
Redis
Redis는 key-value 형태의 값을 저장할 수 있는 하나의 In-Memory DB이다. 사용 용도는 정말 다양하다. 스프링에서는 세션 클러스터링으로 사용하기도 하고 캐시를 위해 사용하기도 한다.
Redis를 캐시로 사용하기에 좋은 이유가 key-value로 데이터를 저장하면 되니 사용법도 간단하고 모든 데이터를 메모리에 올려두는 In-Memory DB이기 때문에 기존 RDS DB 대비 굉장히 빠르다. 평균 읽기 및 쓰기 작업 속도가 1ms미만으로 초당 수백만 건의 처리가 가능하다고 한다.
Redis 사용하는 방식
Remote Data Setroe
A, B, C 서버에서 데이터를 공유하고 싶을 때 Remote Data Store를 이용한다.
- 글로벌 캐싱: 여러 서버에서 한 캐시 서버에 접근하여 참조한다. 여러 서버에서 공통으로 공유해야 하는 정보를 담는 용도로 사용한다. 네트워크 트래픽을 사용해야 해서 로컬 캐시보다는 느리다.
Local Data Store
만약 서버 한대에서만 필요하다면 그냥 서버에서 전역 변수를 쓰면 되지 않을까라고 생각할 수 있지만 Redis 자체가 Atomic을 보장해주기 때문에 이를 사용하는게 좋다. 그리고 Redis는 Thread-Safe하고 Single Thread라서 이슈가 덜하다. 그래도 항상 안전한 것은 아니니 조심은 해야 한다.
- 로컬 캐싱: 서버마다 캐시를 따로 저장한다. 속도가 빠르다. 만약 여러 서버를 사용할 경우 데이터가 변경할 때마다 변경 사항을 전달해야 하므로 전혀 효율적이지 않다.
인증 토큰 저장
웹 서비스를 개발할 때 인증 토큰을 Redis에 저장하여 많이 사용한다. (Strings 또는 Hash)
Ranking 보드 사용
Sorted Set으로 랭킹 보드에서도 많이 사용한다.
유저 API Limit
Redis로 메세지 큐를 구현하여 rate limit 문제를 해결할 수 있다. (참고)
잡 큐(List)
celery나 이런데서 비동기 분산 큐 처리하는 것처럼 Redis에서도 List를 이용하여 잡 큐(Job Queue)로 사용할 수 있다.
Redis vs Memcached 캐시 기능 비교
Amazon ElastiCache는 Redis 및 Memcached를 제공한다. Memcached와 Redis는 모두 캐시 시스템으로서 동일한 캐시 기능을 제공하지만 여러 차이점이 존재한다. 그 중 대표적으로 다음 4가지를 꼽아봤다. (자세한 내용 참고)
1. 영속성 (Redis)
Memcached의 경우 데이터가 메모리에만 저장되기 때문에 프로세스가 재기동되면 메모리상의 데이터는 모두 유실된다. 하지만 redis의 경우 기본적으로 disk persistence가 설정되어있기 때문에, 프로세스를 재시작 하더라도 셧다운 되기 전의 마지막 상태와 거의 동일한 (약간의 손실은 있을 수 있다) 상태로 돌려 놓을 수 있다.
2. 멀티 스레드 (Memcached) vs 싱글 스레드 (Redis)
Memcached는 다중 스레드이므로 다중 처리 코어를 사용할 수 있다. 즉, 컴퓨팅 용량을 확장하여 더 많은 작업을 처리할 수 있다. Redis는 다중 처리가 어렵지만 싱글 스레드인데다가 자료구조 자체가 Atomic하기 때문에 Race Condition에서 유리하다.
3. Pub/Sub (Redis)
Redis는 고성능 채팅방, 실시간 댓글 스트림, 소셜 미디어 피드 및 서버 상호 통신에 사용할 수 있는 패턴 일치로 Pub/Sub 메시징을 지원한다.
4. 다양한 데이터 구조 (Redis)
Redis는 여기서 추가로 영속성, 다양한 데이터 구조(컬렉션)을 지원하고 있다. 라이브러리를 많이 제공해주는 프로그래밍 언어가 생산성이 좋은 것처럼 컬렉션이 있으면 개발의 편의성과 난이도가 달라지기 때문에 이 기능의 유무는 중요하다. 예를 들어 Redis Sorted Sets를 사용하여 순위별로 정렬된 플레이어 목록을 유지하는 게임 리더보드를 쉽게 구현할 수 있다. 다양한 데이터 구조가 주는 장점을 예제로 살펴보자.
4-1) 만약 랭킹 서버를 구현한다면? - 개발 편의성 증가
가장 간단한 방법은 DB에 유저의 Score를 저장하고 Score로 order by 정렬해서 읽어오는 방법이다. 그러나 이러한 방법은 개수가 많아지면 속도에 문제가 발생할 수 있다. 결국은 속도가 느린 디스크를 사용하기 때문이다.
그래서 In-Memory 기준으로 랭킹 서버의 구현이 필요하다. 고수라면 직접 만들어도 되겠지만 보통은 Redis의 Sorted Set을 이용하면 랭킹 서버를 쉽게 구현할 수 있다. 추가로 Replication도 가능하다. 다만 가져다 쓰면 해당 서버는 Redis의 한계에 종속적이게 되기 때문에 주의해야 한다. 랭킹에 저장해야 할 id가 1개당 100byte라고 했을 때 천만명을 1G로 감당할 수 있으므로 메모리에 대해서도 큰 고민이 필요 없다.
- 10명 1k
- 10,000 명 1M
- 10,000,000명 1G
- ...
4-2) 친구 리스트 관리하기 - 개발 난이도 감소
친구 리스트를 만약 Key-Value 형태로 저장해야 한다면 다음과 같은 상황이 발생할 수 있다.
- 현재 A라는 친구 123이라는 Key(friend:123) 안에 A의 친구 리스트 목록이 있다.
- 거기다 1명은 B를 추가하겠다고 트랜잭션이 발생하고 다른 1명은 C를 추가하겠다고 트랜잭션이 발생하여 동시성 문제에 직면하게 된다.
| T1 | T2 |
| 1. 친구 리스트 friend:123을 읽는다. 2. friend:123의 끝에 친구 B를 추가한다. 3. 해당 값을 friend:123에 저장한다. |
1. 친구 리스트 friend:123을 읽는다. 2. friend:123의 끝에 친구 C를 추가한다. 3. 해당 값을 friend:123에 저장한다. |
트랜잭션은 기본적으로 ACID(원자성, 일관성, 고립성, 지속성)을 보장해서 다음과 같은 결과가 이뤄져야 한다.
| 시간 순서 | T1 | T2 | 최종 상태 |
| 1 | friend:123 읽기 | A | |
| 2 | 친구 B 추가 | A | |
| 3 | friend:123 쓰기 | A, B | |
| 4 | friend:123 읽기 | A, B | |
| 5 | 친구 C 추가 | A, B | |
| 6 | friend:123 쓰기 | A, B, C |
실제로는 위 같은 상황에서 다음과 같은 문제가 발생할 수 있다.
- Race Condition으로 동시성 문제를 해결하지 못한 상황이다.
- 아니면 컨텍스트 스위칭이 발생하여 A, B 상태가 되는 상황도 발생할 수 있다.
| 시간 순서 | T1 | T2 | 최종 상태 |
| 1 | friend:123 읽기 | A | |
| 2 | friend:123 읽기 | A | |
| 3 | 친구 B 추가 | A | |
| 4 | 친구 C 추가 | A | |
| 5 | friend:123 쓰기 | A, B | |
| 6 | friend:123 쓰기 | A, C |
그러나 Redis의 경우 자료구조가 Atomic하기 때문에 해당 Race Condition을 피할 수 있다는 장점이 있다.
- 물론 잘못 설계하면 발생할 수 있다. (빠르게 두 번 요청하면 데이터 두 개 발생 등)
이렇게 Redis 컬렉션을 제공해주기 떄문에 개발자는 비즈니스 로직에만 집중할 수 있다. 개발 시간을 단축시켜 생산성을 향상시키고 위와 같이 Atomic한 특성이 있어 Race Condition을 피할 수 있는 등 여러 문제를 줄여줄 수 있기 때문에 Collection이 중요하다.
인용: Charsyam's Blog
오직 캐시의 목적으로만 볼 때에 대한 그래서 AOF, RDB는 제외하고 이에 대해서 간단하게 얘기해볼려고 합니다.
[생산성<성능] 이면 Memcached, [생산성>성능] 이면 Redis라고 생각합니다. 이유는 데이터 스트럭처를 제공한다는 것은 개발자에게 엄청나게 편의성을 제공해주기 때문입니다.
왜 memcached는 predictable 하고 Redis는 unpredictable 한가? (많은 데이터가 set/get/del 될 때라는 가정하에)
- 이는 내부의 메모리 할당 구조의 차이 때문입니다.
- Redis는 필요한 크기 만큼에 대한 메모리를 할당해서 이를 사용합니다. 그런데 memcached는 slab 할당을 이용해서, redis 보다 이런 부분에서 조금 더 나은 성능을 보여줍니다.
- 이로 인해서 redis의 메모리는 좀 더 fragmentation 이 발생하기 쉽고, 이로 인해 memcached의 성능이 좀 더 predictable 하다고 할 수 있는 것입니다.
그런데, 이게 사실 그렇게 단순한 것만은 아닙니다. memcached의 경우는 4G 메모리를 할당하면, 데이터 영역만 4G이므로, 이를 관리하기 위해서 메모리를 더 많이 사용하게 됩니다. 이로 인해서 의도한 것 이상으로 메모리를 사용하게 됩니다. 그런데 Redis는 딱 전체 메모리를 설정한 것 만큼만 사용하게 됩니다.(기본은 무한대로 계속 사용합니다.) 이럴 경우, swap 확률이 덜해서, Redis가 좀 더 안정적인 성능을 보여줄 수도 있습니다. 다만 BGSAVE를 사용하면, 또 메모리 사용량이 늘어나게 됩니다.
그럼 이것만으로 끝일까요? Redis를 여러 대 사용한다면, 한 서버에 여러대의 Redis 인스턴스를 돌리게 되는데,( memcached 도 마찬가지입니다.) 다음과 같은 구조가 됩니다.

이렇게 되면 하나의 서버가 죽더라도 전체 데이터가 날라가지 않는 일부만 사라지거나, 문제가 적지만, AOF/RDB를 사용해야 한다면 성능상 문제가 발생할 수 있습니다. 즉, 간단한 캐시 레이어 하나를 설계하더라도, swap의 발생 가능성이 다양하고, 여러가지 의존관계가 생기게 됩니다. 그리고 이런 구조를 이해하는 것이 적절한 캐시 성능을 보장하게 됩니다.
- 강대명 개발자님 블로그 글 '[입 개발] memcached 는 predictable 하고 Redis는 unpredictable 하다.' 중
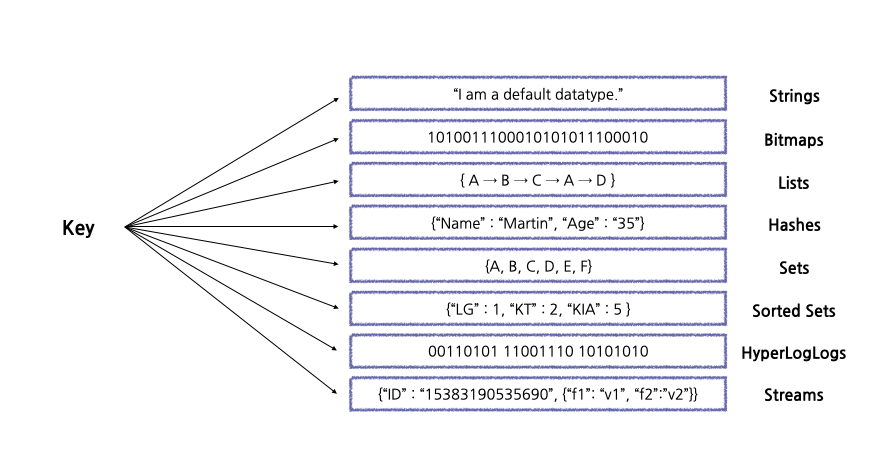
Redis 컬렉션 종류 (Redis data types)
Strings: 가장 기본적인 데이터 타입으로 기본 set 명령어를 사용하면 String 타입으로 저장된다.
- 단일 Key: SET, GET
- 멀티 Key: MSET, MGET
Bitmaps: String의 변형으로 볼 수 있음. Bit 단위로 연산 가능.
- BITOP, BITCOUNT, BITPOS
Lists: 데이터를 순서대로 저장하는 List 타입은 Queue로 사용하기에 적절하다.
- LPUSH, RPUSH, LPOP, RPOP, BLPOP(누가 데이터를 Push하기 전까지 대기)
Hashes: Hash는 하나의 키 안에 또 다시 여러 개의 field와 value 쌍으로 데이터를 저장한다.
- HMSET, HGET, HMGET, HINCRBY
Sets: 중복되지 않은 문자열의 집합
- SADD, SMEMBERS, SISMEMBERS(존재하면 1, 없으면 0)
Sorted Sets: Set처럼 중복되지 않은 값을 저장하고 score라는 숫자 값으로 정렬된다. 데이터가 저장될 때부터 score순으로 정렬되며 만약 score가 같을 경우 저장된 값의 사전순으로 정렬된다. (score는 double 타입이기 떄문에 값이 정확하지 않을 수 있다.)
- ZADD, ZRANGE (0 -1: 모든 범위)
HyperLogLogs: 굉장히 많은 데이터를 다룰때 주로 사용한다. 중복되지 않은 값을 카운트할 때 사용한다.
- PFADD, PFCOUNT
Streams: Log를 저장하기 가장 좋은 자료 구조이다.
- XADD, XGROUP, XLEN
Collection 주의 사항
- 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다. 10,000개 이하 몇 천개 수준으로 유지하는게 좋다.
- Expire는 Collection의 item 개별로 걸리지 않고 전체 Collection에 대해서만 걸린다. 즉 해당 10,000개의 아이템을 가진 Collection에 expire가 걸려있다면 그 시간 후에 10,000개의 아이템이 모두 삭제된다. Collection 일부 아이템에는 TTL을 걸 수 없으니 사용시 항상 주의하자.
Redis 컬렉션 적절한 사용법
1. Counting 하기
1) Strings
String은 단순 증감 연산을 사용하기에 적절하다. Redis에서 카운팅하기에 가장 쉬운 방법은 Key 하나를 만들어서 특정 조건마다 카운트를 해주는 방식이다.
- INCR / INCRBY / INCRBYFLOAT / HINCRBY / HINCRBYFLOAT / ZINCRBY
2) Bits
Bit를 이용해서도 카운팅이 가능하다.
- Bit를 사용하면 데이터 저장공간을 절약할 수 있다.
- 예를들어, 페이지 접속자 수를 카운트하려고할 때 날짜 Key 하나를 만들어 놓고 유저 id에 해당하는 bit를 1로 올려주는 것이다. 1bit = 1user이므로 천만명 유저가 접속한다고 해도 1.2mb밖에 차지하지 않는다.
하지만 이 방법을 이용하려면 모든 데이터를 정수로 표현할 수 있어야 한다. 즉 user id의 값이 0이상인 값일때만 카운팅이 가능하며 sequential한 값이 아닌 경우에는 사용할 수 없다.
3) HyperLogLogs
마지막 카운팅하는 방법은 HyperLogLogs를 사용하는 것이다.
- 이는 모든 스트림 데이터 값을 유니크하게 구분할 수 있다.
- 이는 set과 유사하지만 대량의 데이터를 카운팅할 때 적절하다. 왜냐하면 HyperLogLogs는 데이터 갯수 상관없이 기본 12kb가 고정되어 할당되기 때문이다.
- 한 번 저장된 값은 다시 불러올 수 없기 때문에 보호하기 위한 목적으로도 적절하다.
예를들어 웹사이트에 방문한 IP가 유니하게 몇 개나 되는지 하루종일 크롤링한 URL 개수가 몇 개인지 등 엄청 크고 유니크한 값을 계산할 때 적절하다.
2. Messaging
1) Lists
List는 Message Queue로 사용하기 적절하다.
- Blocking 기능을 제공하기 때문에 이를 적절히 사용하면 불필요한 Polling 프로세스를 막을 수 있고 Event Queue로 사용할 수 있다.
- LPUSHX, RPUSHX: 키가 있을 때만 List 데이터에 저장이 가능하다. 키가 있다는 것은 이전에 사용했던 큐라는 뜻으로 사용했던 큐에만 메세지를 넣어줄 수 있기 때문에 비효율적인 데이터 이동을 막을 수 있다.
RPUSHX 실무 사용 사례 (SNS 팔로우한 게시글 캐싱하기)
인스타, 페북, 트위터같은 sns는 각 유저별로 타임라인이 존재하고 그 타임라인에 각 유저가 팔로우한 사람의 게시글이 뜬다. 트위터에서는 각 타임라인에 보여줄 트윗을 캐싱하기 위해 Redis의 List를 사용하는 데 RPUSHX 커맨드를 사용한다. 이를 이용해서 트위터를 자주 이용하던 유저 타임라인에만 새로운 데이터를 캐시해놓을 수 있으며 자주 사용하지 않는 유저는 캐시에 키 자체가 존재하지 않기 때문에 그런 유저들을 위해 데이터를 미리 쌓아놓는 것과 같은 비효율적인 작업을 방지할 수 있다.
2) Streams
Stream은 log를 저장하기에 가장 적잘한 자료구조라 할 수 있다. 실제로 서버에 log가 쌓이는 것처럼 모든 데이터는 append-only 방식으로 저장되면 중간에 데이터가 변경되지 않는다.
> XADD mystream * sensor-id 1234 temperature 19.8
- mystream key를 저장
- *: id를 의미. *로 저장하면 redis가 알아서 데이터가 저장된 시간 값으로 저장 후 반환한다.
- 뒤로는 해시처럼 key-value 쌍으로 저장된다. <sensor-id, 1234>, <temperature, 19.8>
stream을 데이터로 읽어오는 방법은 다양하다.
- 시간 범위로 검색: *로 저장된 id 값으로 시간 범위로 검색
- 신규 추가 데이터 수신: 실제 서버에서 로그를 읽을 때 tail-f를 사용하는 것처럼 새로 들어오는 데이터만 리스닝
- 소비자별 다른 데이터 수신(소비자 그룹): kafka처럼 소비자 개념이 존재하기 때문에 원하는 소비자만 특정 데이터를 읽게할 수 있다.
Redis 운영 모드 (Sentinel, Cluster) 비교
Redis는 단일 인스턴스(Stand Alone)만으로도 충분히 운영이 가능하지만, 물리 머신이 가진 메모리의 한계를 초과하는 데이터를 저장하고 싶거나, failover에 대한 처리를 통해 HA를 보장하려면 센티넬이나 클러스터 등의 운영 모드를 선택해서 사용해야 한다. (참고)

단일 인스턴스(Single instance)
- HA(High availibilty) 지원 안됨
센티넬(Sentinel)
- HA 지원
- master/slave replication
- sentinel process
- redis와 별도의 process
- 여러개의 독립적인 sentinel process들이 서로 협동하여 운영된다 (SPOF 아님)
- 안정적 운영을 위해서는 최소 3개 이상의 sentinel instance 필요 (fail over를 위해 과반수 이상 vote 필요)
- redis process가 실행되는 각 서버마다 각각 sentinel process를 띄워놓는 방법
- redis process가 실행되는 서버와 별개로 redis에 액세스를 하는 application server들에 sentinel process를 띄워놓는것도 가능
- 등등 다양한 구성이 가능
- 지속적으로 master/slave 가 제대로 동작을 하고있는지 모니터링
- master에 문제가 감지되면 자동으로 failover 수행
- 클라이언트는 어떻게 redis server에 연결해서 데이터를 조회하나?
- 먼저 sentinel에 연결해서 현재 master를 조회해야 한다.
클러스터(Cluster)
- HA, sharding 지원
- Sentinel과 동시에 사용하는 것이 아님! 완전히 별도의 솔루션.
- dataset을 자동으로 여러 노드들에 나눠서 저장해준다.
- Redis Cluster 기능을 지원하는 client를 써야만 데이터 액세스 시에 올바른 노드로 redirect가 가능하다.
- Cluster node들의 동작 방식
- serve clients 6379 (data port)
- cluster bus 16379 (data port + 10000)
- 자체적인 바이너리 프로토콜을 통해 node-to-node 통신을 한다.
- failure detection, configuration update, failover authorization 등을 수행
- 각 노드들은 클러스터에 속한 다른 노드들에 대한 정보를 모두 갖고있다.
- Sharding 방식
- 최대 1000개의 노드로 샤딩해서 사용. 그 이상은 추천하지 않음
- consistent hashing을 사용하지 않는대신 hashslot이라는 개념을 도입
- hashslot
- 결정방법 CRC16(key) mod 16384를
- CRC16을 이용하면 16384개의 슬롯에 균일하게 잘 분배됨
- 노드별로 자유롭게 hash slot을 할당 가능
- 예)
- Node A contains hash slots from 0 to 5500.
- Node B contains hash slots from 5501 to 11000.
- Node C contains hash slots from 11001 to 16383.
- 결정방법 CRC16(key) mod 16384를
- 운영 중단 없이 hash slots을 다른 노드로 이동시키는 것이 가능
- add/remove nodes
- 노드별 hashslot 할당량 조정
- multiple key operations 을 수행하려면 모든 키값이 같은 hashslot에 들어와야 한다.
- 이를 보장하기위해 hashtag 라는 개념 도입
- {} 안에있는 값으로만 hash 계산
- {foo}_my_key
- {foo}_your_key
- 이를 보장하기위해 hashtag 라는 개념 도입
- Replication & failover
- failover를 위해 클러스터의 각 노드를 N대로 구성가능
- master(1대) / slave(N-1대)
- async replication (master → slave replication 과정에서 ack을 받지 않음)
- 데이터 손실 가능성 존재
- master가 client요청을 받아서 ack을 완료한 후, 해당 요청에 대한 replication이 slave로 전파되기 전에 master가 죽는 경우 존재
- 클라이언트는 클러스터에 어떻게 연결해서 데이터를 조회하나?
- redis client는 클러스터 내의 어떤 노드에 쿼리를 날려도 된다(슬레이브에도 가능).
- ex) GET my_key
- 쿼리를 받은 노드가 해당 쿼리를 분석
- 해당 키를 자기 자신이 갖고있다면 바로 찾아서 값을 리턴
- 그렇지 않은경우 해당 키를 저장하고 있는 노드의 정보를 리턴 (클라이언트는 이 정보를 토대로 쿼리를 다시 보내야함)
- ex) MOVED 3999 127.0.0.1:6381
- redis client는 클러스터 내의 어떤 노드에 쿼리를 날려도 된다(슬레이브에도 가능).
Redis 운영시 주의해야 할 점 (redis.conf 권장설정)
1. 사용하면 안되는 O(n) 커맨드
Redis는 Single Thread로 동작한다. 그래서 한 사용자 오래걸리는 커맨드를 실행하면 나머지 요청은 수행할 수 없고 대기하게 되어 장애가 빈번하게 발생한다. 참고로 단순한 get/set의 경우, 초당 10만 TPS 이상이 가능하다. (CPU 속도 영향받음) 그런데 만약 하나의 명령어가 1초가 걸리는 작업을 해버리면 9만 9999개의 명령어는 1초동안 대기하게 되는데 모두 timout이 발생하면서 서비스가 터진다. (보통 timeout = 200~300ms)
keys (x) → scan (o)
모든 키를 보여주는 커맨드인데 데이터가 많을수록 조회가 매우 오래 걸린다. 이 커맨드는 재귀적으로 key를 호출할 수 있는 scan으로 대체하여 사용하는 게 좋다.
키 나누기
Hash나 Sorted Set 자료구조는 내부에 여러 아이템을 저장할 수 있는데 내부 아이템이 많아질수록 성능이 저하된다. 그래서 적절하게 최대 100만개 정도만 저장해주는 게 좋다.
delete (x) → unlink (o)
키에 많은 데이터가 들어있을 때 delete로 지우면 그 키를 지우는 동안 아무런 동작을 할 수 없다. unlink를 사용하면 백그라운드로 키를 지울 수 있기 때문에 이를 사용하는 게 좋다.
이 외에도 Get All Collections와 같은 O(n) 명령어들도 최대한 사용하면 안된다. FLUSHALL, FLUSHDB도 마찬가지인데 이 명령어들은 모든 데이터를 삭제하는 거라 꼭 필요한 경우에는 어쩔 수 없이 사용해야 한다.
2. 자동으로 데이터 비우기
MAXMEMORY-POLICY = ALLKEYS-LRU or ALLKEYS-LFU
Redis를 캐시로 사용할 때는 Key에 대한 Expire Time 설정하는 것이 권장된다. 아무래도 인메모리 DB 크기는 한정되어 있기 때문에 이 값을 설정하지 않는다면 금방 MAXMEMORY가 가득차게 되기 때문이다. Redis는 데이터가 가득찼을 때 MAXMEMORY-POLICY 정책에 의해 데이터가 삭제된다.
- noeviction(default): 메모리가 가득차면 더 이상 Redis에 새로운 키를 저장하지 않는다. 즉 메모리가 가득차면 새로운 데이터 입력이 불가능하기 때문에 장애가 발생할 수 있다.
- volatile: 가장 최근에 사용하지 않았던 키부터 삭제하는 정책. expire 설정에 있는 키값만 삭제한다. 만약 메모리에 expire 설정이 없는 키들만 남아있다면 이 설정에서 위와 똑같은 장애가 발생할 수 있다.
- allkeys(권장): allkeys-lru는 모든 키에 대해 LRU방식으로 데이터를 삭제한다. allkeys-lfu는 사용 빈도수가 가장 적은 데이터부터 삭제해준다. 이 설정은 적어도 데이터가 MAXMEMORY로 인해 장애가 발생할 가능성은 없다.
3. TTL 값은 능동적으로 설정
대규모 트래픽 환경에서 TTL값을 너무 작게 설정할 경우 Cache Stampede 현상이 발생할 수 있다. Look-Aside 패턴에서는 Redis에 데이터가 없다는 응답을 받은 서버가 직접 DB에서 읽은 뒤 다시 Redis에 저장하는 과정을 거친다. 그런데 키가 만료되는 순간 많은 서버에서 이 키를 같이 보고 있었다면 모든 앱 서버들이 DB에서 같은 데이터를 찾게되는 Duplicate Read가 발생한다. 또 읽어온 값을 Redis에 각각 저장하는 Duplicate Write도 발생한다. 이러한 경우에 상황에 맞춰 TTL 값을 능동적으로 설정해주는 게 좋다.
4. Memory 관리
아무래도 Redis는 메모리를 사용하는 저장소이기 때문에 메모리 관리가 매우 중요하다. 모니터링할 때도 유의해야 할 점이 있다. 모니터링할 때 used_memory가 아닌 used_memory_rss 값을 보는 것이 더 중요하다.
- used_memory: 논리적으로 Redis가 사용하는 메모리
- used_memory_rss: OS가 실제로 Redis에 할당하기 위해 사용한 물리적 메모리 양
실제 저장된 데이터는 적은데 rss 값이 큰 경우는 fragmentation이 크다고 말한다. 주로 삭제된 키가 많을 때 이 fragmentation이 증가한다. 특정 시점에 피크를 찍고 다시 삭제되는 경우 혹은 TTL로 인한 eviction이 많이 발생하는 경우에 주로 발생한다. 이때 activedefrag 기능을 잠시 켜두면 도움이 된다. 공식문서에서도 이 기능을 fragmentation이 발생했을 때 켜두는 것을 권장하고 있다.
- CONFIG SET activedefrag yes
redis.conf 설정 정리 메모
특정 O(n) command disable
무조건 keys는 disable해야 한다. aws의 ElasticCache는 이미 하고 있다. 보통 전체 장애의 90% 이상이 KEYS와 SAVE 설정을 사용해서 발생한다.
MAXMEMORY-POLICY = ALLKEYS-LRU or ALLKEYS-LFU
Redis는 데이터가 가득찼을 때 데이터를 삭제해준다. 이 설정은 적어도 데이터가 MAXMEMORY로 인해 장애가 발생할 가능성은 없다.
- LRU 방식은 가장 오래된 데이터부터 삭제해준다.
- LFU는 빈도 수가 가장 적은 데이터부터 삭제해준다.
Maxclient 설정 50000
Maxclient 만큼만 네트워크 접속이 가능하기 때문에 값을 많이 높이는 게 좋다. 체크를 위해서 Redis에 접속하고 싶은데 Maxclient로 인해 접속하지 못하는 경우가 많다.
RDB/AOF 설정 off
Redis Persistence(영속성) 옵션에 들어가는 RDB/AOF 설정은 무조건 끄는 게 성능상 유리하고 안정성도 더 높다.

참고
https://aws.amazon.com/ko/elasticache/redis-vs-memcached/
https://redis.io/docs/manual/data-types/
https://www.letmecompile.com/redis-cluster-sentinel-overview/
'Dot Database > Redis' 카테고리의 다른 글
| 싱글 쓰레드인 Redis가 빠른 이유: In-Memory, I/O Multiplexing (0) | 2023.01.24 |
|---|---|
| [DB] 데이터 분산 처리 방법에 대해 알아보자 (Sharding, Consistent Hashing, Redis Cluster 모드) (0) | 2022.04.27 |
| [Spring/ Redis] Spring으로 ElasticCache for Redis 사용해보기 (0) | 2022.04.20 |
| [Database] Redis 고가용성을 위한 Sentinel 모드 직접 다뤄보기 (0) | 2022.04.18 |
| [Database] Redis 간단한 사용 방법 (Stand Alone, Replication 기능) (0) | 2022.04.18 |



