가상 머신 VM: 가상 메모리, 메모리 관리 기법, Hypervisor
가상화 역사
메인프레임 시대(1960~70년대 초)
가상화 기술에 대한 발전은 IBM의 메인프레임에서 시작되었다. CP-67과 VM/370의 전신인 CP-40은 전가상화를 구현한 최초의 OS 중 하나였다. 목표는 값비싼 메인프레임 리소스를 최적화하고 동시에 단일 머신에서 여러 애플리케이션을 지원하고자 했다.
- CP-40: 전가상화의 초기 실험 중 하나였다. 여러 사용자 프로그램을 각각 자체 시뮬레이션 하드웨어 환경에서 동시에 실행할 수 있어, 기본적으로 단일 물리적 컴퓨터 내에서 여러 개의 System/360 메인프레임을 에뮬레이션할 수 있었다.
- CP-67: CP-67은 동적 주소 변환 하드웨어와 같은 추가 기능을 갖춘 System/360 하드웨어의 전가상화를 포함한 VM을 지원했으며, 이는 Model 67의 표준 기능이 되었다.
- VM/370: 1970년대 초에 나온 최초 가상머신이다. CP-67의 기술을 토대로 여러 가상 환경을 동시에 실행할 수 있는 하이퍼바이저(당시에는 control 프로그램이라고 불림)가 포함되었다. 해당 기술은 VMWare, Hyper-V에서 사용하는 하이퍼바이저에 대한 개념과 같은 현대 가상화의 설계에 영향을 끼쳤다.
개인용 컴퓨터의 부상(1970~80년대)
x86 기반 개인용 컴퓨터가 널리 보급되면서 대형 메인프레임에 대한 중요성이 약화되기 시작했다. 그러나 메인프레임은 리소스 최적화를 위해 가상화를 계속 활용했지만, 개인용 컴퓨팅에서는 아직 이 개념이 널리 보급되지 않았다.
최신 가상화의 등장(~2000년대)
리소스 활용, 멀티태스킹의 필요성이 개인 PC에도 점차 필요성이 느껴지기 시작한 1990년대 말과 2000년대 초에 VMware는 개인 컴퓨팅의 표준인 x86 아키텍처에 가상화를 도입했다. 이를 통해 단일 물리적 머신에서 여러 OS 인스턴스를 실행할 수 있게 되어 IT 인프라 관리의 패러다임이 전환되었다.
가상화 및 클라우드 컴퓨팅(~현재)
가상화를 통해 Amazon(AWS)과 Microsoft(Azure)와 같은 기업이 가상화된 컴퓨팅 리소스를 서비스로 제공하기 시작하면서 상업화된 클라우드 시장이 등장했다. 그리고 서버리스 컴퓨팅은 VM과 컨테이너를 넘어 개발자가 기본 인프라를 관리하지 않고 이벤트에 대응하여 개별 기능을 실행하는 새로운 패러다임으로 떠올랐다. 가상화 기술은 하드웨어 최적화 그 이상으로 가상화는 벤더사(Windows, MacOS, ...)의 종속을 줄이는 데 중요한 역할을 했다. 오늘날 많은 기업에서는 다양한 가상화 관리 소프트웨어를 활용하여 리소스를 효율적으로 운영 및 관리하고 있다.
가상 머신 Virtual Machine
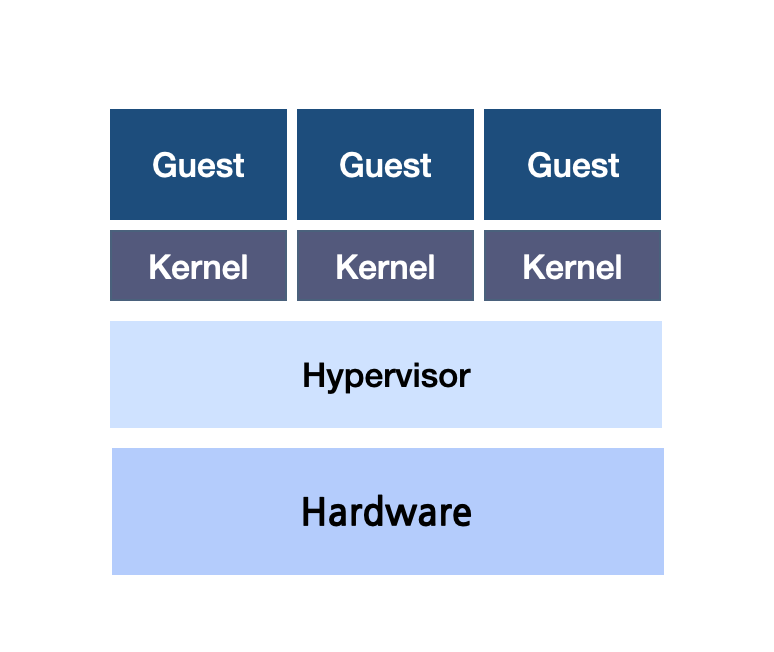
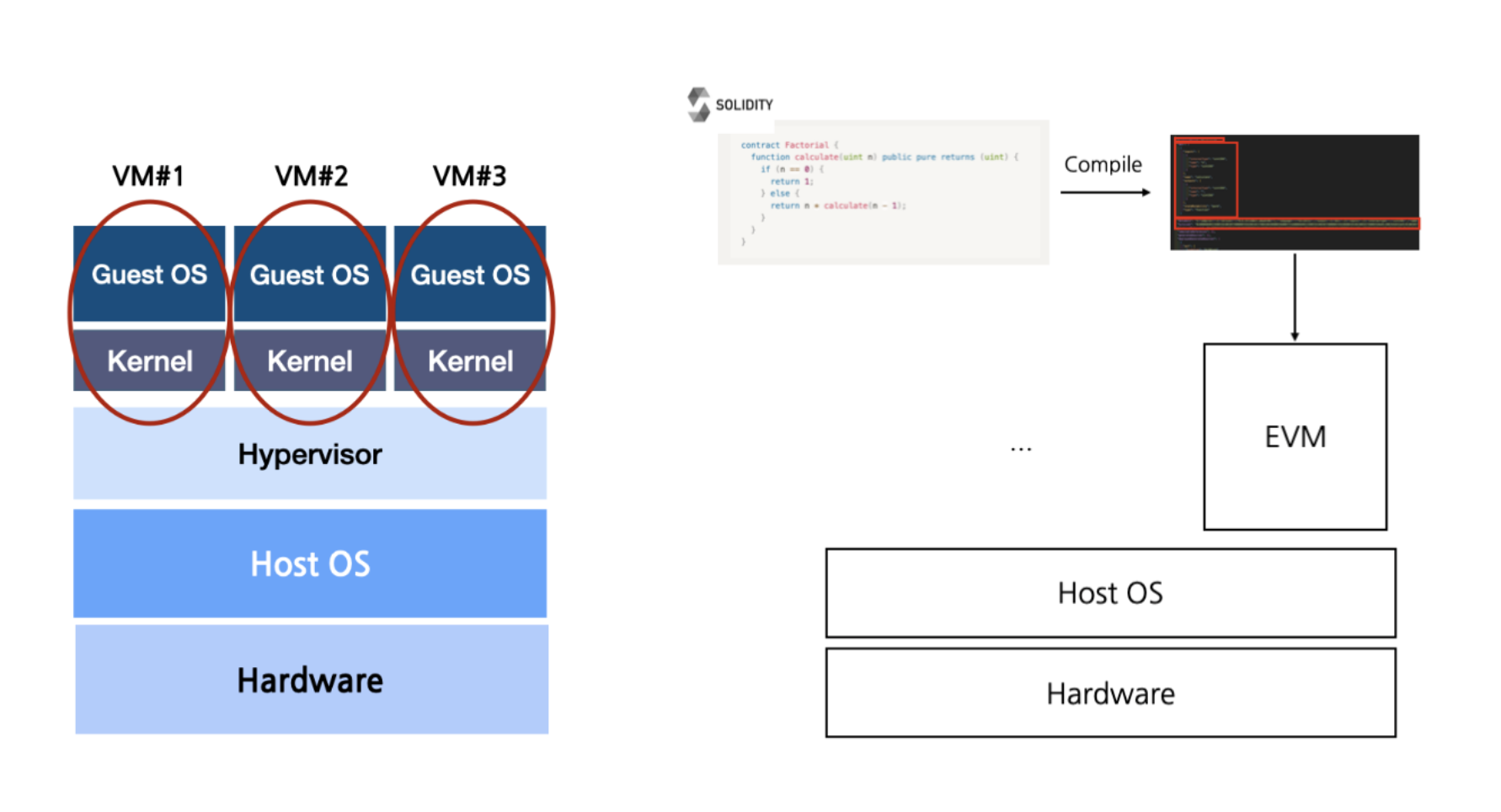
가상 머신은 동일한 하드웨어에서 다수의 OS를 동시에 실행할 수 있다. 가상머신은 크게 Host, HyperVisor(이전에는 가상 머신 매니저 VMM이라 불림), Guest 부분으로 나뉜다. (가상 머신을 다루기 위해서 OS 커널이 굉장히 중요한 부분을 차지한다. 커널에 대해서는 컨테이너, docker에 대해서 다룰 때 더 자세히 적어보려고 하고 해당 글에서는 메모리 가상화 측면에 중점을 두었다.)
가상 메모리 Virtual Memory
가상 메모리 기술은 RAM과 디스크 공간의 조합으로, RAM이 가득 찼을 때 비활성 데이터를 디스크 저장소로 이동하여 운영 체제에서 하드웨어 메모리 RAM을 보다 효율적으로 사용할 수 있다. 페이징 또는 스와핑으로 알려진 이 메커니즘은 활성 프로세스가 항상 필요한 메모리에 액세스할 수 있도록 보장한다.
- 가상 메모리를 사용하면 RAM의 활용도를 높일 수 있다.
- 하지만 디스크와 같은 보조 저장소를 메모리처럼 사용할 때 발생하는 추가적인 지연 시간은 성능 저하의 원인이 될 수 있다.
각 VM에는 이 "가상 메모리"의 한 덩어리가 할당된다. 가상 메모리가 제공하는 추상화 덕분에 각 VM이 전용 메모리가 있는 것처럼 착각하며 동작하게 된다. 이러한 격리성을 부여하는 데에 주소 변환, 페이지 테이블 및 Hypervisor에 의한 메모리 보호 및 관리 방법이 사용된다. 또한 'overcommitment' 및 'ballooning'와 같은 최적화 메커니즘을 제공하여 VM 간의 효율적인 리소스 분배를 보장한다.
메모리 할당 기법
기본적인 메모리 할당 시점으로는 compile time(프로그램 컴파일 시점), load time(프로그램 실행 전 시점), excution time(프로그램 실행 시점)이 있다.
- compile time: 프로그램 내부 사용 주소와 물리적 주소가 같아진다. (ex. 프로그램 주소 = 하드웨어 RAM 주소) 이러면 문제점은 프로그램이 하드웨어에 종속적이게 된다. 그래서 보통 임베디드 시스템에서 주로 활용한다.
- load time: 프로그램 내부 사용 주소와 물리적 주소가 다르다. 프로그램(SW)이 물리적 주소 위치를 정하기 때문에 메모리 로드 시간이 오래 걸린다. 그래서 사실상 이 방법은 안쓰인다.
- execution time: load time과 같이 프로그램 내부 사용 주소와 물리적 주소가 다르다. 그런데 이는 프로그램(SW)가 아닌 MMU 커널 레벨에서 처리한다. 이 방법이 현재 우리가 사용하는 메모리 할당 방법이다.
1) 연속적 메모리 할당 기법 contiguous allocation
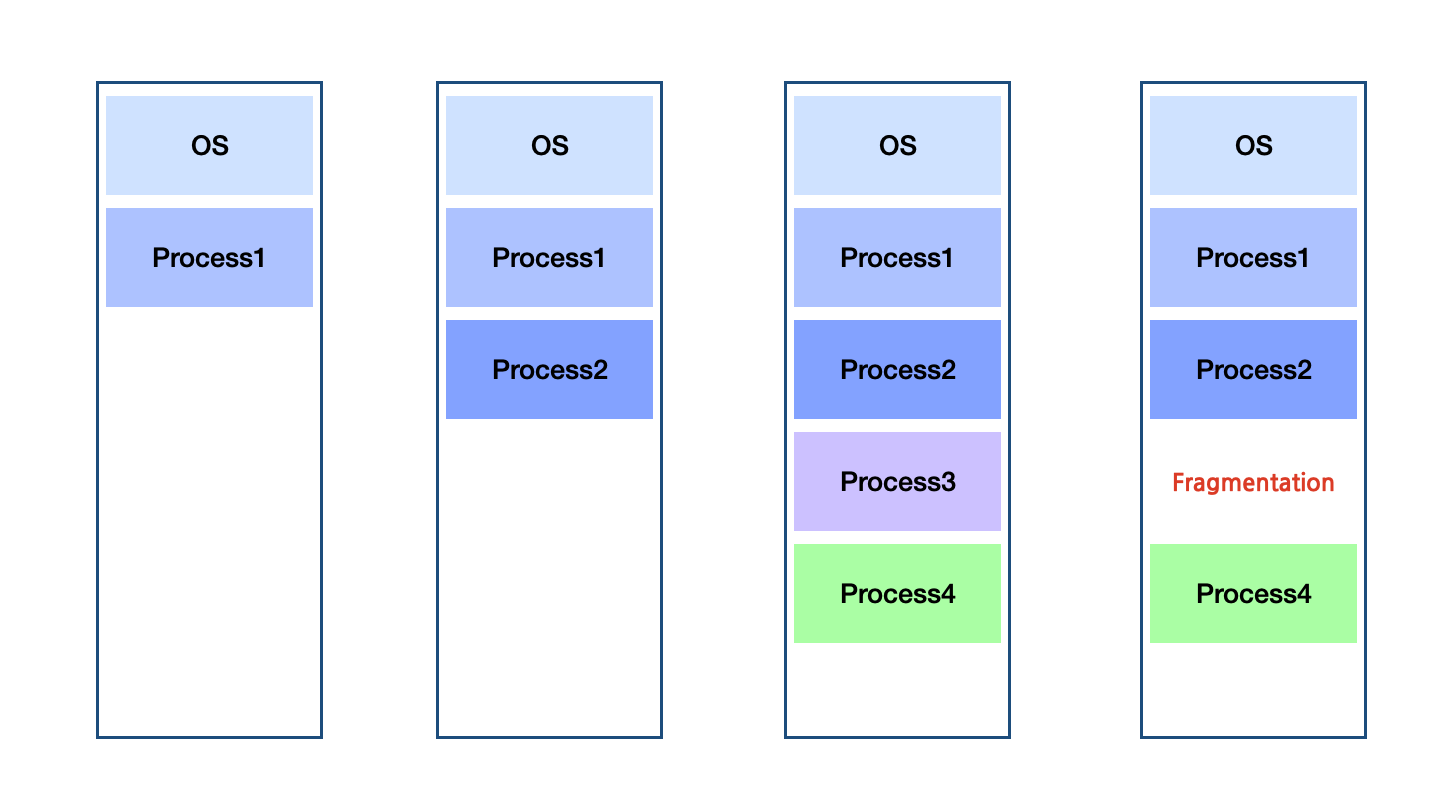
교실에 사물함이 줄지어 있다고 상상해 보면 된다. 한 사물함의 물건이 넘쳐나도 바로 옆 사물함으로 흘러들어갈 수 없다. 마찬가지로 연속 메모리 할당에서는 주소 시퀀스가 논리적으로나 물리적으로나 서로 나란히 있어야 한다. 그래서 전체 메모리는 충분하지만 순차적이지 않은 경우 방식은 외부 단편화 같은 문제가 발생할 수 있다. first-fit, best-fit, worst-fit 등 다양한 메모리 적합 알고리즘을 통해 외부 단편화 크기를 줄이려고 노력하고 compaction을 통해 비어있는 공간을 연속적인 공간으로 만들 수 있지만 그러한 과정에서 오버헤드가 발생하여 성능이 저하될 수 있다.
2) 페이징 기법 paging
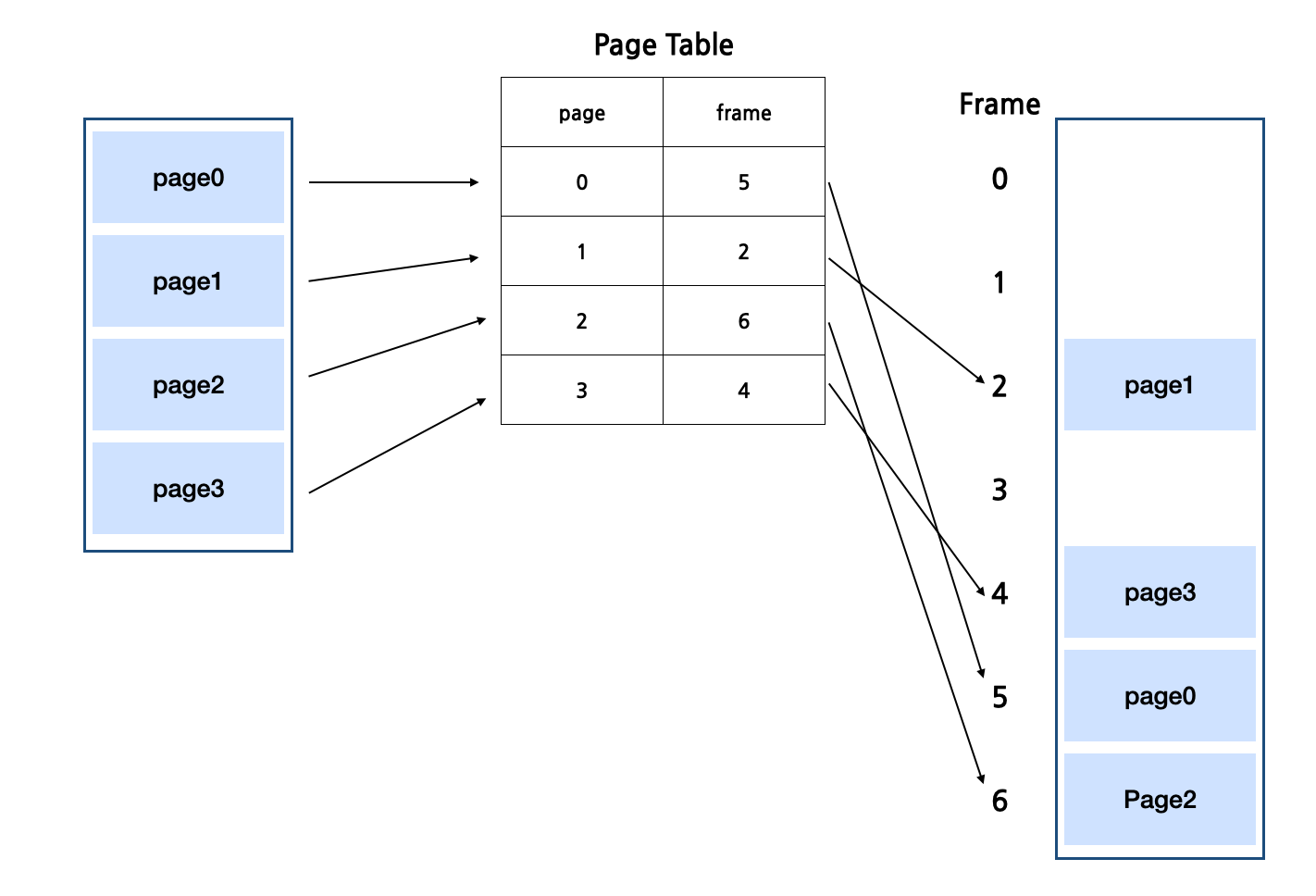
책을 떠올려 보자. 콘텐츠 길이에 관계없이 모든 페이지의 크기는 고정되어 있다. 마찬가지로 메모리도 고정된 크기의 페이지로 나누어 관리하는 것이 페이징 기법이다. 각 페이지는 물리적 메모리의 한 프레임에 매핑된다. 페이징은 외부 단편화와 같은 연속적인 메모리 할당에서 발생하는 문제를 해결한다. 그러나 할당된 공간이 필요한 공간을 초과할 수 있는 내부 조각화라는 또 다른 문제가 발생하게 된다. 이 또한 성능 최적화를 위해 페이징 교체 알고리즘, TLB 등 다양한 노력이 이뤄지고 있다.
VM에서 메모리 관리 : 이중 주소 변환
프로세스가 가상 주소를 사용하고 명령어가 메모리에 대한 액세스를 요청하면 프로세서는 page table 또는 번역 TLB를 사용하여 가상 주소를 물리적 주소로 변환한다. 문제는 이러한 변환 과정이 VM 내부에서도 발생한다는 것이다. VM을 실행하는 환경에는 전체적으로 SLAT(Second Level Address Translation, 이중 주소 변환 체계)를 가지고 있다. Guest OS는 자체 virtual page를 physical page로 변환한다고 생각한다. 하지만 실제로는 다른 guest 주소 집합으로 변환하고 Hypervisor가 이를 실제 host physical page로 변환한다.
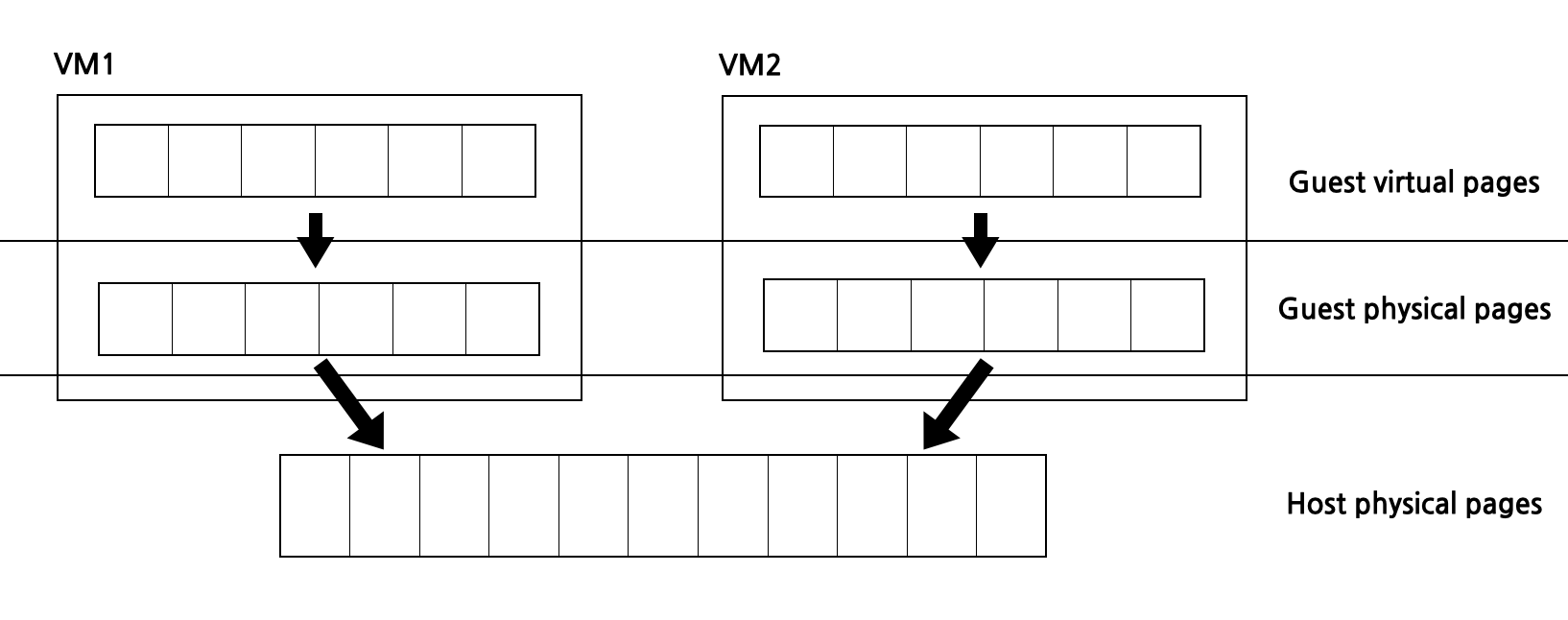
이렇게 하면 이중 주소 변환을 guset 환경에서 한 번(소프트웨어 에뮬레이션 guset page table 사용), host 환경에서 한 번으로 두 번 수행해야 하므로 메모리 액세스 비용이 증가한다.
Shadow Page Table
그래서 소프트웨어 레벨에서 동작하는 Shadow page table을 구현했다. 아래 빨간색 화살표 처럼 이는 Guest virtual page를 Host physical page로 직접 변환한다. 각 VM에는 별도의 shadow page table이 있으며 이를 hypervisor가 직접 관리하는 방식이다. 그러다보니 메모리 작업이 많은 VM이 있으면 hypervisor가 이를 모두 처리해야 하므로 VMexit 및 VMentry 호출이 많아 cpu 집약적으로 오버헤드가 상당했다.
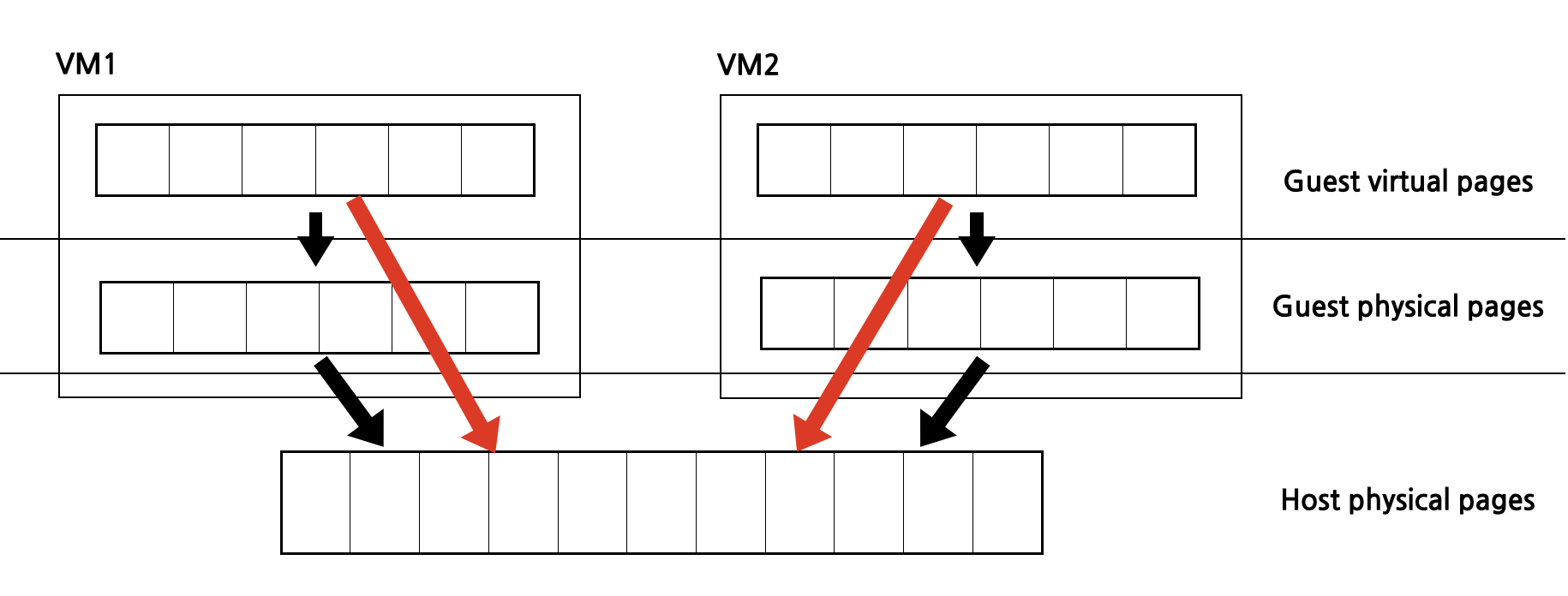
중첩된 페이지 테이블 Nested/Extended Page Tables
그래서 하드웨어 레벨에서 이를 처리해주는 페이지 테이블을 구현하였다. EPT(Extended Page Table)또는 AMD에서는 NPT(Nested Page Table)라고 부른다. 이 기술을 사용하면 page table을 가상화되지 않은 환경에서와 마찬가지로 TLB를 작업해주면 된다. VCPU가 많을수록 효율은 더 높아진다. 이 모든 작업을 hypervisor가 아닌 MMU가 수행해주는 것이다. hypervisor는 중첩 테이블을 관리만 하면 되며, Shadow page table을 유지할 필요도 없어진다.
각 Guest는 가상 메모리에서 실제 메모리로 변환하기 위해 하나 이상의 페이지 테이블을 가지고 있으며, hypervisor는 VCPU를 사용하여 Guest의 CPU 상태를 나타내는 것처럼 NPT(중첩 페이지 테이블)를 활용하여 Guest의 페이지 테이블 상태를 에뮬레이트한다.
- Guest의 페이지 테이블: 각 Guest VM은 guest virtual page(VA)를 실제 physical page(PA)로 인식하는 주소로 변환한다고 믿고 자체 페이지 테이블을 보유한다.
- Hypervisor: Guest VM 상태를 미러링하기 위해 NPT를 유지 관리한다.
- Guest와 Hypervisor 동기화: Guest가 페이지 테이블을 변경할 때마다 Hypervisor가 해당 NPT를 업데이트하여 두 상태가 일치하도록 한다.
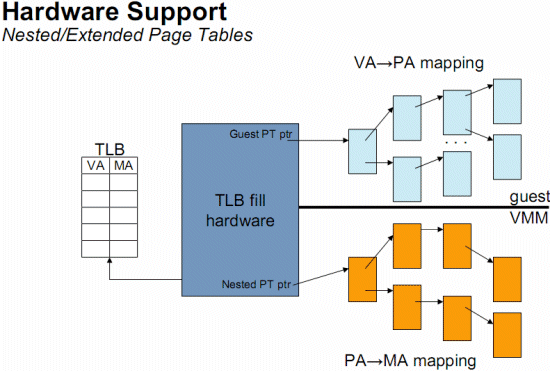
이렇게 NPT를 사용하면 이중 번역 프로세스가 한 단계로 축소되는 것을 볼 수 있다. Guest OS는 중단을 줄이면서 페이지 테이블을 구축할 수 있으며, Hypervisor가 Guest OS를 생성할 때 할당해준 메모리의 머신 주소 정보만 NPT에 적어주면 쉽게 메모리 가상화를 할 수 있다. NPT를 활용하면 Guest OS가 오버헤드를 최소화하면서 페이지 테이블을 관리할 수 있다. 물론 단점은 있다. 가상 환경에서 TLB miss가 발생하면 중첩된 페이지 테이블 또한 검색해야 하기 때문에 miss가 발생하는 상황에 더욱 예민해진다.
이 외에도 메모리 공유(ex. 투명 페이지 공유(TPS)), 메모리 overcommitment, 메모리 압축, 스와핑 등 다양한 메모리 관리 전략을 통해 여러 VM들의 리소스를 효율적으로 사용한다. 이 중 메모리 overcommitment은 Hypervisor가 호스트에서 물리적으로 사용 가능한 메모리보다 더 많은 메모리를 가상 머신(VM)에 할당할 수 있도록 하는 기술이다. ballooning(일명 풍선효과)은 overcommitment 환경에서 메모리를 관리하는 데 가장 많이 언급되는 기술로, "벌룬 드라이버"가 VM 내부에 위치하여Hypervisor는 VM에서 메모리를 회수해야 할 때 이와 통신한다.
그리고 이러한 VM을 관리하고 이러한 메모리 기술을 오케스트레이션하는 데 있어 핵심적인 미들웨어 기술인 가상 머신 매니저(VMM)라고 불리는 Hypervisor과 자꾸 언급이 되는데 이에 대해서 더 알아보고자한다.
하이퍼바이저 Hypervisor (또는 VMM)
VM의 기술 핵심에는 VM을 생성, 관리, 제어하는 소프트웨어 계층인 Hypervisor가 있다. Hypervisor는 VM의 기본 하드웨어 리소스를 에뮬레이션하는 데 중요한 역할을 한다. Guest는 이러한 에뮬레이트된 리소스를 진짜로 인식하고 행동한다. Hypervisor가 Guest가 호스트 리소스에 요청하는 시스템 콜을 모두 대신 처리해준다. 마치 호텔 관리자로 생각하여 각 게스트(VM)가 별도의 공간(리소스)을 갖고 다른 사람을 인식하지 못하도록 해준다고 생각하면 된다. 앞으로 나오는 OS protection ring 개념은 해당 글을 참고하면 이해가 쉽다.
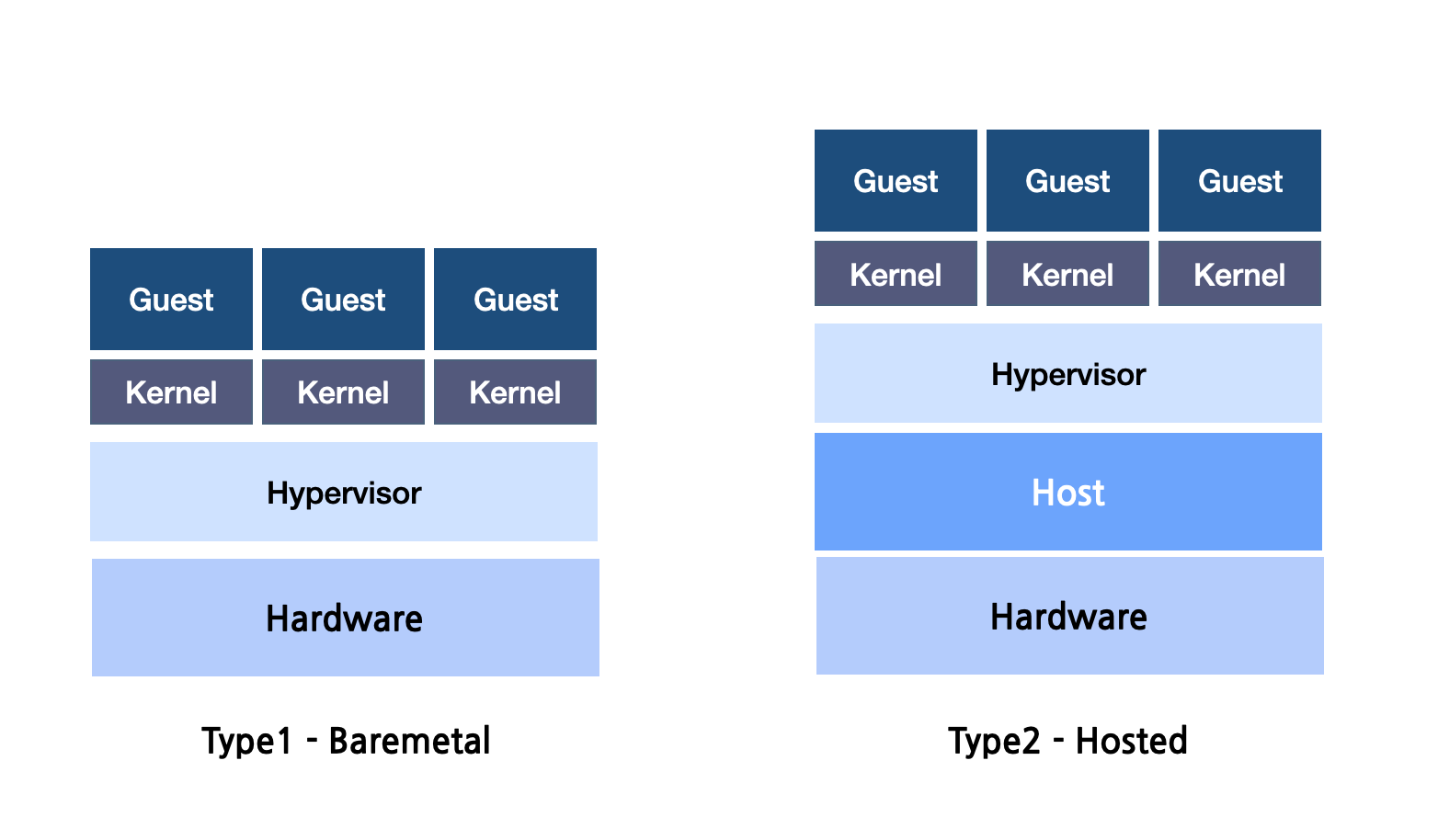
Type1 - Bare Metal
Bare Metal은 운영 체제와 유사한 호스트의 물리적 하드웨어에서 직접 실행된다. 중간 레이어를 제거하여 최적의 성능을 제공한다. 예로는 VMware의 ESXi 및 Microsoft의 Hyper-V가 있다.
Type2 - Hosted
기본 OS에서 작동하는 Hosted 하이퍼바이저는 일반 소프트웨어 애플리케이션과 유사하다. 설정하기는 더 쉽지만 베어메탈 제품보다 성능이 다소 부족할 수 있다. VMware Workstation이 대표적인 예이다.
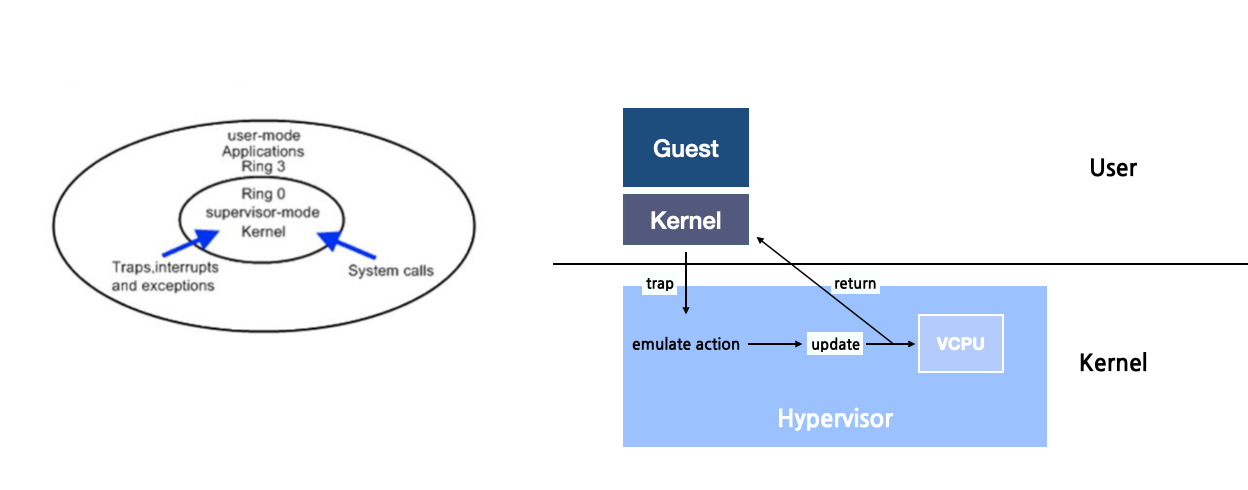
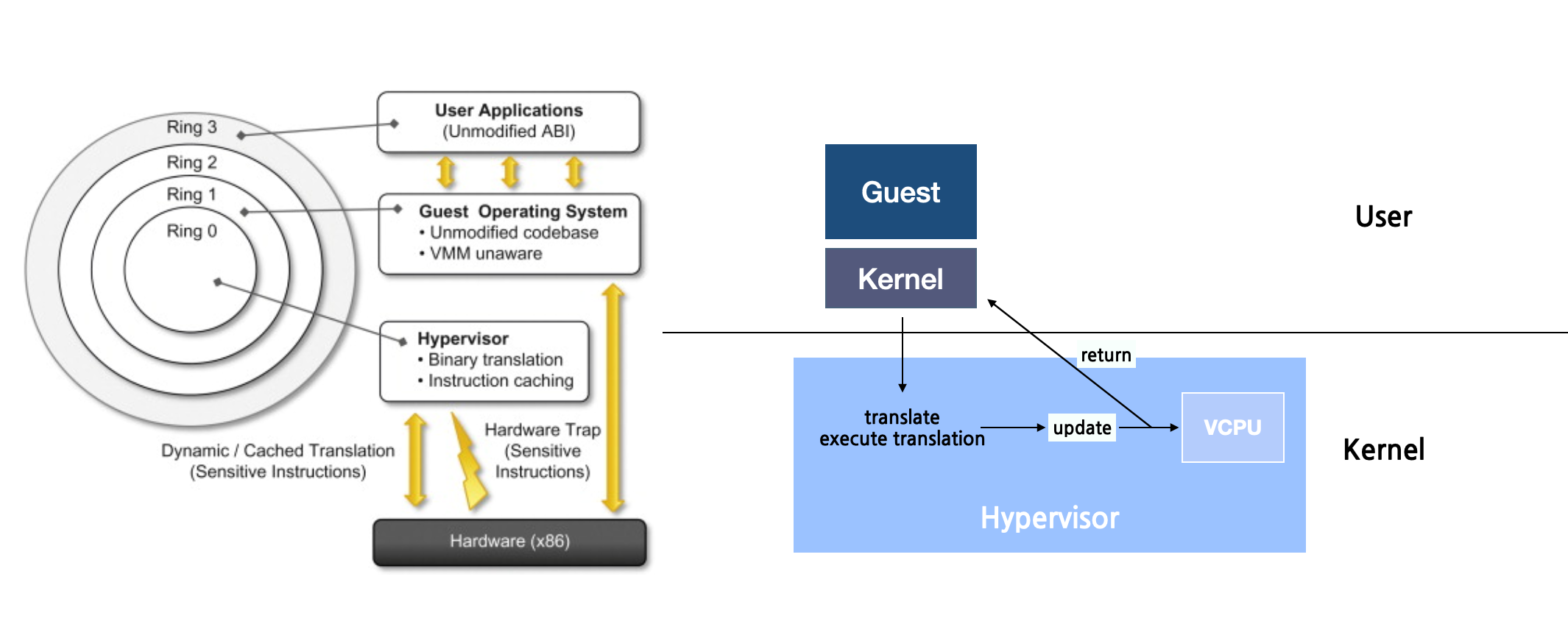
Trap & Emulate
Trap & Emulation은 하이퍼바이저가 가상 머신(VM)이 현재 권한 모드에서 허용되지 않는 명령이 있는지 모니터링하는 기술이다. 우선은 VCPU 기술에 대해 알아야 한다.
- VCPU는 코드를 직접 실행하지 않는다. 대신 각 Guest VM이 인식하는 CPU 상태를 유지한다.
- Context Switching을 통해 Guest 프로세스가 활성화되면 하이퍼바이저는 VCPU에서 캡처한 상태를 물리적 CPU로 전송한다.
Guest가 현재 상태에서 허용되지 않는 권한 있는 명령을 실행하려고 시도하는 경우 Trap & Emulation에 의해 다음과 같이 동작한다.
- 하이퍼바이저에 의해 "trap"상태가 된다.
- 하이퍼바이저는 명령이 올바른 권한 모드에서 실행된 것처럼 에뮬레이션한다.
- 그 결과를 다시 Guest VM에 반환한다.
해당 방식의 가장 문제점은 시간이다. 이 방법을 사용하는 시스템에서는 성능 병목 현상이 발생할 수 있다. VM이 권한 있는 작업을 시도할 때마다 하이퍼바이저는 이를 가로채거나 에뮬레이션하여 잠재적인 오버헤드를 발생시키기 때문이다.
Binary Translation
하지만 일부 CPU는 권한이 있는 명령과 없는 명령이 확연히 구분되지 않는 경우도 있다. x86이 그 중 하나였다. 특정 아키텍처에서는 권한있는 특정 명령이 트랩되지 않는 경우가 종종 발생하였다. 그래서 이러한 문제를 Binary Translation으로 해결했다. 가상화 영역에서 Binary Translation은 Host 하드웨어에서 Guest의 권한 있는 명령을 안전하고 정확하게 실행하는 데 사용된다. 해당 방식은 유용하지만 translation 오버헤드로 인해 느려질 수 있다.
해당 개념은 매우 간단하지만 구현은 복잡하다.
- Guest VCPU가 유저 모드인 경우, 명령은 권한이 없기 때문에 Hypervisor의 큰 간섭 없이 물리적 CPU에서 직접 실행될 수 있다.
- Guest VCPU가 커널 모드인 경우, 명령이 민감하거나 권한이 있는 경우 물리적 CPU 직접 실행하면 안전하지 않을 수 있다. 따라서 Hypervisor는 Binary Translation을 사용하여 Guest의 명령을 호스트가 안전하게 실행할 수 있는 특정 명령어 집합으로 변환하다.
Hardware Assistance
하드웨어 지원 가상화는 CPU 기능을 활용하여 가상화의 성능을 최적화한다. 'Binary Translation' 및 'Trap & Emulate'과 같은 초기 하이퍼바이저 기술은 아키텍처가 제기하는 문제에 대한 해결 방법을 찾아야 했지만, 하드웨어 지원은 하드웨어 제조업체가 이 문제를 직접 해결한다.
- EPT 및 NPT: 위에서 다룬 중첩 페이지 테이블 기능이 포함되어 있다. EPT 및 NPT는 이중 주소 변환의 오버헤드를 줄여 VM의 메모리 성능을 개선한다
- VM enter & exit 가속화: 하드웨어 지원 가상화는 호스트와 VM 간에 발생하는 context switching 시간을 최적화한다. Intel용 VMX 및 AMD용 SVM과 같은 기능을 사용하면 전환 오버헤드가 크게 줄어든다.
- I/O 가상화: 직접 I/O(입출력)를 사용하면 VM이 하이퍼바이저를 우회하여 물리적 I/O 디바이스에 직접 액세스할 수 있다.
- 디바이스 할당: VM이 특정 하드웨어 리소스를 제어하여 네이티브에 가까운 성능을 구현할 수 있다. 예를 들어, 그래픽 집약적인 VM은 GPU에 직접 액세스하여 큰 오버헤드 없이 고품질 그래픽 성능을 제공할 수 있다.
가상화에 대한 수요가 증가하면서 하드웨어 제조업체는 칩 수준에서 이러한 요구 사항을 지원하기 시작하였다. 하드웨어 지원은 소프트웨어와 하드웨어 간의 이러한 시너지 효과의 정점으로, 가상화를 실현할 수 있을 뿐만 아니라 매우 효율적이고 보안에도 뛰어나다.
반가상화 Para Virtualization
위에서 다뤄본 전가상화(Full Virtualization)의 경우 거쳐야 할 단계가 많기에 오버헤드가 발생하여 성능이 느려진다. 그래서 이를 해결하고자 반가상화(Para Virtualization)이 등장했다. 반가상화는 협력 모델을 도입한다. 하드웨어를 에뮬레이트하는 대신 Guest는 특수 API인 HyperCall을 사용하여 하이퍼바이저와 직접 인터랙트한다.
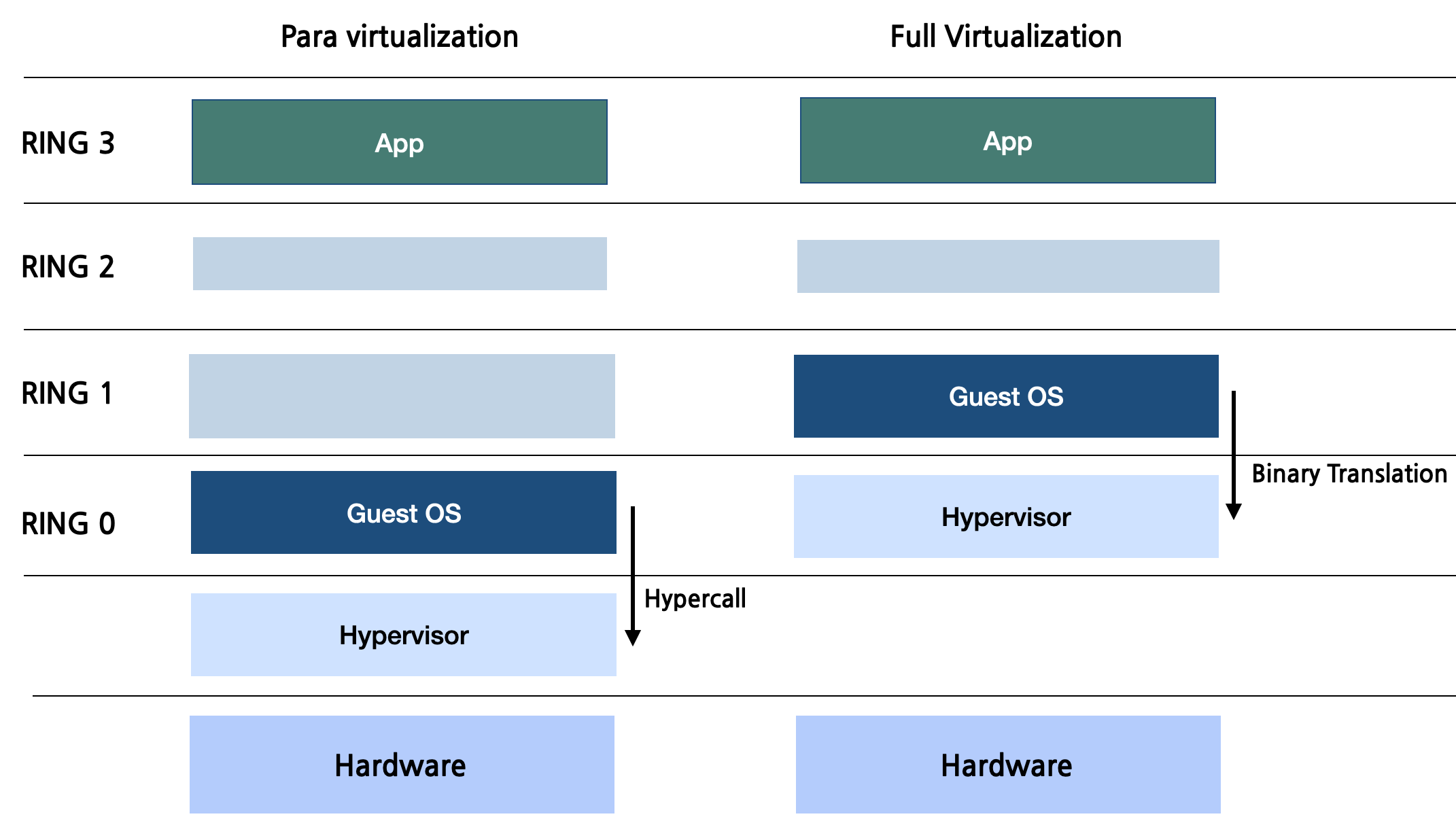
HyperCall을 통해 직접적인 상호 작용하는 것은 하드웨어 에뮬레이션이 필요하지 않으므로 성능을 향상시킨다. 하지만 반가상화에서는 Guest OS가 Hypervisor에 직접 Hyper Call을 날려야 하기에, 자신이 Guest OS라는 사실을 인지해야만 한다. 따라서 반가상화 하이퍼바이저에 올라가는 Guest OS는 커널을 수정하여야 하므로 이 접근 방식은 사용 가능한 소스 코드가 없는 독점 OS에 적합하지 않다.
JVM, EVM?
지금까지 알아본 기술은 물리적 하드웨어의 가상 표현을 생성하여 단일 머신에서 여러 운영 체제 인스턴스를 동시에 실행할 수 있게 해주었다. 이 기술의 연장선상으로 컨테이너, WASM으로 볼 수 있으며 이들은 VM 보다 가볍고 구체적인 추상화를 제공한다.
JVM과 EVM 또한 "VM"이라고 불리지만, 그 목적과 기능이 VMware와 같은 하드웨어 중심 VM과는 전혀 다른 기능을 하는 머신들이다. JVM과 EVM은 물리적 하드웨어를 시뮬레이션하는 대신 애플리케이션 계층을 추상화하여 소프트웨어를 호스트 OS와 격리하는 데 중점을 두고 있다. 특히 JVM은 "Wrtie Once, Run Anywere"이라는 문구를 통해 이 개념을 대중화했다. 하나의 물리적 머신에서 여러 VM을 실행할 수 있는 기술을 다양한 콘센트 타입에 맞게 조정할 수 있는 멀티탭으로 비유하자면, JVM은 전 세계 모든 종류의 콘센트에 맞도록 설계된 범용 플러그 어댑터라고 보면 된다.
ref
Operating System Concepts, 10/E
https://www.wikiwand.com/en/IBM_CP-40
https://cseweb.ucsd.edu/~yiying/cse291j-winter20/reading/Virtualize-Memory.pdf