분산 데이터베이스 탐구: 데이터 복제와 일관성
분산 데이터베이스 탐구: 데이터 복제와 일관성
일관성1에 관한 이야기는 분산 시스템과 데이터베이스 이론을 깊게 공부하면서 늘 블로그에 정리해보고 싶었던 부분이었다. 분산 시스템은 대규모 데이터 처리를 위해 필요한 환경이다. 이러한 분산된 시스템이 마치 하나의 결정론적 머신처럼 동작하기 위한 작업들이 필요하다. 이를 이뤄내는 과정에서 어떻게 데이터 일관성을 지켜나가는지에 대해 알아보고자 한다.
- 강한 일관성(Strong Consistency): 연산 후에 바로 모든 복제본이 같은 값을 가지고 있음을 보장한다.
- 최종 일관성(Eventual Consistency): 시간이 지나면 모든 복제본이 같은 값을 가진다는 것을 보장한다.
데이터 복제
데이터를 한 곳에만 보관하면 해당 시스템에 대한 의존도가 높아 운영에 어려움이 많아진다. 만약 해당 데이터 저장소에 장애가 발생하면 운영하는 서비스는 중단되어버린다. 그래서 다른 노드에 데이터 복제를 해놓는 방식을 택한다. 흔히 쓰이는 단일 리더 구조는 리더와 팔로워를 구분해놓고 리더에 쓰기 작업이 발생하면 리더에서 쓰기 작업을 하고 이를 팔로워 노드들에게 복제를 전송하는 방식으로 동작한다. 이러한 복제 구조로 각 역할을 분담(리더는 쓰기 작업, 팔로워들은 읽기 작업)하여 부하 분산이 가능해진다. 복제하는 방식으로는 동기, 비동기가 존재한다.
- 동기식: 강한 일관성(Strong Consistency) 보장이 되지만 복제 지연으로 대기 시간 발생한다.
- 비동기식: 대기 시간이 없어 유저 경험은 좋지만 최종 일관성(Eventual Consistency)을 지키기 위한 노력이 필요하다.
- DB마다 메커니즘이 제각각이지만 동기와 비동기 사이로 리더 커밋 후 이벤트 전송까지만 보장하는 형식도 존재한다. (ex. Mysql의 semi-sync)
리더의 구성은 아키텍처마다 다를 수 있다.
- 단일 리더 구조: 하나의 리더만 쓰기 작업을 하는 유형. 리더 장애 취약. 읽기 확장성 좋지만 쓰기 확장 제한적. (ex. Mysql, PostgreSQL)
- 다중 리더 구조: 여러 개의 리더가 동시에 쓰는 유형. 고가용성. 고가용성. 쓰기 확장성 좋지만 데이터 충돌 해결 복잡함. (ex. Cassandra, 블록체인)

여러 노드에 데이터를 복제하면 어느 한 노드에 장애가 발생하더라도 금방 복구할 수 있는 내결함성을 지니게 된다. 팔로워 장애 복구는 새로운 노드를 다시 시작하여 데이터 복제를 해주면 된다. 리더 장애 복구는 새로운 리더를 선출하기 위해서는 다수의 quorum이 필요하며(최소 3개 이상, 홀수 선호) 장애시 훼손된 데이터 복구가 필요하다. 보통 데이터 훼손은 저장소의 지속성 및 신뢰성에 있어서 중요한 문제이기 때문에 보통 WAL(write-ahead log)2 통해 문제를 해결한다. 이렇게 복제 기능은 복잡한 분산 시스템 환경에서 높은 내결함성과 성능 향상을 가져다 주는 핵심 기능의 역할을 하고있지만서도 그만큼 고민해야 할 요소도 많다.
- 복제가 이뤄지는 과정은 결국 IPC로 프로세스간 통신으로 이루어진다. 그러면 결국 네트워크 통신을 해야 하고 많은 비결정적 요소에 노출된다. 데이터센터 장애, 네트워크 회선 장애와 같은 물리적인 부분은 물론이고 복제 작업을 수행하는 스레드나 프로세스에 문제가 생길 수도 있다.
- 제대로 복제가 이뤄진다고 해도 비동기 전송일 경우 지연이나 찰나의 순간으로 인해 일관성이 깨지는 순간이 발생한다. 그러한 모습이 클라이언트에게 노출되면 해당 시스템의 신뢰성은 떨어지게 된다.
- 복제로 인해 강한 내결함성과 성능 향상을 가질 수 있는 대신에 데이터 일관성을 유지하는 데에 어려움이 생기게 된다.
복제된 데이터를 읽을 경우 발생하는 일관성 문제
리더에서 쓰여진 다음 바로 읽기 요청을 하는 데 아직 팔로워 노드에 복제가 안된 상황이라면 일관성 문제가 발생하게 된다. 시스템은 유저에게 동기식처럼 작동하는 것처럼 보여야 한다. 보통 비동기식 복제 전파를 통해 유저 경험을 향상시키고 트랜잭션과 같은 기능을 통해 복제 지연 문제를 해결하며 읽기 일관성을 지키려고 한다. 다음은 데이터 중심 애플리케이션 설계3 책에 나오는 한 예시이다.

비동기식 복제를 사용할 경우 읽기 일관성을 유지하기 위한 전략이 필요하다.
- 내가 쓴 글을 읽는 경우에는 쓰기 후 특정 시간 동안만 리더에서 읽기를 수행하거나,
- 유저의 최신 쓰기 타임스탬프를 활용하는 방법이 있다.
- 만약 다른 사람이 쓴 글을 읽는다면, 노드의 최신 데이터 복제 시간을 파악하여 리더와 동기화된 노드와 연결하도록 하는 방법으로 해결해 볼 수도 있겠다.
이렇게 다양한 방식들을 통해 개발자들은 문제를 해결해낼 수 있다. 근래 재밌게 본 컨퍼런스 영상에 요청 및 상태 변화가 빈번한 게임 서버를 운영하는 경우에 애플리케이션 레벨에서 상태를 보관하고 나중에 쓰기 처리를 하는 방식으로 설계한 사례이다.4 이는 빈번한 디스크 IO로 인한 성능 향상이 주목적이었지만 읽기 일관성 또한 같이 해결이 되는 솔루션이었다. 이렇게 일관성을 해결하게 되면 쓰기 처리를 할 때 상태가 각 서버에 보관되어 있으므로 고려해야 할 부분이 추가적으로 나온다. 친구 맺기와 같은 서로 상호작용하는 요청에는 각 변경된 상태(A는 B를 친구목록에 저장, B는 A를 친구목록에 저장)를 따로 보존하고 있기 떄문에 이를 분산 트랜잭션을 통해 해결해줘야 한다는 내용이다.
분산 시스템에서 일관성을 유지하기 위해서 쓰기는 어떻게 해야할까? 우선 '트랜잭션(transaction)' 개념을 짚어보자.
ACID 트랜잭션
트랜잭션은 단순한 연산 집합이 아니라 특정 상태 변경에 대한 약속이자 논리적 최소 단위이다. 돈 거래와 같은 사건의 인과성(causality)이 중요한 시스템에서는 하나의 거래내역을 담은 트랜잭션의 장애 복구나 충돌에 대해 가장 민감하기 때문에 ACID 특성에 따라 무결성을 보장한다.
단일 리더인 경우 멀티프로세싱 또는 스레딩 환경에서 동시 쓰기 요청이 전송되면 동시에 여러 트랜잭션을 일으켜 의도치 않게 문제가 발생할 수 있다. 이는 주로 뮤텍스(lock) 기법이나 트랜잭션 기반 메커니즘을 통해 해결한다. 다음은 REDO 로깅이 포함된 2PL(2-Phase Locking)의 예시이다.
# 2PL
begin_tx
read(a) \
write(a) - (2PL)
... /
end_tx
1) 트랜잭션 실행 중에 인메모리/디스크 데이터베이스 상태를 수정하지 않고 버퍼 쓰기를 한다.
- writea(a) 쓰기 작업을 하는 경우, Wlock(a), tx.writes[a] = a
- read(a) 읽는 작업을 하는 경우, Rlock(a), tx.reads[a] = true
2) 커밋하는 경우
- 버퍼링된 쓰기(tx.writes)를 포함하는 로그 레코드를 만들고, 로그 레코드를 디스크에 플러시한다.
- 그런 다음 버퍼링된 쓰기가 디스크의 실제 데이터베이스에 기록된다.
- 모든 잠금을 해제한다.
쓰기를 버퍼링하는 이유는 데드락이나 장애로 트랜잭션이 도중에 중단될 수 있기 때문이다. 바로 쓰기를 시작하면 REDO, UNDO 로그가 남아있지 않는 이상 되돌릴 방법이 없다.5
- 커밋 시점에 데이터 쓰기보다 로그 기록을 먼저 하는 이유는 트랜잭션 원자성(A)의 특성을 지키기 위함이다. 만약 역순으로 작업이 이뤄진다면 크래시가 날 경우 부분 갱신이 발생할 수 있다.
- 실제 데이터 쓰기 작업을 커밋 시점까지 지연시키기 때문에 다른 트랜잭션이 현재 트랜잭션의 버퍼링된 쓰기를 방해하지 않도록 커밋 시점까지 lock을 잡는 것이 안전하다.
분산 트랜잭션
분산 시스템에서 트랜잭션이 각 노드에서 어떠한 분산 트랜잭션 메커니즘없이 로컬 트랜잭션처럼 동작하면 어떻게 될까? 다음 트랜잭션 T1을 분산 환경에서 실행한다고 생각해보자.
# 초기 상태 (a=0, b=0)
begin_T1
write(a=1) \
write(b=1) - (2PL)
... /
end_T1
트랜잭션 코디네이터, 데이터 서버 그래프이다. 'a=1' 트랜잭션은 서버 A로, 'b=1' 트랜잭션은 서버 B로 요청된다.
클라이언트 --> 트랜잭션 코디네이터 ---> 서버 A
---> 서버 B
요청을 받는대로 각 서버에서는 해당 트랜잭션을 실행하게 된다.
Ta) 코디네이터 --> 서버 A: a를 잠그고, a=1을 로그하고, 데이터베이스 상태에 a=1을 쓰고, a를 잠금 해제한다.
Tb) 코디네이터 --> 서버 B: b를 잠그고, b=1을 로그하고, 데이터베이스 상태에 b=1을 쓰고, b를 잠금 해제한다.
위 시나리오는 문제가 많다. 서버 B에서 커밋하지 못하는 상태라면 코디네이터는 트랜잭션을 중단(abort)해야 한다. 그런데 만약 코디네이터가 서버 A에 메시지를 보내고 아직 서버 B에게 보내기 전에 해당 문제가 발생했다면 a의 변경 사항만 볼 수 있게 되고, b의 변경 사항은 손실된다. (a=1, b=0) 이러하면 쓰기 일관성 위반이다. 그리고 이렇게 서버에 각각 트랜잭션을 일으키면 충분히 네트워크 지연이나 대기 현상으로 Ta 작업 완료 후 A서버로 읽기 요청이 오면 데이터는 (a=1, b=0)으로 읽히게 되는 읽기 일관성 문제도 발생하게 된다.
그래서 분산 시스템에서 여러 노드나 서비스 간에 데이터의 일관성을 유지하기 위해서 분산 트랜잭션 메커니즘을 사용한다. 이는 여러 노드에 걸쳐서 수행되는 트랜잭션을 하나의 논리적 단위로 묶어 관리한다. 대표적으로 2PC(2-phase commit)와 Saga 패턴이 있다.
2PC(2-Phase Commit)
2PC는 분산 트랜잭션에서 원자성을 보장하기 위한 프로토콜이다. 모든 참가자가 트랜잭션을 진행하기 전에 커밋하거나 롤백해야 하는 원자적 트랜잭션 방식을 사용한다. 원자성을 보장한다고 해서 강한 일관성을 보장한다고 말할 수는 없다. 강한 일관성을 달성하기 위해서는 원자성 뿐만 아니라 데이터 동기화 작업 또한 고려되어야 한다. 2PC는 노드 간 통신이나 장애로 지연이 발생하여 일부 노드는 늦게 커밋될 수 있기 때문에 최종 일관성(eventual consistency)을 보장한다고 봐야 한다. 그래도 코디네이터를 통해 과정을 두 단계에 걸쳐 분산된 데이터를 논리적으로 일관되게 저장하자는 것이 목표이다.6 일반적으로 과정은 [begin → end] → prepare → commit로 이루어진다. (Dynamo에서는 [begin → end] 작업이 prepare에 속해있어 이 부분은 유연하게 위치하는 듯 하다.7)
- begin ~ end: 참여자는 각 독립적인 일을 수행한다. 자신의 로그에 트랜잭션 정보를 기록하고 해당 데이터에 잠금을 건다.
- Prepare Phase (준비 단계) 코디네이터는 모든 참여자에게 준비되었는지 물어본다. begin~end가 정상적으로 된 참여자는 준비 완료라고 응답한다.
- Commit Phase (커밋 단계) 코디네이터는 모든 참여자가 준비 완료 응답을 보냈을 경우, 커밋을 수행하도록 명령한다. 참여자는 이 명령을 수행하고 트랜잭션을 커밋한다. 그리고 데이터 잠금을 해제한다.

트랜잭션을 모아서 관리하는 트랜잭션 매니저라고 불리는 코디네이터를 통해 2PC를 수행하는 해당 메커니즘은 분산된 시스템이 마치 하나의 시스템으로 동작하는 안정성과 최종 일관성을 보장해주게 된다.
- prepare-TA 이후 prepare-TB에서 충돌하면 coordinator의 복구 프로토콜이 분산 트랜잭션을 abort 중단해야 한다. (a가 여전히 잠겨 있기 때문에 다른 트랜잭션은 a=1을 읽을 수 없다)
- prepare 단계를 모두 정상적으로 거친 후 commit-TA 후 commit-TB가 완료되기 전에 충돌하면 coordinator의 복구 프로토콜은 서버 B에 다시 commit 요청을 보내서 데이터 일관성을 맞춰야 한다.
현재 PostgreSQL8이나 MySQL9은 분산 트랜잭션 2PC 기능을 지원하고 있다. 그러나 늘 새로운 기술을 사용할 때는 성능 및 운영상의 복잡성을 고려할 때 사용 시 신중하게 고려해야 한다. 2PC는 다음과 같은 단점을 가지고 있다.
- 코디네이터가 트랜잭션을 관리하니 여기서 장애가 발생하면 SPoF(단일장애지점) 문제가 발생한다. 만약 prepare 단계에서 장애가 발생하면 참여자들은 commit or abort라는 메시지를 받기 위해 블로킹되어 무한 대기해야 한다.
- 반대로 참여자가 장애가 발생한다면 코디네이터는 응답을 대기해야 한다.
- 여러 단계를 거치면서 코디네이터를 통한 많은 네트워크 통신 시간과 장애 복구를 위한 많은 디스크 쓰기 등으로 비용이 비싸다.10
위와 같은 단점으로 인해 이벤트 기반 마이크로서비스 아키텍처나 주문 처리 서버와 같이 일관성보다 확장성이 더 중요한 경우에는 Saga 패턴을 사용하여 트랜잭션 비용을 줄이고 최종 일관성을 추구할 수 있는 방법도 존재한다.
Saga 패턴
Saga 패턴은 2PC처럼 분산 트랜잭션의 원자성을 보장하지는 않지만 최종 일관성(Eventual Consistency)을 보장한다. 그러나 이는 데이터베이스에게 주어진 역할이라기 보다는 그와 연결된 애플리케이션에게 역할이 이전된다.
Saga의 각 트랜잭션은 각 특정 마이크로서비스와 연결되어 수행한다. 연결된 서비스들 중 하나가 실패할 경우, 미리 수행한 서비스들에게 실패한 트랜잭션에 대한 보상 작업(compensating transactions)을 통해 최종적으로는 모든 시스템이 일관된 상태를 유지한다.
- 연속된 여러 작업들이 이벤트를 발생시키며 서로 통신한다.
- 한 서비스에서 트랜잭션이 성공적으로 완료되면, 그 결과로 다음 서비스를 호출하는 이벤트가 발생한다
- 만약 도중에 일부 트랜잭션이 실패하게 된다면 보상 로직을 실행하는 '보상 이벤트'가 발생한다.
2PC와 Saga 모두 일관성을 유지하는 것을 목표로 한다는 장점이 있지만, Saga의 경우에는 강력한 원자성을 요구하는 것이 아닌 좀 더 마이크로 서비스 구축과 같은 유연한 시나리오에 더 적합하다. 물론 원자성을 보장하지 않는 대신에 부족한 부분을 직접 채워나가야 한다.
- 우선 각 서비스나 작업에 대한 보상 트랜잭션을 직접 개발 및 관리해야 한다. 유지보수의 복잡성이 증가한다.
- 그리고 각 이벤트 순서를 보장할 수 있는 시스템이 필요하다.
- 하나의 서비스에서 발생하는 장애가 다른 서비스 보상 트랜젹션을 트리거하여 연쇄 실패가 발생할 수 있다. 서비스 간의 의존성을 잘 처리해야 한다.
이러한 Saga 패턴에는 Orchestration, Choreography 두 종류가 존재한다.
Choreography Saga
Choreography 방식은 2PC나 Orchestration 방식과는 다르게 중앙 집중없이 각 시스템끼리 이벤트를 교환하여 분산 트랜잭션을 달성한다. 중앙에서 관리하는 코디네이터가 없기 떄문에 통신 비용도 줄고 SPoF도 없다. 그러나 시스템이 복잡해질수록 관리나 디버깅이 매우 어려워진다는 단점을 가지고 있다. 또한 통합 테스트를 수행하기가 매우 난해하다. 그래서 유지보수, 관리 측면에서 Orchestration 방식을 많이 선호한다.

Orchestration Saga
2PC와 마찬가지로 중앙 집중 시스템이 존재한다. 각 시스템으로부터 이벤트를 받아 분산 트랜잭션을 달성한다. 이러한 방식은 오케스트레이션에서 모든 이벤트를 관리하기 때문에 관리나 디버깅이 쉽다는 장점이 있다. 그러나 중앙 집중 방식이라서 아무래도 오케스트레이션 서버에 SPoF 문제가 있어서 확장성으로 보았을 때 추가적인 고민이 필요할 시기가 온다.
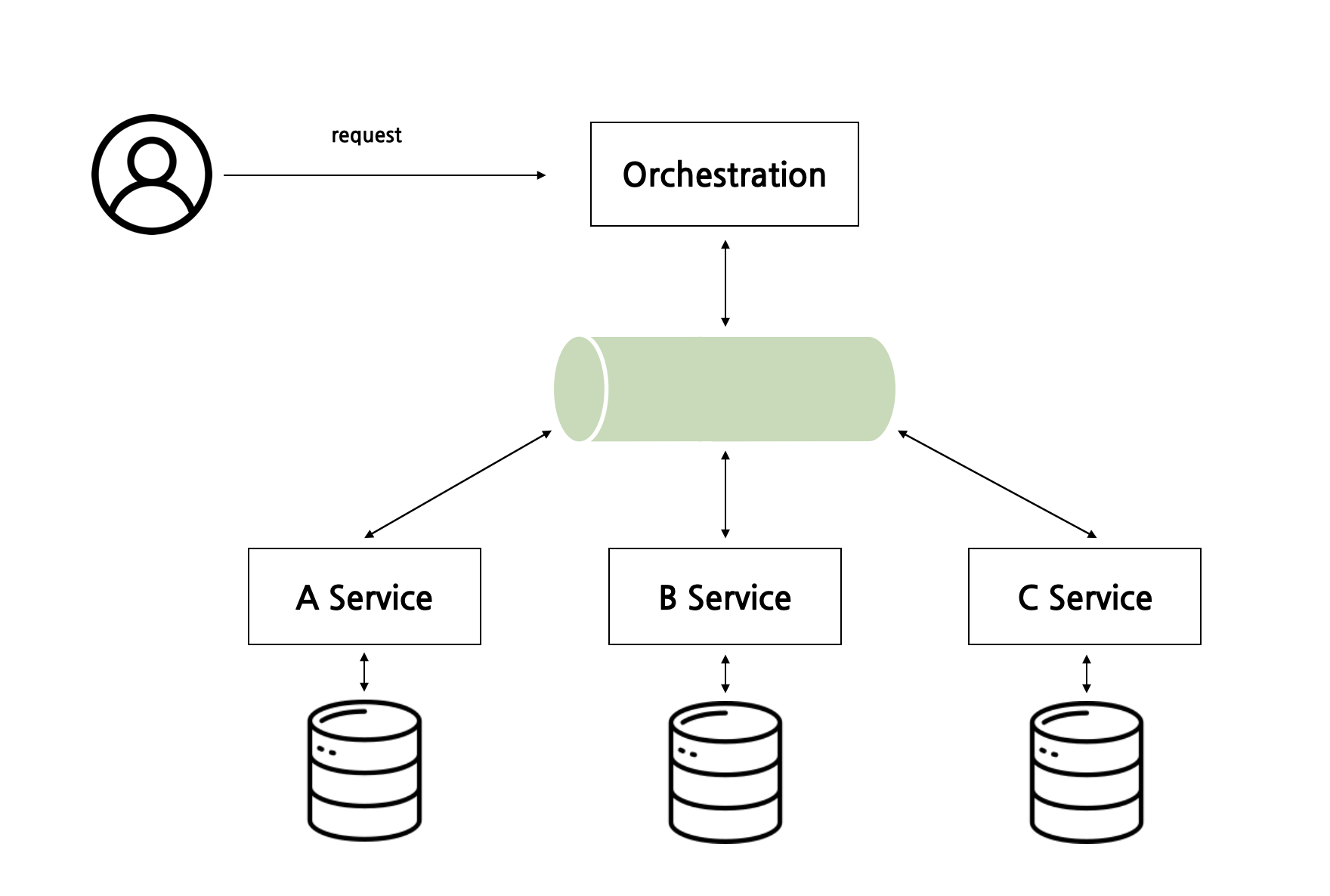
2PC와 Saga 패턴을 공부하면서 각 메커니즘들은 고유한 장점과 과제를 가지고 있음을 가볍게 알아보았다. 분산 트랜잭션을 관리하고 일관성을 보장하기 위한 다른 패턴과 기술로는 3PC(3단계 커밋)도 있다. 더 나아가서는 다음 글에서 다룰 합의 알고리즘으로 Paxos, Raft로 일관성을 유지하는 방법도 있다. 이러한 기술들은 분산된 시스템에서 데이터를 일관되게 처리하기 위해 고안되었다.
이러한 기술들이 실제로는 어떻게 사용하고 있을까? 필자는 백엔드 엔지니어이기 때문에 마이크로서비스로 예를 들어보자. 단일 리더 구조인 경우에는 쓰기 DB를 ACID 트랜잭션을 지원하는 DB(MySQL, PostgreSQL 등)으로 설정하고, 읽기를 하는 데이터를 저장하는 데에 크게 제약이 없는 MongoDB와 같은 DB로 시스템 디자인을 해볼 수 있겠다. 그러면 여기서 추가로 CDC, transactional outbox 패턴11, materialized view, kafka와 같은 신뢰성 있는 message queue 시스템이 추가적으로 필요하게 되어 복잡성이 증가한다는 단점이 있지만, 최종 일관성을 보장하는 마이크로 서비스 설계를 해볼 수 있다.

데이터 쓰기 충돌 회피하기
하지만 다중 리더인 경우에 시스템 복잡성은 더 확장된다. 여러 리더에게 동일한 데이터에 대한 동시 쓰기 요청이 발생하면 충돌이 발생할 수 있다. 데이터 충돌 발생한 경우에 위와 같은 2PC, saga 패턴과 같은 분산 트랜잭션 기법이 직접적으로 해결해주지 않는다. 데이터 쓰기 충돌이 발생하는 부분을 추가적으로 고려해야 한다.

우선 첫 번째로 생각나는 전략은 합의 알고리즘이다. 여러 리더를 사용하는 블록체인 기술에서는 이를 해결하기 위해 합의 알고리즘을 사용하여 신뢰성을 구축한다. 거래에서 발생하면 안되는 가장 중요한 문제가 double spending이기 때문에 동시성을 매우 조심하게 다뤄야한다는 점이 있다. 그래서 비트코인은 평균 10분에 하나의 block이 생성되고 이에 대한 문제로 여러 확장성 전략과 새로운 체인들이 만들어지고 있다. (합의 알고리즘은 다음 글에서 자세히 다루고자 한다.) 합의 알고리즘을 설계하고 구축하기 위해서는 상당한 리소스가 소모된다. 그래서 블록체인에서는 생태계 확장을 위해 자체 sdk를 제공하기도 한다. 블록체인이 아닌 기업이 관리하는 국내 한 뱅크 서버에서는 계정계 서버와 같이 거래내역을 저장하는 높은 신뢰성을 요구하는 경우 인과성 문제를 크게 키우지 않기 위해 단일 서버로 운영하고 있다.12
그 다음으로 리소스를 덜 사용하는 방식으로 고려해보면, 애플리케이션 수준에서 처리하는 방법도 있다. 다중 리더 구조인 경우에도 특정 레코드 모든 쓰기가 동일한 리더를 거치도록 애플리케이션 레벨에서 보장해준다면 이러한 충돌은 발생하지 않는다. 예를 들어, 특정 유저 요청을 가장 가까운 노드로 라우팅 설정하는 방법이 있다. IP나 주소가 서울에 해당하는 유저는 서울에 위치한 노드로 라우팅하고 LA에 위치한 노드는 해당 지역 노드로 라우팅하여 충돌을 회피하는 것이다.
그러나 figma, google docs와 같은 협업 애플리케이션에서는 사실상 충돌을 회피할 수가 없다. 멀티 유저가 동시에 작업하는 경우가 매우 흔하게 발생하기 때문이다. 이들은 어떻게 회피하지 않고 이를 직접 해소하는지도 한번 알아보자.
데이터 쓰기 충돌 감지 및 해결하기
가장 흔하게 생각할 수 있는 것은 협업할 때 주로 사용하는 GIT이다. 협업을 하다보면 자주 충돌이 일어나며 개발자들은 충돌을 감지 후 이를 해결해나간다. 그리고 이 글의 주된 관심사인 분산 데이터베이스 시스템같은 경우에는 데이터 충돌을 감지하기 위하여 보통 버전과 타임스탬프를 사용한다. 각 데이터에 명시적으로 기재하여 변경 사항을 복제할 때 동일 데이터에 다른 버전이 존재하면 이를 감지하게 된다.
단일 리더 구조에서는 가장 흔히 접할 수 있는 개념으로 데이터베이스에서 여러 버전의 데이터를 유지하여 충돌을 해결하는 다중 버전 동시성 제어(Multi-Version Concurrency Control) 기법과 애플리케이션 레벨에서는 충돌이 발생하지 않을 것이라고 가정하고 커밋 되는 순간 충돌을 감지함으로써 성능을 개선시키는 낙관적 동시성 제어 기법(optimistic locking)이 있다.
- MVCC는 많은 충돌을 가정하기 때문에 동시에 수행되는 여러 트랜잭션들 사이의 충돌을 줄여준다. 그러나 저장 공간을 더 써야한다는 단점이 있다.
- 낙관적 동시성 제어는 적은 충돌을 가정하기 때문에 속도나 리소스 효율성에서 더 뛰어나지만 많은 충돌 발생시 성능 저하로 이어진다.
다중 리더인 경우에는 최종 쓰기 승리(last write win)와 같은 수렴 방식으로 최종 값을 정한 다음 최종 일관성(Eventual Consistency)을 유지하여 충돌을 해소시켜 주는 방법도 있다. 대표적으로 카산드라에서 타임스탬프를 통해 해당 방법을 사용한다. 하지만 이는 여러 쓰기 작업을 하나의 쓰기로 수렴하는 것이기 때문에 모든 유저 쓰기의 지속성을 지키지는 못한다는 단점이 있다.
예를 들어, 가족 요금제의 데이터 사용량 90%가 넘는 경우 초과 요금 부담되는 알림을 발송해야 한다. 가족은 먼 여러 지역에 분포해 있으며 각 지역에는 고객의 데이터 사용량 세부 정보가 포함된 복제된 데이터가 있다. 각 지역마다 개별 사용량을 업데이트해야 하며, 언제든지 총 사용량을 모니터링할 수 있다.
- 클라이언트 간의 시간 차이가 너무 크다면, 나중에 발생한 쓰기 작업이 이전 쓰기 작업보다 먼저 도착할 수 있다. 이전 쓰기 작업이 누락될 수 있다. 그러면 90% 초과하더라도 제때 알림 발송을 못하게 된다.
- 이벤트를 순서화하여 최종을 정의하기 위해서는 모든 노드의 타임스탬프를 동기화해야한다.
- 동시에 값이 변경하더라도 하나의 값으로 수렴을 보장해주는 CRDT(Conflict-free replicated data type)라는 데이터 구조를 사용하는 방법도 있다.13
마무리
이번 글에서는 데이터 일관성를 중점으로 여러 이야기를 다뤄보았다. 원래는 일관성 문제에 합의까지 다루려고 했지만 중간에 로컬 트랜잭션과 분산 트랜잭션에 대한 내용을 추가하여서 호흡이 길어지는 바람에 합의는 다음으로 미뤘다. 지금까지 내용을 정리하면 다음과 같다.
- 복제 지연에서 발생하는 읽기 일관성 문제는 애플리케이션 레벨에서 요청 라우팅 설정이나 상태를 보관하는 방식으로 처리할 수 있다.
- 기존에 늘 알던 ACID 특성을 가진 로컬 트랜잭션과 분산 시스템에서 이뤄지는 분산 트랜잭션 모두 일관성과 신뢰성을 지켜주는 중요한 개념이다. 다만 분산 환경은 비결정론적 요소(네트워크 장애, 시스템 결함)등이 많아서 더 복잡하다.
- 그래서 분산 시스템에서 일관성을 유지하기 위해서는 신뢰없는 네트워크, 시계, 프로세스(or 쓰레드)를 두고 계속 씨름을 해야 한다.
- 분산 트랜잭션 기법으로 2PC, Saga 패턴이 있고, 충돌 회피, 충돌 감지 및 해결(lww) 전략 등 개념을 인지하여 상황에 맞게 적절한 선택을 해야 한다.
탈중앙화된 디지털 금융 시스템을 구축하는 블록체인에서는 실제로 돈을 주고받는 거래내역을 저장하는 시스템이라서 높은 신뢰도를 갖고 있어야 한다. 현재 금융 서버는 이러한 신뢰도를 이루기 위해 단일 서버 구조를 택한 사례도 있지만 블록체인은 분산된 탈중앙화된 형태로 그러한 단일 구조를 갖지 못한다. 그래서 사용하는 것이 합의 알고리즘이다. 블록체인 뿐만 아니라 Kafka나 Cassandra와 같은 대규모 데이터를 처리하기 위해 설계된 시스템에서도 주로 사용되고 있다. 그러한 합의 알고리즘에 대해 추후 다뤄볼 예정이다.
resources
- Jinyang, L. (2009). Distributed systems and consistency. New York University [본문으로]
- PostgreSQL. Write-Ahead Logging (WAL) [본문으로]
- 마틴 클레프만. 데이터 중심 애플리케이션 설계 [본문으로]
- NDC Conferences. (2021) 〈쿠키런: 킹덤〉 서버 아키텍처 뜯어먹기! [본문으로]
- REDO와 UNDO 동작 과정을 이해해보자 (지속성을 구현하기 위해) [본문으로]
- Jinyang Li. Distributed Systems. fa16-ds. 2pc. NYU [본문으로]
- usenix conference 2023. Distributed Transactions at Scale in Amazon DynamoDB: Figure2: Two-phase protocol. AWS DynamoDB [본문으로]
- PostgreSQL. 74.4. Two-Phase Transactions [본문으로]
- Mysql 8.0 Reference Manual. 13.3.8. XA Transactions [본문으로]
- Clemens Vasters. ETransactions in Windows Azure (with Service Bus) - An Email Discussion [본문으로]
- Chris Richardson, Microservice Architecture,https://microservices.io/patterns/data/transactional-outbox.html [본문으로]
- Toss SLASH. (2022) 왜 은행은 무한스크롤이 안되나요 [본문으로]
- Michael Brey. New Concepts in NoSQL: Introducing a conflict-free replicated data type. Oracle NoSQL Database [본문으로]