
Garbage Collection 이후 Heap의 Fragmentation
Garbage Collector는 이 문제를 현재 사용하고 있지 않는 Object로 Garbage를 판단한다. 그리고 현재 사용 여부는 바로 Root Set과의 관계로 판단한다. 다시 말해 Root Set에서 어떤 식으로든 Reference 관계가 있다면 Reachable Object라고 한다. 이것을 현재 사용하고 있는 Object로 간주하게 된다. Root set이 참조하는 정보는 다음과 같다.
- Stack의 참조(Ref) 정보
- Constant Pool에 있는 참조(Ref) 정보
- Native Method로 넘겨진 객체 참조(Ref) 정보
GC는 보통 메모리의 압박이 있을 때 수행된다. 어떤 이유에서든지 메모리가 필요하면 수행한다는 뜻이다. GC는 새로운 Object의 할당을 위해 한정된 Heap 공간을 재활용하려는 목적으로 수행되는 것이다. 재활용을 위해 수행된 메모리의 해지는 할당한 그 자리에서 이루어지기 때문에 Garbage가 빠져 나간 자리는 듬성듬성할 수 밖에 없다. 이 경우 메모리의 개별 Free Space의 크기 보다 큰 Object에게 공간을 할당할 경우 재활용은 의미가 사라진다.
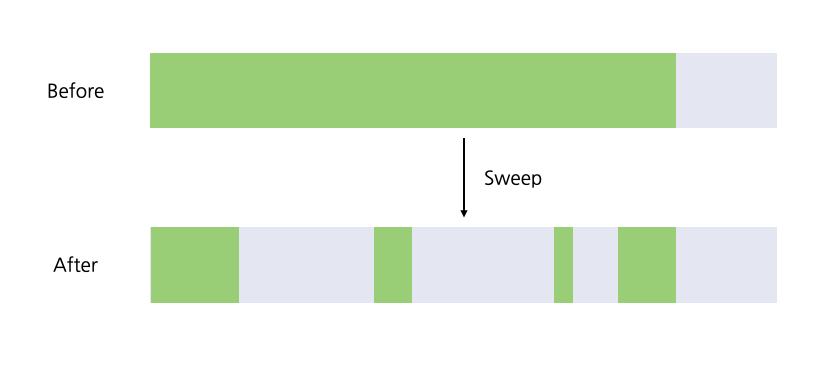
다음 그림을 보면 Garbage Collection 이후 Free Memory는 6KBytes 정도가 확보되었다. 그렇다고 여기에 5Kbytes 크기의 할당이 가능할까? 답은 그렇지 못하다는 것이다. 이러한 현상을 Heap의 단편화(Fragmentation)라고 한다. 이러한 현상을 방지하기 위해 각 Garbage Collector는 Compaction과 같은 Algorithm을 사용하고 있다.
Garbage Collection의 기본 Algorithm
Hotspot이나 IBM에서 구현한 GC Algorithm을 이해하기에 앞서 기본적인 Algorithm을 먼저 공부해보자. 다음 5가지의 Algorithm은 GC의 동작 원리를 이해하는 핵심이다. 그리고 이를 이해한다면 JVM에서 구현해 낸 GC이 어떻게 돌아가는 지에 대한 감을 쉽게 잡을 수 있다.
- Reference Counting Algorithm
- Mark-and-Sweep Algorithm
- Mark-and-Compacting Algorithm
- Copying Algorithm
- Generational Algorithm
- Train Algorithm
GC 알고리즘은 두 가지로 나뉜다.
- Garbage 객체 찾기
- Garabage 객체 제거하기
초기의 GC 알고리즘은 1번 객체를 찾는데에 집중하다가 점차 Heap Memory를 어떻게 재활용하는가에 초점이 맞추어지고 있는 것을 볼 수 있을 것이다. 차례대로 알아보자.
1. Reference Counting Algorithm
Reference Counting 알고리즘은 Detection에 초점이 맞추어져 있다. 기본 아이디어는 각 Object 마다 Reference Count를 관리하여 Reference Count를 관리하여 Reference Count가 0이 되면 그때마다 GC를 수행하는 것이다.
그래서 Object에 Reference가 되면 Count를 증가하고 Reference가 사라지면 Count를 감소한다. 그런데 이 Reference 관계가 간접적이라 하더라도 참조하고 있는 모든 Object에 대해 연쇄적으로 Reference Count가 변경된다.
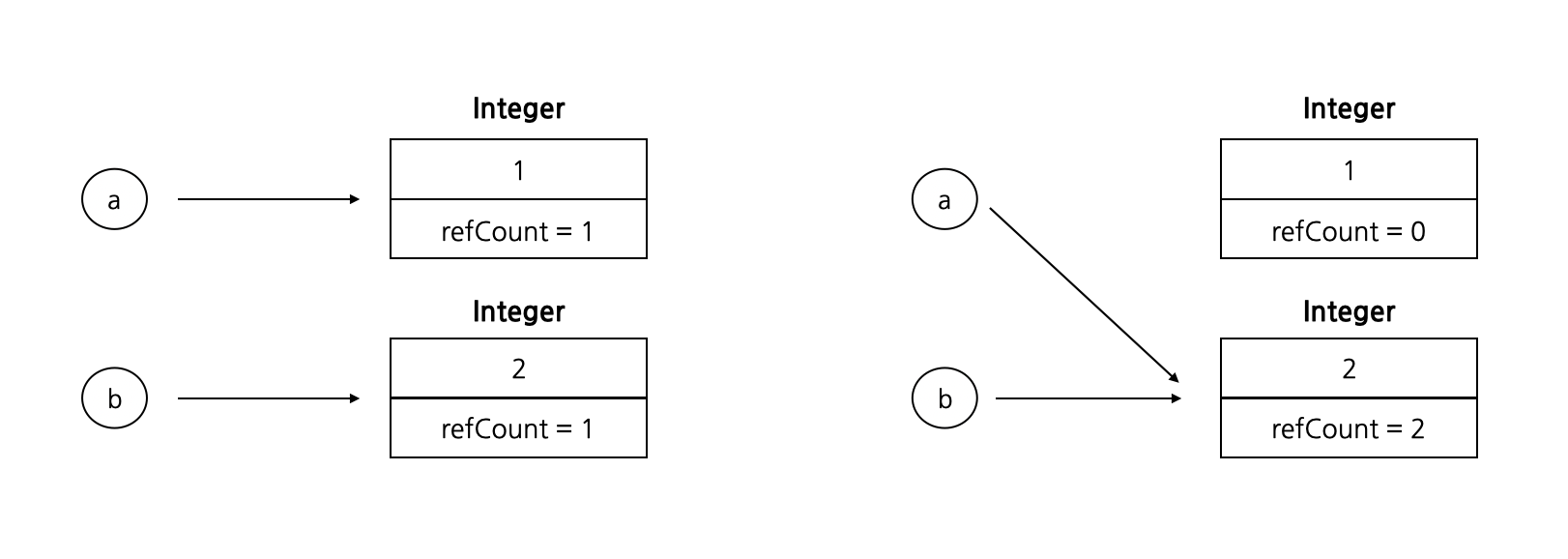
Object a = new Integer(1);
Object b = new Integer(2);
a = b;
다음 코드의 경우 1이라는 값을 가진 Integer 객체와 2라는 값을 가진 Integer 객체가 생성되고 각 Reference Count는 1이 된다. 그런데 a = b; 와 같이 a에 b의 ref를 복사하는 작업을 하게 된다면 2값을 가진 Integer 객체의 Reference Count는 0이 되고 Root Set과의 관계가 끊어지게 된다. 그래서 해당 객체는 GC의 대상이 되어 제거된다.
장점
해당 알고리즘은 Garbage 객체를 확인하는 작업이 너무 간단하다. 그리고 Reference Count가 0이 될 때마다 GC가 발생하기 때문에 자연스럽게 Pause Time이 분산되어 실시간 작업에도 거의 영향을 주지 않는 장점이 있다.
단점
그러나 Reference 변경이나 GC의 결과에 따라, 각 Object의 Reference Count를 변경해 주어야 하기 때문에 이에 대한 관리 비용이 상당하다. 또한 GC이 연쇄적으로 일어날 수 있다는 것도 문제가 될 수 있다.
무엇보다 해당 알고리즘의 문제는 Memory Leak의 가능성이 농후하다는 데 있다.
다음 Linked List에서 각 Object가 다음의 Object를 참조하고 마지막 Object는 가장 처음의 Object를 참조하는 순환구조를 가지고 있다. 만약 RootSet에서의 참조가 사라지게 되면 어떻게 될까? Root Set과 관계있는 직접적인 Object만 GC의 대상이 되고 그 외에 Object는 큰 변화가 없다. 이는 결국 Garbage가 되어도 Heap에 사라지지 않고 Memory Leak을 유발하게 된다.

2. Mark-and-Sweep Algorithm
Tracing 알고리즘이라고 불리는 Mark-and-Sweep 알고리즘은 이전의 Reference Counting 알고리즘의 단점을 극복하기 위해 나왔다고 볼 수 있다. 이 알고리즘은 Reference에 따라 Object 마다 Count를 하는 방식대신, Root Set에서 시작하는 Reference의 관계를 추적하는 방식을 사용한다.
- 해당 Mark 방식은 Detection에 상당히 효과적이기 때문에 이후 여러 GC 알고리즘에서 대부분 해당 탐색 기법을 사용한다.
해당 알고리즘은 Mark 단계와 Sweep 단계로 나뉜다.
Mark 단계에서는 Garbage 객체를 구별해 내는 단계로 Root Set에서 Reference 관계가 있는 Object에 Marking 하는 방식으로 수행된다. Marking을 위해서는 여러 가지 방법이 있는데 주로 Object Header에 Flag나 별도의 Bitmap Table 등을 사용한다.
Mark 단계가 끝나면 곧바로 Sweep 단계로 돌입한다. 이 단계는 Marking 정보를 활용하여 Marking이 되지 않은 Object를 지우는 작업을 한다. Sweep이 완료된 후에는 모든 Object의 Marking 정보를 초기화한다.
장점
이 Mark-and-Sweep 알고리즘은 Reference 관계가 정확하게 파악될 뿐만 아니라, Reference 관계의 변경 시에 부가적인 작업을 하지 않기 때문에 속도가 향상된다는 장점이 있다.
단점
그러나 GC 과정 중에는 Heap의 사용이 제한된다. 그것은 Mark 작업의 정확성과 Memory Corruption을 방지하기 위함인데 이 경우 프로그램이 잠깐 멈추는 현상(Suspend)가 발생한다.
또 하나의 문제는 바로 Fragmentation이다. Sweep 단계에서 GC 이후 Heap의 Garbage가 빠져 나가 듬성듬성한 상태로 사용을 하게 된다. GC가 계속해서 수행된다면 정도가 더 심해져 Free Memory가 있는 것 처럼 보이지만 Fragmentation에 의해 할당이 불가능한 상황이 되어 OutOfMemoryException이 유발 될 수 있다.
- 이러한 단점을 보완하기 위해 Mark-and-Compacting 알고리즘과 Copy 알고리즘이 등장하게 된다.
3. Mark-and-Compacting Algorithm
Mark-and-Sweep Algorithm이 가지고 있는 Fragmentation이라는 약점을 극복하기 위해 나온 Algorithm이다. Sweep 대신 Compact라는 용어를 사용하지만 Sweep이 사라진 것은 아니고 Compaction 과정에 Sweep이 포함되어 있는 구조이다. 즉, Mark 단계와 Compaction(Sweep + Compact) 단계로 나눠진다고 보면 된다.
Compaction이란 작업은 말 그대로 Live Object를 연속된 메모리 공간에 차곡차곡 적재하는 것을 의미한다. 보통 하위 Address로 Compaction을 수행한다. 이는 여러가지 방식이 있다.
- Arbitrary: 순서가 보장되지 않음. 무작위로 진행.
- Linear: Ref 순서대로 정렬되는 방식. Ref 순서를 따지는 데에 Overhead가 발생할 수 있음.
- Sliding: 할당된 순서로 정렬되는 방식. 가장 좋은 방식으로 알려짐.

장점
해당 알고리즘은 Fragmentation의 방지에 초점이 맞추어져 있기 때문에 메모리 공간의 효율성이 가장 큰 장점이 된다.
단점
그러나 Compaction 작업 이후에 모든 Reference를 업데이트 하는 작업은, 경우에 따라서 모든 Object를 Access하는 등의 부가적인 Overhead가 수반될 수 있다. 또한 Mark 단계와 Compaction 단계는 모두 Suspend 현상이 발생한다는 단점도 가지고 있다.
4. Copying Algorithm
Fragmentation의 문제를 해결하기 위해 제시된 또 다른 방법은 바로 Copying 알고리즘이다. 이 Algorithm은 Heap을 Active 영역과 Inactive 영역으로 나누어 사용하는 특징을 가지고 있다. 이중 Active 영역에만 Object를 할당 받을 수 있고 Active 영역이 꽉 차게 되어 더 이상 Allocation이 불가능하게 되면 GC가 수행된다. GC가 수행되면 모든 프로그램은 일단 Suspend 상태가 되고 Live Object를 Inactive 영역으로 Copy하는 작업을 수행한다. Stop-the-Copying이라고 부르는 이유도 이렇게 Copy를 할 때 Suspend가 되기 때문이다.
Copy 작업이 끝나면 Actvie 영역에는 Garbage 객체만 남게 되고 Inactive 영역에는 Live Object만 남아있게 된다. 그런데 Inactive 영역에 Object를 Copy 할 때는 한 쪽 방향에서부터 차곡차곡 적재를 하기 때문에 마치 Compaction을 수행한 것처럼 정렬이 된 상태이다. 이렇게 GC가 완료되는 시점에서 Active 영역은 모두 Free Memory가 되고 Active 영역과 Inactive 영역은 서로 바뀌게 된다. 이를 Scavenge라고 한다.
Active와 Inactive 영역은 특정 메모리 번지 구간을 지칭하는 것이 아니고 현재 Allocation을 하면서 사용하는 공간이 Active이고 다른 대기 공간은 Inactive이 되는 논리적인 구분인 셈이다.

장점
해당 알고리즘은 Mark-and-Compacting 알고리즘과 마찬가지로 Fragmentation의 방지에 초점이 맞추어져 있기 때문에 메모리 공간의 효율성이 가장 큰 장점이 된다.
단점
그러나 전체 Heap의 절반 정도를 사용하지 못한다는 단점이 존재한다. 또한 Suspend 현상과 Copy에 대한 Overhead는 필요악이라고 할 수 있을 것이다.
5. Generational Algorithm
Copying 알고리즘을 사용하면서 대부분의 프로그램에서 생성되는 대다수의 Object는 생성된 지 얼마 되지 않아 Garbage가 되는 짧은 수명을 가지고 있다는 점과 그렇다고 해서 모든 Object가 그런 것이 아니라 수명이 긴 몇 개의 Object도 반드시 가지고 있다는 사실을 경험적으로 체득하였다. 그리고 이러한 Long Lived 객체의 경우 Inactive, Active를 계속 왔다갔다 하면서 Copy 작업을 계속해서 이뤄지게 되는 데 그러한 Overhead도 만만치 않다는 사실도 체득한 지식 중 하나였다.
위와 같은 경험을 통해 나온 가설이 Weak generational hypothesis이다.
- High Infant Mortality: Object는 대부분 새로 생겨난 후 얼마 되지 않아 Garabage가 된다. 그렇기 때문에 새로 할당되는 Object가 있는 곳에 Fragmentation이 발생 확률이 높다.
- 오래된 객체가 젋은 객체를 참조하는 일은 상당히 드물다. 이는 가볍게 생각하는 Minor GC가 정말로 가볍게 유지되기 위해서 매우 중요한 요소이다.
해당 가설을 토대로 Copying 알고리즘 대안으로 Generational 알고리즘이 나오게 되었다. 그래서 이 알고리즘은 Copying 알고리즘의 연장선상에 있다.
- Heap을 Active, Inactive로 나누는 것이 아닌 Age 별로 몇 개의 Sub Heap으로 나눈다. 생성된 객체는 Young 영역으로 할당되고 성숙하게 되면 다음 세대에 해당하는 Old 영역으로 간다. Age가 임계값을 넘어 다음 세대로 Copy 되는 것을 Promotion이라고 한다.

장점
Generational 알고리즘은 Fragmentation이나 메모리의 활용, 그리고 Copy Overhead 등의 각 지점에서 지니고 있던 단점을 상당 부분 극복한 알고리즘이다. 무엇보다 이 알고리즘의 장점은 Sub Heap에서 각각 적절한 알고리즘을 적용할 수 있다는 것이다. 위 그림에서도 Young Heap에서는 Mark-Sweep 알고리즘을 사용하였고 Promotion 과정에서는 Copying 알고리즘과 흡사하게 진행되었다. 이러한 장점으로 인해 Hotspot JVM도 해당 알고리즘을 바탕으로 Heap을 구성하고 있다.
- Young, Old 각 영역을 따로 관리하므로 적은 비용과 시간으로 Garbage 객체 추적이 가능하다.
- Copying이 진행되면서 Compaction도 이루어지기 때문에 Framentation 문제도 해결된다.
Java 8 HotSpot JVM 구조는 다음과 같다.
<----- Java Heap -----> <--------- Native Memory --------->
+------+----+----+-----+-----------+--------+--------------+
| Eden | S0 | S1 | Old | Metaspace | C Heap | Thread Stack |
+------+----+----+-----+-----------+--------+--------------+
6. Train Algorithm
Tracing 알고리즘(2~5번)이 등장한 이후 GC를 수행할 떄 프로그램에 Suspend 현상이 나타나는 것은 감수할 수 밖에 없는 일이었다. 오히려 GC의 목적은 메모리를 재사용하기 위한 것이기 때문에 이 목적에 충실하게 위해 메모리의 재사용에 집중했었을 것이라고 추측된다. 그러나 전반적인 자바 프로그램 성능에 고려해볼때 Suspend를 감수하는 것은 좋지 않다. WAS와 같이 짧은 트랜잭션을 처리하는 시스템의 경우 불규칙적인 Suspend 현상은 사용자에게 불쾌감을 주어 비즈니스에도 악영향을 끼친다.
이러한 배경으로 Train 알고리즘이 나온 듯 하다. 이는 Heap을 작은 Memory Block으로 나누어 Single Block 단위로 Mark 단계와 Copy 단계로 구성된 GC를 수행한다. 이러한 특징으로 해당 알고리즘은 Incremental Algorithm 이라고도 한다.
GC를 수행하는 단위가 Single Block인 만큼 전체 Heap의 Suspend가 아닌 Collection 중인 Memory Block만 Suspend가 발생한다. 다시 말해 Suspend를 분산시켜 전체적인 Pause Time을 줄이자는 아이디어인 것이다.

Train 알고리즘은 Heap을 Train으로 구성한다. 이 Train은 Car(객차)라고 불리는 Fixed Size의 Memory Block을 묶어 놓은 체인이다.
- Train은 필요에 따라 Car를 추가할 수도 있고 하나의 Train이 추가 될 수도 있다.
- 각 Memory Block은 Car 외부에서의 참조를 기억하는 Remember Set이 있다.
- 이러한 구조로 Train이라는 명칭을 사용하게 되었다.
Copy나 Compaction을 통해 Object가 이동을 하게 되면 당연히 그 주소가 변경될 것이고 이를 참조하는 Object들도 따라서 Reference가 변경되어야 한다. 그런데 객체는 자신이 참조하는 Ref 정보를 갖고 있지만 나를 참조하고 있는 객체 Ref에 대한 정보는 갖고 있지 못하다. 이에 대한 정보를 알기 위해서는 최악의 경우 Root Set과 객체의 모든 Ref 정보를 탐색해야 할 수 도 있다. 이렇게 되면 Train 알고리즘의 장점인 Suspend 분산 효과가 의미 없어진다. 이러한 부분을 해결해주는 방법이 Remeber Set에 대한 정보이다. Rember Set은 Write Barrier라는 장치를 동반하여 Ref 관계를 맺을 때 객체가 같은 Car에 있지 않을 경우 대상 객체의 Car에 있는 Remember Set에 기록을 하는 식으로 구성된다.
한번 예시를 통해 더 자세히 알아보자. 다음은 GC가 발생하기 전 상황이다. Train1의 Car 1-1에서 GC가 발생하려고 한다. Mark 작업을 통해 A,B 만 Reachable 객체이고, C는 Unreachable 객체임을 구별해내었다.

Car 1-1의 Live 객체는 Train3을 만들어 구출해낸다. Car 1-3으로 빼내는 것이 아닌 다른 Train으로 옮긴 이유는 Train 1에 남은 객체들이 순환참조를 이루기 있기 때문이다. 그러면 C 또한 외부참조를 갖고있기 때문에 Rescue 범위 안에 들어오게 된다. 만약 C가 Live 객체였다고 해도 Car1-3으로 옮기면 Copy 부담만 늘어난다.
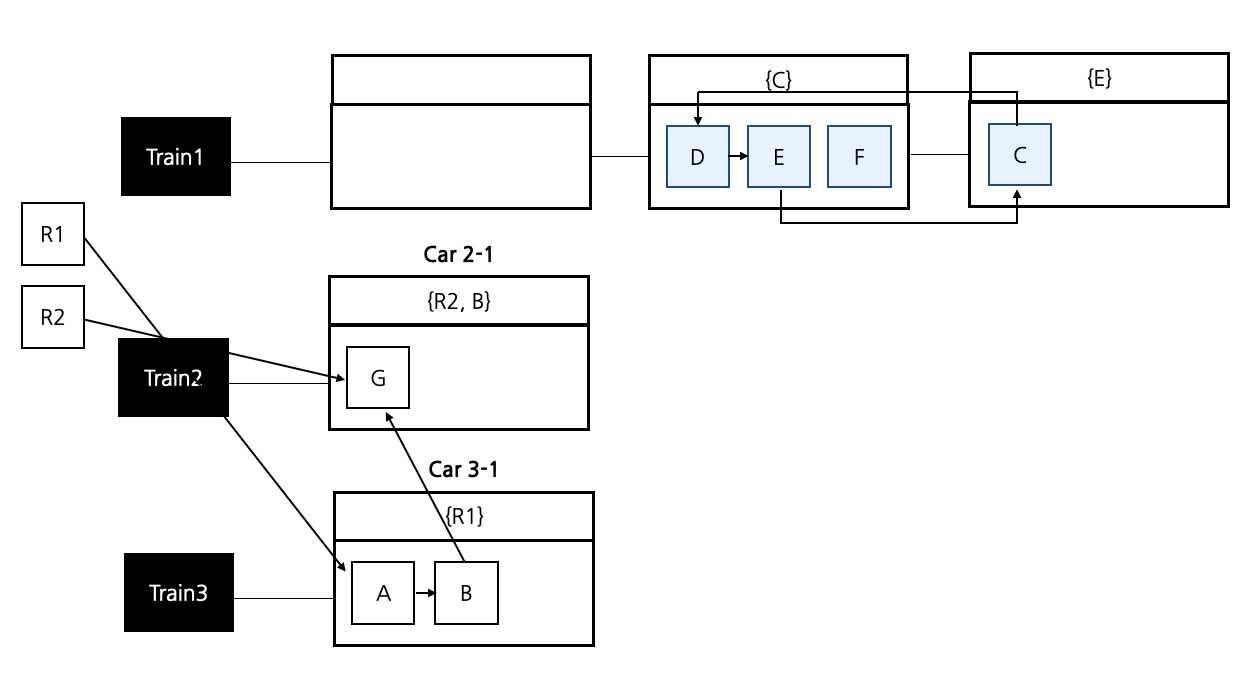
이제 GC를 수행하여 Car1-1이 비어있다는 사실과 D, E, F라는 Garbage 객체임을 알아낸다. 또한 Remember Set 정보로 C에서 E를 참조하는 것을 알아내어 순환 참조를 가지는 관계를 알아낸다. 그래서 별도의 Copy 작업없이 Car1-2, Car1-3을 Free Car로 변경한다. 이렇게 되면 Train 1은 Free Train으로 변경되어 사라지게 된다.

장점
해당 알고리즘은 Pause Time을 분산하여 장시간의 Suspend는 피할 수 있는 장점이 있다.
단점
그러나 개별 Suspend 시간을 모두 합산한 시간이 다른 Algorithm에 비해 더 많아질 수 있다는 문제점도 가지고 있다.
이러한 알고리즘을 토대로 만들어진 Garbage Collection 정리 글
Java garbage collection: The 10-release evolution from JDK 8 to JDK 18
Java Garbage Collection - naver d2
Java HotSpot VM G1GC (Java9 ~ 12 디폴트 GC) - 기계인간 John Grib
참고
Java Perfomance Fundamental - 김한도 저
https://medium.com/@joongwon/jvm-garbage-collection-algorithms-3869b7b0aa6f
'Dot Programming > Java' 카테고리의 다른 글
| JVM 4 - Garbage Collection 개념 및 대상 (0) | 2022.06.04 |
|---|---|
| JVM 3 - Runtime Data Area에서의 객체 생성, 소멸 및 참조 과정 알아보기 (0) | 2022.06.01 |
| JVM 2 - Runtime Data Area 구조 (0) | 2022.05.31 |
| JVM 1 - Java Architecture, JVM Specification (0) | 2022.05.31 |
| [Play with Java] Java 8로 꼬리재귀 함수 만들기 (Tail Recursion) (3) | 2022.04.10 |



