
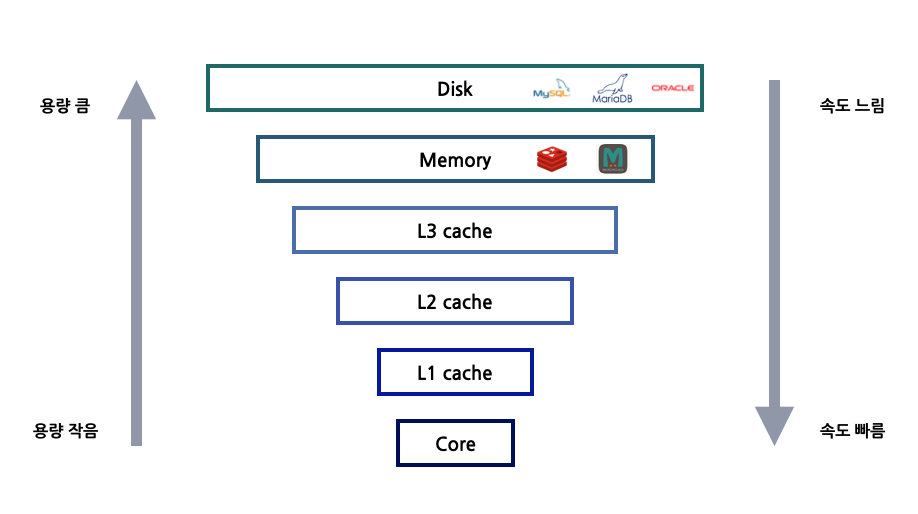
데이터베이스 저장소, 디스크 Disk
데이터베이스에서 데이터를 저장하고 관리하는 장치로 디스크를 가장 많이 사용한다. 디스크는 메모리 공간이 넉넉한 반면에 속도가 느리다는 단점이 있다. 그래서 메모리에 임시로 데이터를 저장하여 빠르게 읽어올 수 있는 캐시를 사용하여 웹 서비스 성능을 향상시키기도 한다. 메모리에 접근할 때는 나노초(ns)단위로 처리할 수 있으나, 디스크에 접근할 때는 밀리초(ms)단위의 시간이 필요하다. 사람 입장에서는 ms가 빠를 수도 있겠지만 컴퓨터 입장에서는 상대적으로 굉장히 느린 속도이다.
디스크 I/O 부분이 성능에 가장 영향을 미치는 요소이다. 보통 디스크 I/O는 데이터베이스에 데이터를 기록하고 기록된 정보를 찾아 꺼내오는 것을 말한다. DBMS 입장에서 보면 디스크 I/O는 반드시 필요한 기능이면서도 처리 시간을 최대한 단축시켜야 하는 부분이기도 하다.
어떻게 디스크 I/O 대기 시간을 줄일까?
메모리에 테이블의 데이터가 없으면 풀 스캔(Full Scan, 테이블의 모든 데이터를 읽어오는 것)할 때 시퀀셜 액세스가 발생한다. 시퀀셜(sequential) 액세스란? 'sequential'은 '순차, 순서를 따라서'라는 의미를 뜻한다. 그래서 시퀀셜 액세스는 시작점에서부터 마지막까지 중간 부분을 생략하지 않고 전부 액세스(읽기/쓰기)하는 것을 의미한다. 시퀄셜 액세스와 풀 스캔은 DB를 이해하기 위해 꼭 알아야 하는 중요한 개념이다.
인덱스 Index
이러한 디스크 I/O 성능 문제를 해결하고자 인덱스(index, 색인)이라는 개념이 나오게 되었다. 색인은 실생활에서도 쉽게 접해볼 수 있는 개념이다. 흔히 책에서 찾아볼 수 있는 색인은 키워드가 순서대로 나열되어 있으며, 해당 페이지도 함께 기재되어 있다. 그 페이지 번호를 이용해서 원하는 페이지를 빠르게 찾은 후 필요한 정보를 얻어낼 수 있다.
데이터베이스 인덱스도 마찬가지이다. 데이터베이스 인덱스에는 검색할 때 사용하는 키 값(SQL문의 WHERE절에 적는 조건의 값)과 그 키가 존재하는 있는 위치가 기록되어 있다.
- 데이터 = 책의 내용, 인덱스 = 책의 목차, 물리적 주소 = 책의 페이지 번호
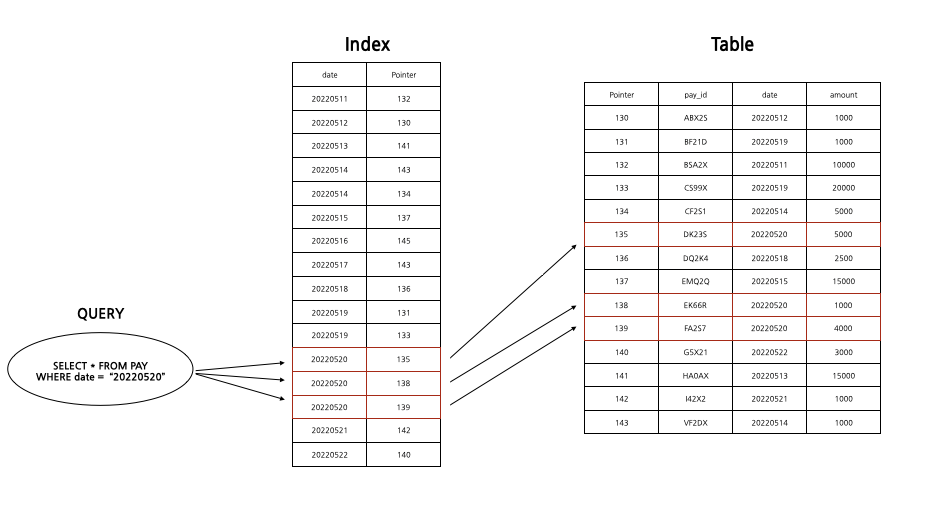
인덱스 사용 예
가계부에서 5월 20일에 사용한 결제 내역을 정보를 모두 찾아보고 싶을 때 해당 요일에 기록된 장부를 펼쳐보면 된다. SQL문도 마찬가지로 WHERE절에 date = "20220520"에 기록된 가계부 내역을 찾고 싶다는 것을 작성하고 SELECT 절에 알고 싶은 항목을 적는다.
SELECT * FROM Pay WHERE date ='20220520';
인덱스를 사용해서 이 SQL문을 처리할 때는 우선 'date'가 기록되어 있는 인덱스를 조사한다. 그 결과 pointer(talbe 저장된 위치, rowid)를 알아낼 수 있고 그 주소를 토대로 데이터를 읽을 수 있다.
장점
인덱스의 장점은 테이블 검색을 빠르게 진행하여 디스크 I/O 부분 성능을 향상시켜 준다는 점이다.
단점
단점으로는 인덱스를 관리하는 추가적인 작업과 그만한 공간이 필요하다. 그리고 update(수정/ 삭제)가 빈번하게 일어나는 컬럼에 인덱스를 사용하면 데이터의 인덱스를 제거하는 것이 아니라 '사용하지 않음'으로 처리하고 남겨두기 때문에 오히려 배보다 배꼽이 커질 수도 있다. 그리고 조회 범위(15~25% 이상)를 잘못 설정하는 경우 오히려 성능을 저하시키기도 한다.
인덱스 자료구조, B+ 트리
B-Tree는 어느 한 데이터 검색에는 효율적이지만, 모든 데이터를 순회하는 데에는 트리의 모든 노드를 방문해야 하므로 비효율적이다. 이러한 단점을 커버하여 B+Tree를 사용한다. 그러나 B+Tree가 항상 좋은 퍼포먼스를 보이는 것은 아니다. B+Tree는 B-Tree에 비해 검색 속도와 접근성을 높이지만 업데이트와 삭제와 관련해서는 오히려 B-Tree보다 불리하다.
B+ 트리(Quaternary Tree라고도 알려져 있음)는 키에 의해서 각각 식별되는 레코드의 효율적인 삽입, 검색과 삭제를 통해 정렬된 데이터를 표현하는 자료구조이다. 이는 동적이며, 각각의 인덱스 세그먼트 (보통 블록 또는 노드라고 불리는) 내에 최대와 최소 범위의 키의 개수를 가지는 다계층 인덱스(multilevel index)로 구성된다. B트리와 대조적으로 B+트리는, 모든 레코드들이 트리의 가장 하위 레벨에 정렬되어있다. 오직 키들만이 내부 블록에 저장된다.
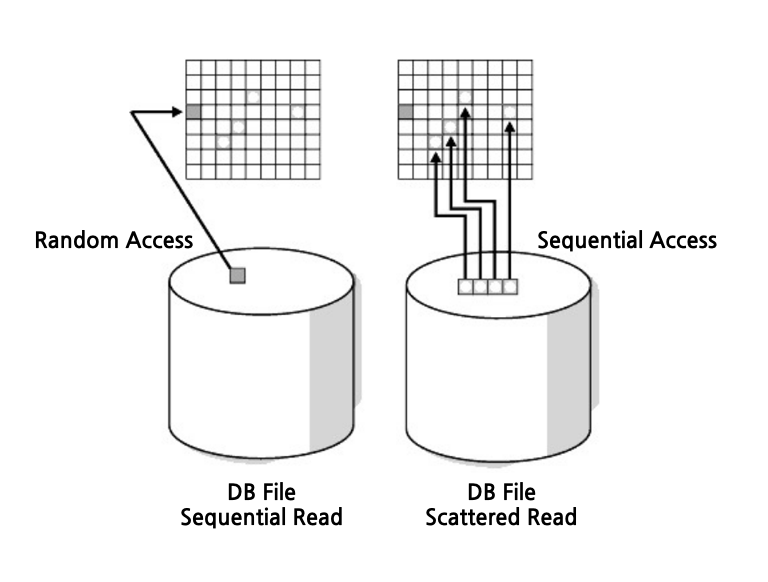
인덱스의 접근 방식, 랜덤 액세스 Random Access
인덱스를 사용할 때는 필요한 부분만 읽어오면 충분하지만, 필요한 부분이 디스크 위에 연속적으로 존재하는 경우는 거의 없다. 따라서 헤드를 움직여가면서 띄엄띄엄 접근하는 랜덤 액세스(Random Access) 방식을 사용한다. 이는 시퀄셜 액세스와 반대의 의미가 있다. 디스크 관점에서 생각해보면 랜덤 액세스는 비효율적인 부분이 존재한다. 탐색하는 작업과 회전 대기로 인해 데이터에 띄엄띄엄 접근할 때마다 어쩔 수 없이 시간이 소모되기 때문이다.
예로 블록 크기를 8KB, 1초에 탐색할 수 있는 횟수를 100회라고 가정한다면 1초 동안 가져올 수 있는 데이터는 800KB이다. 위에서 예시를 들은 디스크 전송 속도 20MB/s 데이터를 탐색하지 않고 한 번에 가져올 수 있는 20MB에 비하면 \(1\over25\)에 불과하다. 이를 음악 플레이리스트 듣기와 비교한다면 음악 첫 부분을 찾아가는 것을 빈번하게 반복하다보니 한 시간 중 3분 정도 밖에 음악을 듣지 못한 것고 비슷한 맥락이다. 남은 57분 동안 그 부분을 찾느라 낭비한 셈이다.
시퀀셜 액세스 vs 랜덤 액세스
이 두 개념은 헷갈리기 쉬운 부분이 있다. 오라클에서는 시퀀셜 액세스는 'db file scatterd read'라고 표시되며, 랜덤 액세스는 'db file sequential read'라고 표시된다. 'scatterd'는 '분산됐다'라는 의미를 가지고 있으며, 'sequental'은 '순차적인, 연속적인'라는 뜻을 가지고 있다. 이는 잘못된 표기가 아니며 다음과 같은 의미가 있다.
오라클은 블록 단위로 데이터를 읽고 쓰며, 메모리에 배치해둔다.
- 시퀀셜 액세스는 '순차로 읽는다'라는 의미로, 여러 블록을 한꺼번에 빠짐없이 읽어온다. 이때 읽어온 여러 블록들은 메모리상에 연속되지 않은(분산된) 형태로 놓인다. 따라서 'scatterd'라고 표현하는 것이다.
- 그에 반해 랜덤 액세스에서 읽어오는 데이터 블록은 한 번에 한 개이며, 메모리 공간에 반드시 연속적으로 놓인다. 따라서 'sequential'이라 표현한다.
- 한번 읽어온 블록을 메모리에 어떻게 배치하는지에 따라 표현하는 방법을 다르게 한 것이다.
인용: 오라클 구조 - 인덱스를 사용하는 것은 전체 데이터의 15%?
인덱스를 사용하는 것이 유리한 경우는 필요한 데이터가 전체 데이터의 15%미만인 경우라는 이야기가 있다.
그 이유는 시퀀셜 액세스와 랜덤 액세스의 특성에 있다. 테이블의 데이터가 대량이고 그중 한 개의 로우(행)를 꺼내야 한다면 당연히 인덱스를 통한 액세스가 빠르다. 그에 비해 모든 데이터를 보려고 할 때 매번 인덱스를 찾은 후 데이터를 찾아가면 오히려 속도가 느려진다. (책을 읽을 때 내용 순서대로 읽지 않고 색인을 일일이 찾아가면서 보는 것과 같다.)
만약 데이터가 50%라면 어떨까? 여기서 중요한 점은 '디스크에서의 랜덤 액세스는 데이터를 읽어오는 효율성이 시퀀셜 액세스보다 떨어진다'라는 특성이다. 예를 들어, 테이블에 2만 건인 데이터가 저장되어 있다고 하고 그중 절반인 1만 건을 꺼낸다고 해보자. 여기서 한 로우는 8KB이다.
- 지금까지 사용한 지표로 성능을 측정해보면 랜덤 액세스로 약 20초(800KB/s*100 = 80MB)가 걸린다. (인덱스는 빈번하게 사용되므로 캐싱되어 있다고 가정.)
- 그것과 비교하면 2만 건 전부를 읽어오는 시퀀셜 액세스는 모든 데이터(2만 건)을 모두 읽어온다고 해도 약 8초(25MB/s*8 = 160MB)면 끝난다.
즉, 디스크 특성상 모든 데이터가 아니더라도 일정 크기 이상의 데이터를 읽는다면 시퀀셜 액세스를 사용하여 테이블을 풀 스캔하는 편이 빠르다. 단, 실제로는 캐시에 데이터가 보관된 경우가 있으며, 한 개의 블록에 여러 로우의 데이터가 보관되어 있어서 1회의 I/O로 많은 데이터를 읽을 수 있는 경우도 있다. 더욱이 인덱스의 데이터를 디스크에서 읽어 와야 하는 경우도 있으므로 '15%가 임계치'라고 단순하게 말할 수 는 없다. 어디까지나 대략적인 기준이다. 이렇게 세세한 부분은 앱 서비스 성질에 따라 성능을 직접 비교해가며 최적화를 이루는 것이 좋다.
인용: Real MySQL 8.0
전체 100만 건의 레코드 가운데 50만 건을 읽어야 하는 작업은 인덱스의 손익 분기점인 20~25%보다 훨씬 크기 때문에 MySQL 옵티마이저는 인덱스를 이용하지 않고 직접 테이블을 처음부터 끝가지 읽어서 처리할 것이다.
참고
스기타 아츠시 외 4인 - 오라클 구조
Real MySQL 8.0
'Dot Database > Concept' 카테고리의 다른 글
| Database Index 탐구: Hash, B+-Tree, LSM Tree (0) | 2023.01.29 |
|---|---|
| [DB] 캐싱과 캐싱 전략에 대해 알아보자 (0) | 2022.04.13 |
| [DB] REDO와 UNDO 동작 과정을 이해해보자 (지속성을 구현하기 위해) (0) | 2021.10.27 |
| [DB] 대기와 Lock에 대해 알아보자 (0) | 2021.10.24 |
| [DB] RDB 데이터 구조에 대해 알아보자 (0) | 2021.10.24 |



