사용할 수 있다. 컬렉션 둘 이상에 페치 조인을 사용하면 안된다. 데이터가 부정합하게 조회될 수 있다.
- 1개의 1대N 컬렉션 페치조인도 위와 같이 N의 갯수만큼 비례하여 데이터의 크기가 커진다.
- 여러 개의 컬렉션에 패치조인을 하게 되면 데이터 크기가 NM···만큼 늘어나게 된다.
- 자세한 내용은 자바 ORP 표준 JPA 프로그래밍을 참고하자.
정리
- 컬렉션을 페치 조인하면 일대다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
- 일다대에서 일(1)을 기준으로 페이징을 하는 것이 목적이다. 그런데 데이터는 다(N)를 기준으로 row가 생성된다.
- Order를 기준으로 페이징 하고 싶은데, 다(N)인 OrderItem을 조인하면 OrderItem이 기준이 되어버린다.
- 이 경우 하이버네이트는 경고 로그를 남기고 모든 DB 데이터를 읽어서 메모리에서 페이징을 시도한다. 최악의 경우 장애로 이어질 수 있다.
주문 조회 V3.1: 엔티티를 DTO로 변환 - 페이징과 한계 돌파
페이징 + 컬렉션 엔티티를 함께 조회할 수 있는 코드도 단순하고, 성능 최적화도 보장하는 매우 강력한 방법이 있다. 대부분의 페이징 + 컬렉션 엔티티 조회 문제는 이 방법으로 해결할 수 있다.
- 먼저 ToOne(OneToOne, ManyToOne) 관계를 모두 페치조인 한다. ToOne 관계는 row수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다.
- 컬렉션은 지연 로딩으로 조회한다.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size , @BatchSize 를 적용한다.
- hibernate.default_batch_fetch_size: 글로벌 설정
- @BatchSize: 개별 최적화
- 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
OrderApiController.java
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_page(
@RequestParam(value ="offset", defaultValue = "0")int offset,
@RequestParam(value ="limit", defaultValue = "100")int limit){
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset, limit);
List<OrderDto> collect = orders.stream()
.map(o -> new OrderDto(o))
.collect(toList());
return collect;
}
OrderRepository.java
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery(
"select o from Order o" +
" join fetch o.member m"+
" join fetch o.delivery d", Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
application.yml
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 1000- 개별로 설정하려면 @BatchSize 를 적용하면 된다. (컬렉션은 컬렉션 필드에, 엔티티는 엔티티 클래스에 적용)
쿼리 발생횟수
batch를 적용하기 전에는 다음과 같다.
- Order,member,delivery 페치조인한 쿼리 1개
- OrderItem 2개
- Iterm 4개
→ 총 1+N+M = 7개의 쿼리가 발생한다.
batch를 적용하고 나면 다음과 같다.
- Order,member,delivery 페치조인한 쿼리 1개
- OrderItem 1개(묶음)
- Item 1개(묶음)
→ 총 1+1+1 = 3개의 쿼리가 발생한다.
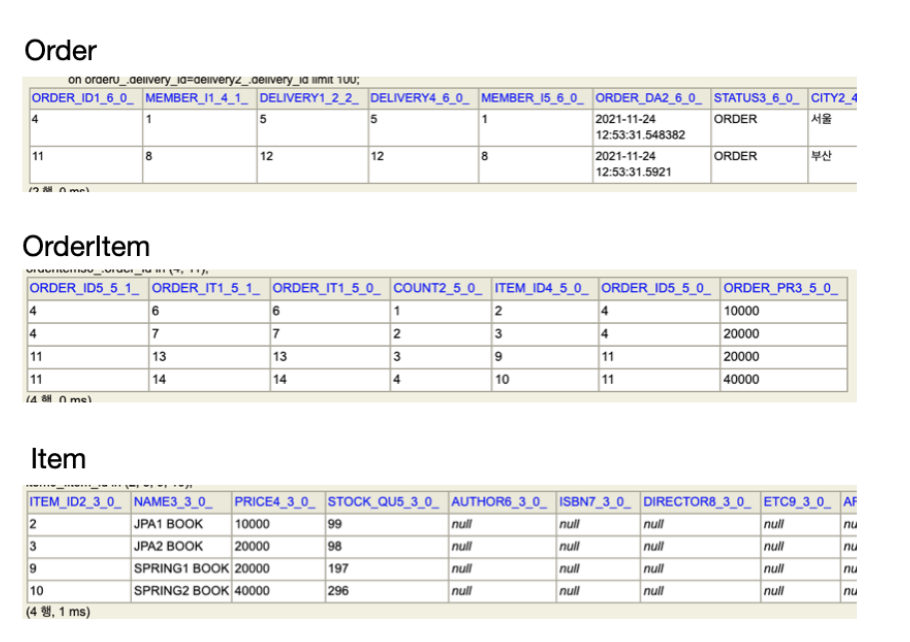
DB 데이터 최적화
3개의 쿼리를 조회해보면 V3에서 보였던 중복된 데이터를 압축시켜진 것을 확인할 수 있다.
장점
- 쿼리호출수가 1+N → 1+1로최적화된다.
- 조인보다 DB 데이터 전송량이 최적화 된다. (Order와 OrderItem을 조인하면 Order가 OrderItem 만큼 중복해서 조회된다. 이 방법은 각각 조회하므로 전송해야 할 중복 데이터가 없다.)
- 페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 데이터 전송량이 감소한다.
- 컬렉션 페치 조인은 페이징이 불가능 하지만 이 방법은 페이징이 가능하다. 이게 가장 큰 장점이다.
결론
- ToOne 관계는 페치 조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이고 해결하고, 나머지는 hibernate.default_batch_fetch_size 로 최적화 하자.
- default_batch_fetch_size 의 크기는 적당한 사이즈를 골라야 하는데, 100~1000 사이를 선택하는 것을 권장한다.
- 이 전략을 SQL IN 절을 사용하는데, 데이터베이스에 따라 IN 절 파라미터를 1000으로 제한하기도 한다. 1000으로 잡으면 한번에 1000개를 DB에서 애플리케이션에 불러오므로 DB 에 순간 부하가 증가할 수 있다.
- 하지만 애플리케이션은 100이든 1000이든 결국 전체 데이터를 로딩해야 하므로 메모리 사용량이 같다. 1000으로 설정하는 것이 성능상 가장 좋지만, 결국 DB든 애플리케이션이든 순간 부하를 어디까지 견딜 수 있는지로 결정하면 된다.
→ 조회 성능 최적화가 V3.1까지 이루어진다면 90%정도는 다 해결이 된다.
주문 조회 V4: JPA에서 DTO 직접 조회
컬렉션(1대다)을 포함한 데이터를 JPA에서 DTO로 직접 조회해보자.
OrderApiController.java
@GetMapping("/api/v4/orders")
public List<OrderQueryDto> ordersV4(){
return orderQueryRepository.findOrderQueryDtos();
}
OrderQueryRepository.java
package jpabook.jpashop.repository.order.query;
//...
public List<OrderQueryDto> findOrderQueryDtos() {
List<OrderQueryDto> result = findOrders(); // query 1번 -> N개
result.forEach(o -> {
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId()); // query N번 실행
o.setOrderItems(orderItems);
});
return result;
}
private List<OrderQueryDto> findOrders() {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)" +
" from Order o"+
" join o.member m"+
" join o.delivery d", OrderQueryDto.class)
.getResultList();
}
private List<OrderItemQueryDto> findOrderItems(Long orderId) {
return em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
" from OrderItem oi"+
" join oi.item i"+
" where oi.order.id = :orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getResultList();
}
OrderQueryDto.java
package jpabook.jpashop.repository.order.query;
@Data
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
}
}
OrderItemQueryDto.java
package jpabook.jpashop.repository.order.query;
@Data
public class OrderItemQueryDto {
private Long orderId;
private String itemName;
private int orderPrice;
private int count;
public OrderItemQueryDto(Long orderId, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}
조회한 데이터 결과는 다음과 같다.

ToOne(N:1, 1:1) 관계들을 먼저 조회하고, ToMany(1:N) 관계는 각각 별도로 처리한다. 이런 방식을 선택한 이유는 다음과 같다.
- ToOne 관계는 조인해도 데이터 row 수가 증가하지 않는다.
- ToMany(1:N) 관계는 조인하면 row 수가 증가한다.
row 수가 증가하지 않는 ToOne 관계는 조인으로 최적화 하기 쉬우므로 한번에 조회하고, ToMany 관계는 최적화 하기 어려우므로 findOrderItems() 같은 별도의 메서드로 조회한다.
N+1 문제
그러나 해당 방법은 N+1 문제가 발생한다.
- Query: 루트 1번, 컬렉션 N 번 실행
- Order,Member,Delivery 쿼리 1개
- OrderItem, Item 쿼리 N개
→ 총 1+N = 3개의 쿼리가 발생한다.
주문 조회 V5: JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
N+1문제를 해결하기 위해 컬렉션 조회 최적화를 해보자. ToOne 관계들을 먼저 조회하고 여기서 얻은 식별자 orderId로 ToMany 관계인 OrderItem 을 한꺼번에 조회해주면 된다.
- Order 조회 (orderId 획득)
- orderId → OrderItem 한꺼번에 조회
OrderApiController.java
@GetMapping("/api/v5/orders")
public List<OrderQueryDto> ordersV5(){
return orderQueryRepository.findAllByDto_optimization();
}
OrederQueryRepository.java
package jpabook.jpashop.repository.order.query;
public List<OrderQueryDto> findAllByDto_optimization() {
List<OrderQueryDto> result = findOrders(); // query 1번
List<Long> orderIds = result.stream()
.map(o -> o.getOrderId())
.collect(Collectors.toList()); // orderId뽑힘 (2개)
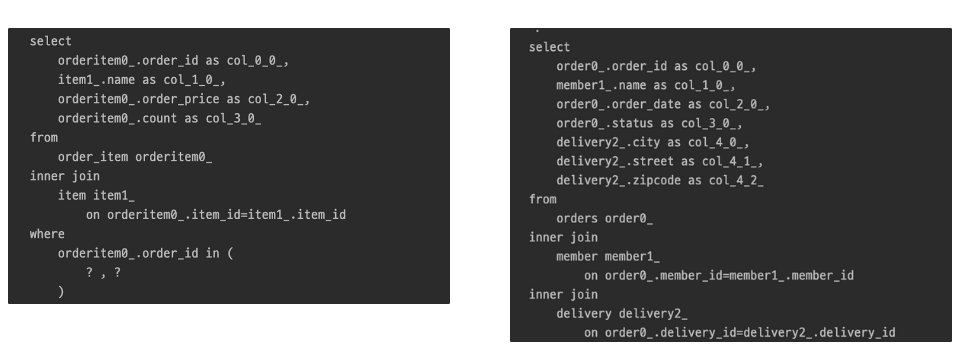
// query 1번 - forEach를 in절을 사용해서 한 번에 다 뽑음
List<OrderItemQueryDto> orderItems = em.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id, i.name, oi.orderPrice, oi.count) " +
" from OrderItem oi" +
" join oi.item i" +
" where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
// Map자료구조 <orderId, List(OrderItems) >로 grouping
Map<Long, List<OrderItemQueryDto>> orderItemMap = orderItems.stream()
.collect(Collectors.groupingBy(orderItemQueryDto -> orderItemQueryDto.getOrderId()));
// 최종적으로 result에 orderId가 일치하도록 OrderItem 삽입
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId())));
return result;
}
해당 방식으로 최적화를 이루게 되면 루트 1번, 컬렉션 1번 총 2개의 쿼리가 발생한다. MAP 자료구조를 사용해서 매칭 성능이 (O(1))으로 향상된다
- Order 1개, OrderItem 1개 = 2개
주문 조회 V6: JPA에서 DTO 직접 조회 - 플랫 데이터 최적화
V5에서 더 최적화하여 쿼리 1개로 해결되는 방법을 알아보자.
OrderApiController.java
@GetMapping("/api/v6/orders")
public List<OrderQueryDto> ordersV6(){
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(), o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(), o.getItemName(), o.getOrderPrice(), o.getCount()),toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(), e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(), e.getKey().getAddress(), e.getValue()))
.collect(toList());
}
OrederQueryRepository.java
package jpabook.jpashop.repository.order.query;
public List<OrderFlatDto> findAllByDto_flat() {
return em.createQuery(
"select new "+
" jpabook.jpashop.repository.order.query.OrderFlatDto(o.id, m.name, o.orderDate, o.status, d.address, i.name, oi.orderPrice, oi.count)"+
" from Order o"+
" join o.member m"+
" join o.delivery d" +
" join o.orderItems oi"+
" join oi.item i", OrderFlatDto.class)
.getResultList();
}
OrderQueryDto.java
package jpabook.jpashop.repository.order.query;
@Data
@EqualsAndHashCode(of = "orderId") // groupingBy 기준 명시
public class OrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private List<OrderItemQueryDto> orderItems;
public OrderQueryDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, List<OrderItemQueryDto> orderItems) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.orderItems = orderItems;
}
}
OrderFlatDto.java
package jpabook.jpashop.repository.order.query;
@Data
public class OrderFlatDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
private String itemName;
private int orderPrice;
private int count;
public OrderFlatDto(Long orderId, String name, LocalDateTime orderDate, OrderStatus orderStatus, Address address, String itemName, int orderPrice, int count) {
this.orderId = orderId;
this.name = name;
this.orderDate = orderDate;
this.orderStatus = orderStatus;
this.address = address;
this.itemName = itemName;
this.orderPrice = orderPrice;
this.count = count;
}
}
다음과 같이 쿼리를 1개만 전송하여 극한의 최적화를 이루어진 것을 볼 수 있다.
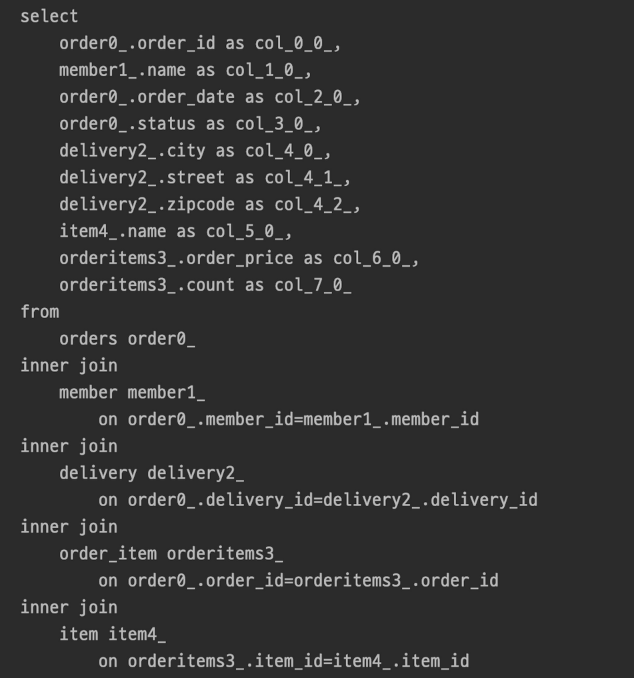
쿼리가 1번만 발생하는 장점이 있지만 역시나 트레이드 오프가 존재한다. 1대다 조인을 했기 때문에 DB에 중복된 데이터 존재하게 되기 때문에 페이징이 불가능하다.
- 해당 데이터는 OrderItem을 기준으로 정렬되어 있기 때문에 Order를 조회하여 페이징을 하려고 하면 원하지않는 데이터가 나오게 된다.
- 1~2를 페이징하려고 하면 order (1,2)를 출력해야 하는데 아래의 데이터는 oredrItem (1,2)를 출력하게 된다.

정리
- 쿼리는 한번이지만 조인으로 인해 DB에서 애플리케이션에 전달하는 데이터에 중복 데이터가 추가되므로 상황에 따라 V5 보다 더 느릴 수 도 있다. (그러나 이러한 경우는 별로 없다.)
- 작성된 코드를 보면 알 수 있겠지만 애플리케이션에서 추가 작업이 크다.
- 페이징이 불가능하다.
[Spring] 조회 API 성능 최적화하기 1 - 지연로딩(Lazy Loading)과 페치 조인(Fetch Join)
[Spring] 조회 API 성능 최적화하기 2 - 컬렉션 조회 최적화 (1:N)
※ 참고
실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화