Facebook 소프트웨어 엔지니어와의 Google 코딩 인터뷰 (번역)
Facebook 소프트웨어 엔지니어와의 Google 코딩 인터뷰 (번역)
갑자기 알고리즘으로 떠서 보게 되었는데 너무 재밌고 도움이 되는 컨텐츠 같아서 저녁에 심심찮게 번역해보았다. 영어 공부하면서 배우는 입장이라 오역, 오타가 많다... 이를 보고 번역해보면서 영어 회화랑 컴퓨팅 사고, 문제 해결 능력을 배울 수 있어서 좋았다.
원본 영상 링크: https://youtu.be/PIeiiceWe_w

문제 해결하기(45분)
A: 출제자, B: 인터뷰 대상자
1:36 시작
A: 지금 당장 당신의 폰을 꺼내보세요. 아이폰이든지 안드로이드이든지 상관없어요. 그런 다음 폰에 있는 키패드를 한 번 봐보세요. 보면 다음 그림과 같은 것을 볼 수 있을거에요. 1과 0을 제외한 2~9까지 각 알파벳 3개씩 포함되어 있어요. 예전 폰부터 최신 폰까지 흔하게 사용되는 방식이죠. 이러한 방식이 흔한 이유는 전화번호를 영어와 같은 언어로 읽을 수 있게 해주기 때문이죠.
| 1 | 2 abc |
3 def |
| 4 ghi |
5 jkl |
6 mno |
| 7 pqrs |
8 tuv |
9 wxyz |
| 0 |
들어봤을지는 모르겠지만 1 (800) flowers 라는 회사가 있습니다. 이 회사의 이름은 사실 폰 번호이기도 한데요. 폰 번호는 1 (800) 3569377 이에요. 매핑과 같이 3569377 → flowers 로 표현된 것이죠. 이해가 되시나요?
B: Yeah
A: 여기서 제가 말하려는 요점은 이런 숫자 키패드가 있으면 다른 문자로 표현할 수 있다는 것입니다. 다른 예시도 들어볼게요. 253 6368 → clement 또는 clemdot 또는 ... 등 여러 문자가 만들어질 수 있습니다.
이제 2개의 입력을 필요로 하는 알고리즘이나 함수를 작성해주세요. 입력으로는 문자열로 표현된 전화번호(phoneNumber)와 단어 목록(words)이 주어집니다. 입력 샘플을 지금 줄게요.
당신의 알고리즘이 이 리스트에 있는 단어 중 전화번호에 포함된 단어를 골라내야 합니다. 저 위에 있는 예시 전화번호가 "flowers"에 포함되어 있다는 것과 비슷합니다. 따라서 이 특정 입력에 대해 다음 결과(output)을 반환합니다. 이 ouput들은 phoneNumber에 포함되어 있는 것들입니다.
phoneNumber = "3662277"
words = ["foo", "bar", "baz", "foobar", "emo", "cap", "car", "cat"]
output = ["bar", "cap", "car", "emo", "foo", "foobar"]
B: phoneNumber 아무 곳에나 속해있는 단어를 찾으면 되는거죠?
A: 네 anywhere in the phoneNumber .
B: 음. phoneNumber 속해있는 부분 문자열을 찾으면 되는거죠? 연속된?
A: yes, 'continous'가 키워드입니다.
B: 아아 이해했어요. 재밌네요. 가장 먼저 해야할 작업은 단순화 작업인 것 같네요.
A: Ok
B: 우리는 지금 words에 포함된 단어들이 번호와 일치하는지 알아보려고 해요. 음... 아마 각 문자들을 일치하는 해당 번호로 바꾸면 풀이가 쉬워질 것 같네요. 음 첫번째 인스턴스 366은 많은 단어 뭉치를 들고 있겠죠. 그런데 내가 만약 "foo"라는 인스턴스를 들고 찾는다면 더 쉬워질거에요. 음 (foo는) 366 네요! 그럼 phoneNumber을 들고 찾는 것보다는 words 배열에 속한 각 단어를 대상으로 찾는 게 좋겠네요. 'foo => 366' 이렇게요. 이젠 phoneNumber의 substring에서 "366"이 있는지 확인하면 되겠네요. 입력으로 주어진 모든 단어들도 마찬가지로요. 그러면 각 단어들을 살펴볼 수 있겠죠.
음.. 한편으로는 아호-코라식 알고리즘을 사용해서 풀어볼 수 있을 것 같네요. 그러나 음... 그렇게까지 필요할 것 같지는 않네요.
음... 질문 하나만 할게요. phoneNumber가 특정 길이를 갖고 있나요? 아니면 정말 긴 길이를 가질 수 있나요? 아니면 그냥 일반 폰 번호 정도의 길이(7 정도)만 가정하고 풀어도 될까요?
A: 폰 번호 길이는 딱히 정해져 있지 않아요. 연속적인 숫자로 보면 됩니다. 음 그러나 너무 긴 길이까지는 고려하지 않아도 돼요. 7개 숫자를 가진 번호가 될 수도 있고 15개의 숫자를 가진 번호가 될 수도 있어요. 그러나 너무 큰 범위까지는 고려하지 마세요.
B: 음 그럼 제가 갖고있던 하나의 솔루션은 phoneNumber가 가질 수 있는 연속된 길이를 모두 탐색하여 찾는 방식을 사용하려고 했는데 이건 안되겠네요. 이 방식은 최종 런타임 시간복잡도가 O(phoneNumberLength ^ 2)이거든요. 음 아이디어 속에는 phoneNumber의 연속된 범위 내에서 어떤 대표되는 단어(some representation)을 찾을 수 있다는 것인데요. 만약 phoneNumber의 모든 시작점과 끝점을 고려해야 한다면, 음 아마 큰 값을 가지게 될 것 같네요.
역주) 말 그대로 이중 포문 탐색입니다.
/**
* 문자열 길이 n
* n + n-1 + ··· + 1 -> O(n^2)
*/
for(int i=0; i<phoneNumber.length(); i++) {
for(int j=i+1; j<=phoneNumber.length(); j++) {
System.out.println(phoneNumber.substring(i, j));
}
}
음... 하지만 그에 대한 대책으로 어떠한 값을 다른 어떠한 값으로 압축하여 사용하는 방법이 생각나는데요. 문자열 중 일부분이 다른 문자열과 일치한다면요. "string hash"라고 불리는 기법입니다. 음 이게 좋은 해결책이라면 이 방향으로 갈 거 같아요. (오타 고치기) 오케이. 이게 제가 시도할 수 있는 하나의 방법이고요.
(역주) string hash로 반복되는 문자열은 빠르게 탐색하는 기법을 사용하려는 것 같습니다. hash의 탐색 시간은 O(1)이기 때문입니다.
"foo" → hash(foo)
"foobar" → hash(foo) + "bar"
다른 방법으로는 만약 제가 모든 word들이 작은 길이들로 연관되어 있다는 것을 알고있다면 해당 부분 문자열만 고려해볼 수 있겠네요. 그리고 모든 word들이 슈퍼 롱하지 않는 것 또한 알고있다면 해당 부분 문자열의 길이만 체크해서 O((#different word lengths) * (length of phone number)) 시간 안에 처리할 수 있겠네요.
A: word들에 대해 다음과 같이 가정해볼게요. 이들의 길이는 1이상이고 값이 비어있을 수 없고요. 최대 전화번호 길이를 갖고 있습니다.
B: 끄적끄적...
word lengths { 1 ... length of phone number }
okay. 좋은 부분을 잘 짚어주셨네요. 그럼 다시 고려해보면 위의 솔루션은 별로 쓸모가 없겠네요. 위에 있는 O(phoneNumberLength ^ 2)과 같아지겠어요.
역주) 질문자(A)는 조건으로 word의 길이가 다양하게 분포되어 있다는 점을 새롭게 제시하였습니다. 그래서 답변자(B)는 수 많은 문자열을 탐색을 하기 위해서 결국 해싱으로 시간을 단축시키는 방법이나 중복되는 문자열은 제외시키는 방법에는 한계가 있다는 이야기인 것 같습니다.
음... 여기서 아호 코라식을 여기서 사용해보면 어떨까요. 그럼 우리는 기본적으로 trie 자료구조를 생각해볼 수 있겠네요. 그리고 trie 자료구조는 words의 모든 단어들로 구성되어 있고요.
역주) 이 부분부터는 아호코라식, 트라이, kmp 알고리즘에 대한 선수 지식이 필요한 영역입니다...아호 코라식 알고리즘은 백준 기준 플레 1~2부터 어렵게는 다아이 정도의 난이도를 가지는 문자열 검색 알고리즘입니다. 솔직히 저도 공부는 했지만 인터뷰에서 이렇게 논리 정연하게 설명하지는 못할 것 같습니다. 아호-코라식을 먼저 알고 싶은 분은 여기를 참고해주세요.
A: okay. (당황)
B: (아호코라식에 대해 설명 중. 발 번역 시작) 제가 알아내고 싶은 것은 각 단어들의 접두사(prefix)입니다. 그리고 그 접두사들의 접미사를 알아내볼게요. 거기서 가장 긴 접미사들은 트라이의 일부 경로로 존재하거든요. 그런 다음 그들은 모두 되돌아가는 link를 갖게 되는데요. 음... 세부사항이 복잡한데요. 우리는 이들이 link를 통해 실제로 어디로 가는지 알 수 있을 거에요. 그런 다음 또 어디로 가는지 몇 가지 단계를 수행할 수 있습니다. up up 계속 위로 반복해서요. 그러면 이젠 trie 자료구조에 words에 있는 다양한 단어를 모두 표시할 수 있습니다.
그래서 솔루션으로 고려할 수 있는 경로는
1. 이젠 제가 직접 모든 words를 고려하여 trie를 설계하고요
2. 그 다음 각 trie에 있는 노드에 link를 연결할게요. 숫자는 총 10개가 있죠. 그래서 저는 26개(알파벳 개수)의 link를 만들지는 않을게요. 이 link들은 모든 도달가능한 노드에 연결이 될 거에요.
A: david, 잠시만 멈춰봐요. 지금 trie에 모든 word를 넣는다는 게 words에 있는 string 포맷인가요? 아니면 digit으로된 string인가요?
B: um, digit으로 된 string을 저장할거에요. 먼저 저는 words에 있는 모든 단어들을 digit으로 변경할 거에요. 그러면 저는 digit string 덩어리들을 많이 갖게 될 거에요. 그런 다음 digit string이 trie에서 매칭된다면 digit에 대한 string이 일치하는지 다시 한 번 확인할 거에요.
역주) 정리하면 이러한 과정인 것 같습니다.
1. foo → 366 이를 trie에 저장
2. phoneNumeber 탐색 도중 366과 매칭
3. 366 → word "foo"와 일치하는지 다시 검증
A: 갓챠
B: um okay. 그림으로 예시를 그려보면서 하는 게 저에게 도움이 될 것 같네요. 기억을 되살리기 위해서요. 사실 아호-코라식 알고리즘을 써본지 꽤 됐거든요.
A: okay. 그런데 전 그게 뭔지 몰라요. 아호-코라식이 뭔지 저에게 설명좀 해줘요. 트라이까지는 이해를 했는데 word, name 이런 것들에 대해서는 아직 이해하지 못했어요.
B: okay yeah... 기존에 냈던 아이디어로 설명할 수 있겠네요. 만약 O(n^2)의 풀이를 기대했다면 저는 그 방식으로 써내려갈 수 있어요. 그 말은 즉슨, 지금 제가 푸려는 방식은 선형 시간 풀이 방법과는 완전히 다르다는 이야기입니다. 그래서 제가 그 부분에서 고민을 해야했구요. 그래서 만약 선형 방식이 당신이 의도했던 경로였다면 O(n^2) 길로 가는 게 맞을 것 같고요. 지금 제가 가려는 아호-코라식은 이 선형 풀이와는 전혀 관련이 없습니다. 음 아호 코라식은 뭐냐햐면은요. trie를 캐치하셨다고 하셨죠. 몇 개의 단어들을 만들어볼게요.
bat
at
att
aat
그러면 trie는 이렇게 만들어지겠죠. 구분하기 쉽게 '.' 노드를 넣을게요 ... (생략) 단어가 끝나는 부분 엔드 노드는 볼드, 밑줄 처리를 할게요.
역주) 다음 그림과 같습니다.
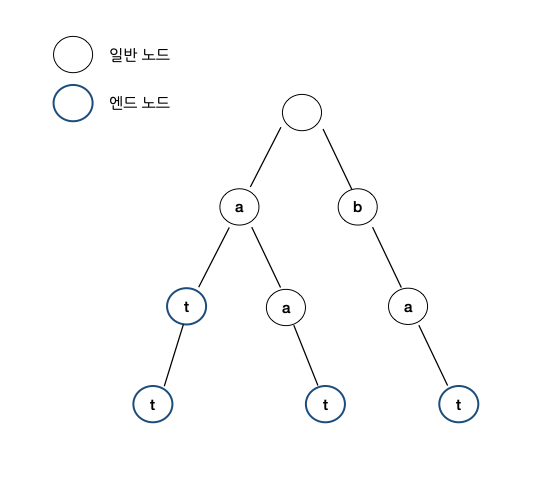
B: trie는 이러한 형태를 가지게 될 거에요. 여기서 아호-코라식은 우리가 아주 긴 문자열을 탐색하고자할 때. 오. 그냥 한 번 몇 개의 단어들로 예시를 만들어볼게요. 진짜 예시처럼 문자 대신 digit을 사용해서요. 그런데 아마 많이 다를 수도 있을거에요.
A: 괜찮아요.
B: 만약 우리가 "atbat" 이렇게 생긴 문자열을 통해 무언가를 찾는다고 해볼게요. 그러면 먼저 우리는 여기서 가능한 모든 접두사(prefix)를 구하는 거에요. [a, at, atb, ···] 이렇게 되겠죠. 각 접두사들이 Trie에 최대한 있기를 바래야겠죠.
- 이 경우에는 두 번째 접두사인 "at"를 Trie를 타고 들어가보면 a → t를 통해 구할 수 있어요. 접두사의 길이는 2이죠.
- 다음으로는 b가 오는데요. 사실 우린 지금 "t"노드에서 "b"의 노드로 이동할 수 없죠.
- 그래서 우리는 "t" 노드에 있는 실패 링크(failure link)타고 움직여야 해요. 음 다음 문자가 "b"가 되는 곳으로요.
- "tb"라는 접미사가 있는 곳을 찾아요. 만약 이 Trie 어딘가에 그러한 접미사가 존재한다면 저희는 그 "tb"로 이동을 해요. 지금 Trie에는 없어서 가질 못하겠네요.
- 그러면 다음으로는 "b"를 찾아요. 이 Trie에 "b"를 들고있는 노드는 존재하죠. 해당 노드에 위치하게 될거에요
- 그 다음으로 "a"를 읽어요. 음 현재 저희가 있는 노드를 따라가보면 "a" 노드를 찾을 수 있네요.
- 그 다음 "t"를 읽고 마찬가지로 다음 노드에 위치하므로 b → a → t 이렇게 이동해서 "bat"라는 단어를 찾게 돼요
역주) 그래서 지금 "atbat"를 읽어나가면서 word 더미들로 이뤄진 Trie에 해당 노드들이 속해있는지 탐색 과정을 보여준 것입니다. 그렇게 해서 찾은 더미들은 총 2개로 "at", "bat"입니다. 실제로 words = ["bat", "at", "att", "aat"]를 비교해보면 올바르게 탐색한 것을 알 수 있습니다.
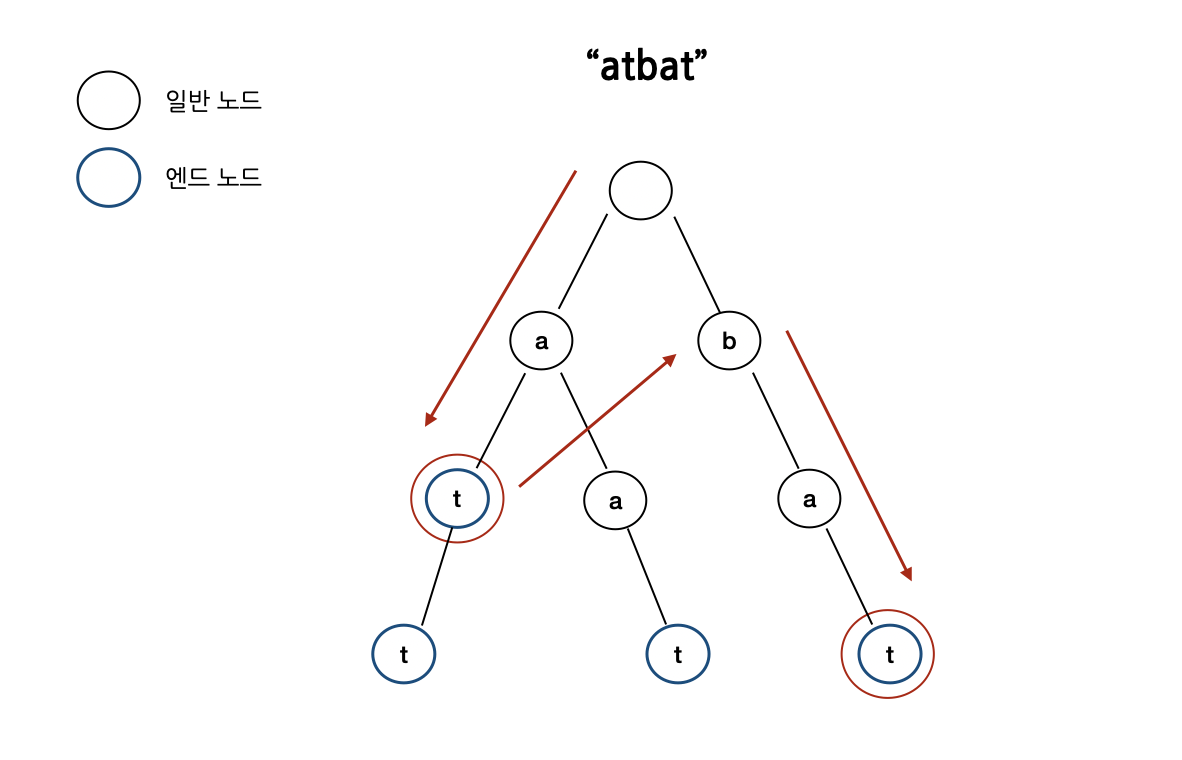
역주) 정리하면, "atbat"를 순차적으로 읽어나가면서 트라이 노드에 해당 노드와 일치하는 것을 찾고 해당 노드가 터미널 노드(엔드 노드)일 경우, output으로 포함되게 되는 것입니다.
B: 트라이에 있는 각 노드에서 만약 우리가 찾고자하는 노드에 도달할 수 없다면 다른 노드로 되돌아가게 돼요. 일치하는 접미사를 찾을 때까지 계속해서 올라가는 거죠. 그렇게 올라가면서 trie에서 가장 빠르게 탐색되는 노드가 가장 최적의 탐색 노드가 되는 것이겠죠.
이 경우에서는 우린 "att" 를 가지고 있고 그것의 접미사가 될 무언가를 원한다고 하면, 그래프에는 존재하지 않지만 그것은 "tt"가 되겠죠.
um, 더 좋은 예시를 들어볼게요. bat에서 t를 더 붙인 "batt".
- 우리가 "bat"를 읽으면 우리는 현재 이 노드("t"노드)에 있을 거에요.
- 그런 다음 두 번째 "t"를 읽을 때, 우리는 음 다음 노드에 "t"로 표시된 노드가 없네요.
- 그럼 이제 우리는 마지막이 "t"로 되는 노드를 찾아야 합니다.
- 이를 위해서 가장 빠르게 도달하는 fail link를 찾아야 합니다. 지금 접미사 "at"인데요. "at" 접미사가 다른 곳에도 위치(왼쪽에 있는 노드)하고 있죠. 그래서 우리는 이 중간에 위치한 노드들(b, a)를 점프하고 "t" 노드에 위치하게 됩니다.
- 그래서 밑으로 내려가서 "t"를 또 찾아 내려가서 해당 노드에서 끝나게 되는거죠.
역주) "batt"를 새롭게 예시로 들면서 failure link 탐색 과정에 대해 더 자세한 설명을 추가해줬습니다. "batt"를 탐색하면서 총 "bat", "at", "att"의 더미들을 찾는 과정입니다.
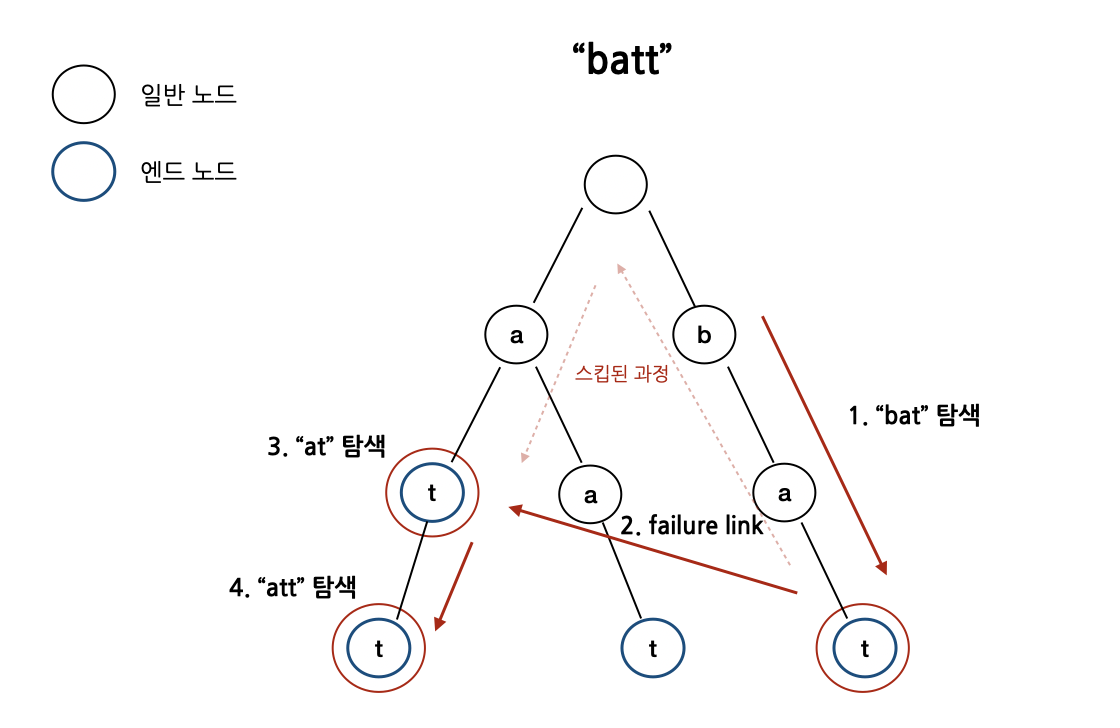
이렇게 기본적으로 여러 단계를 밞으면서 알려줍니다. 어떤 트라이 노드를 hit 했는지.
A: 재밌네요. "batt"를 예로 들면서 최적화를 이뤄냈네요. 여기 "t"에 도달하고 나서 두 번째 "t"가 보이지 않는다면 여기 "at"가 있는 곳으로 뒤로 점프해서 돌아갈 수 있고요. 여기서 "att"를 찾아내고요. 이러한 부분에서 최적화를 이뤄내는 거죠. 맞나요?
B: 예 맞아요. 그 부분 탐색이 O(1) 이고요. 해당 노드에서 "t"를 읽고 다음 노드에 있는 "t"까지 읽을 수 있게 됩니다.
A: 갓챠
B: 흔한 알고리즘(아차!) 또는 음 흔하지 않을 수도 있지만(A 뻘줌 ㅎㅎ;) 이런 식으로 설계하는 알고리즘이 존재할거에요. 어 기본적으로 트라이를 빌드한 다음 그렇게 빌드된 트라이 위에 여러 작업들을 해요. 음 솔직히 말하면 제가 전체적으로 다 기억나지는 않아요. 그래서 라이브로 직접 (아호-코라식을) 알아내볼거에요. 아마 이러한 제 모습이 좀 웃길 수도 있겠네요. 아 게다가 일단 이렇게 트라이를 만들게 되면 전체 phoneNumber를 읽는 동안 Trie를 방문하면서 해당하는 모든 노드를 찾아낼 수 있게 되죠.
- 그러므로 Trie에 있는 모든 노드들과 함께 전체 phoneNumber을 읽어볼거에요.
- 그런 다음 어떤 노드들에게 도달할 수 있는지 알아보기 위해서 bfs와 같은 걸로 trie에 있는 모든 노드들을 탐색할 수 있겠네요.
- 그리고 이 각 노드들은 해당 노드에 대한 (1)다른 노드로 움직이거나 (2)fail link에 있는 노드로 움직일 수 있어요
B: 괜찮나요? A: Ok
B: 이제 이 phoneNumber의 모든 부분 문자열에 도달할 수 있는 모든 노드가 Trie에 있고요. 이 각 words의 단어들은 이 Trie의 일부 노드와 도달할 수 있는지 없는지에 대한 여부를 알 수 있겠네요. 그래서 이러한 과정을 통해 답을 구해낼거에요.
A: 혹시 풀어나갈 과정의 시작과 끝까지의 단계를 아주 간결하게 써줄 수 있나요? 음 뭐 bullet(·) 리스트나 이런걸로요.
B: 물론이죠. 좋은 아이디어네요. 저한테도 도움이 될 거 같아요. (불렛 리스트 작성 설명 생략)
- 트라이를 설계한다.
- 트라이의 각 노드들에 대해 실패 링크를 계산한다.
- phoneNumber를 순차적으로 탐색한다. 각 전화번호 각 숫자에서 제가 지금 어디 노드에 위치했는지 계속해서 추적한다. -> 이 정보가 Trie에서 어떤 노드에 도달할 수 있는지 알려줌
- setp3에 밞은 모든 노드들의 실패 링크는 BFS로 탐색한다. -> 이 정보는 phoneNumber의 모든 부분 문자열에 해당하는 Trie 노드들을 알려줌
- 마지막으로 각 단어들을 iterating하여 제대로 작동하는지 확인한다.
A: OK. (과정 브리핑 생략)
역주) 22:30부터는 라이브 코딩입니다. 영상으로 보는 것을 추천드립니다.