
Redis 운영모드
이전 포스팅에서 Standalone 모드와 Sentinel 모드에 대해 알아봤다. Redis는 단일 인스턴스(Stand Alone)만으로도 충분히 운영이 가능하지만, 복제나 자동 failover에 대한 처리를 통해 HA를 보장하려면 Sentinel 모드를 사용하는 것이 좋다는 것을 직접 실습해보며 확인했었다.
그런데 만약 Redis를 Persistent한 저장소를 사용한다고 하면 어떻게 할까? 일반적으로 메모리는 디스크보다 속도가 빠르지만 용량이 작다는 한계를 지니고 있다. 이러한 특징을 가진 메모리에 무작정 데이터를 적재하게 된다면 물리 머신이 가진 한계를 뛰어넘지 못하고 성능에 부정적인 영향을 가하게 된다. 이러한 문제를 극복하고 효율적으로 데이터를 저장 및 관리 하고싶다면 데이터 분산 처리 기능이 있는 Cluster 모드를 사용하는 것이 좋다.

Cluster 모드는 Sentinel 모드와 마찬가지로 일부 노드가 종료되어도 계속 사용 가능한 고가용성(HA)의 특징을 가지면서 데이터셋을 여러 노드에 자동으로 분산하는 확장성 및 고성능의 특징이 있다.
Cluster 모드를 알기 위해서는 먼저 데이터 분산 방법에 대해서 이해해야 한다. 예를들어, 복제와 샤딩의 차이란 무엇일까?
- 복제(Replication)는 데이터를 똑같이 다른 노드에 복사하는 것이라면 샤딩(Sharding)은 데이터를 분산하여 저장하는 기법이다.
- 즉, 같은 메모리 크기가 주어진다면 복제에 비해 더 많은 데이터를 나눠서 저장할 수 있다.
- 이 둘은 배척되는 개념이 아니다. 신뢰성있는 대용량 데이터를 처리하기 위해서 복제와 샤딩은 같이 사용되는 경우가 많다.
데이터 분산 방법
데이터 분산 방법은 데이터 특성(Cache 아니면 Persistent한 저장소)에 따라서 선택할 수 있는 방법이 달라진다.
- Cache 일때는 큰 문제가 없다. (절대는 아님)
- Persistent한 데이터 저장소로써 사용할 때 핼게이트가 열릴 수 있다.
- Application 레벨에서 나눌 것이냐 아니면 Redis Cluster 모드를 사용할 것이냐로 선택할 수 있다.
1. Shardig
샤딩(Sharding)은 DB 분산 저장 기법 중 하나로 '조각내다'라는 뜻을 가지고 있다. 이는 하나의 거대한 데이터베이스나 네트워크 시스템을 여러 개의 작은 조각으로 나누어 분산 저장하여 관리하는 것을 말한다. 이는 상황마다 사용하는 전략이 달라진다.
1-1) Range
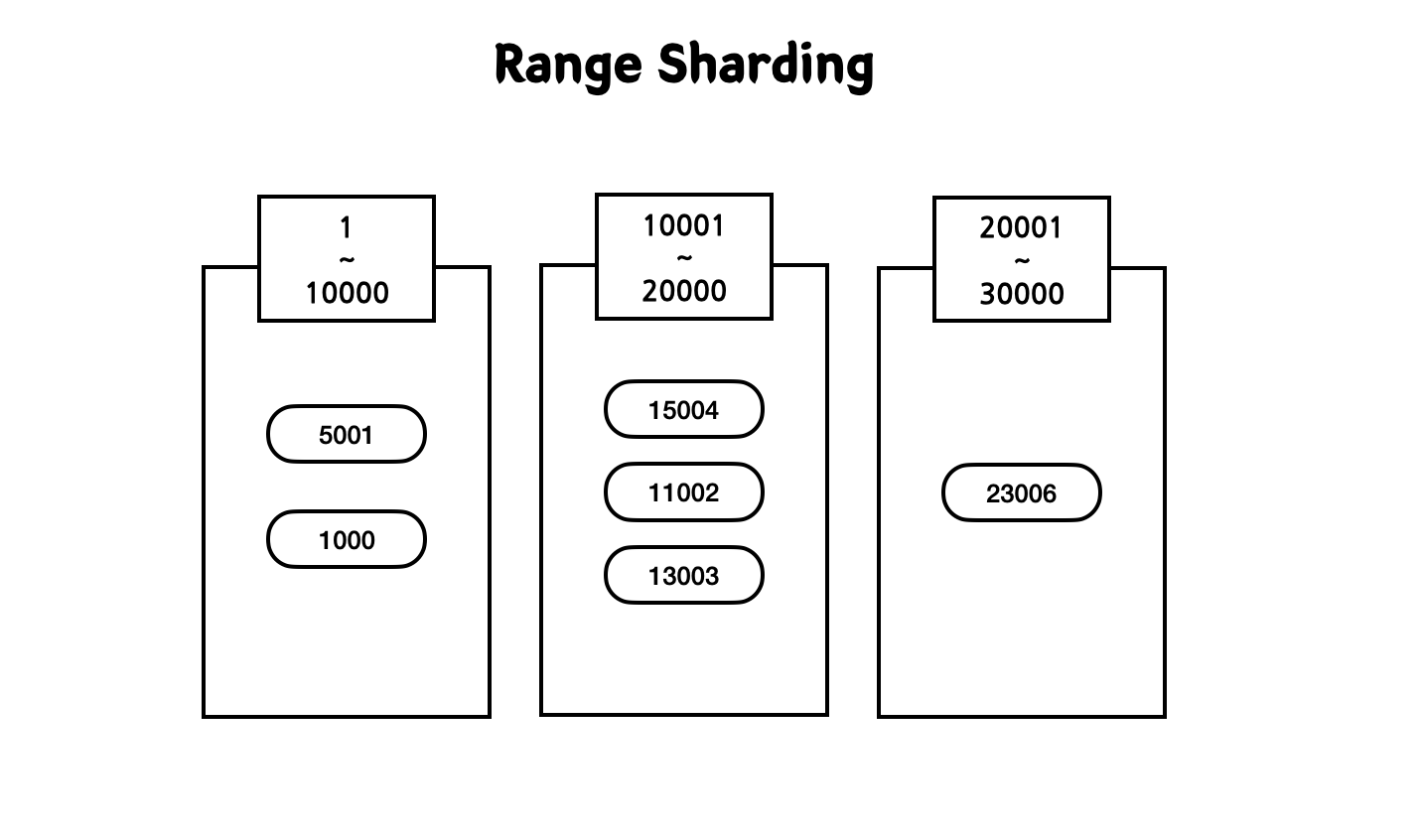
Range Sharding은 제일 쉬운 방식으로 PK 범위를 기준으로 DB를 특정하여 데이터를 분산한다.
- 특정 Range를 정의하고 해당 Range에 속하면 데이터를 저장한다.
- 데이터를 골고루 분배되지 못하는 상황이 발생할 수 있다. 그러면 특정 서버에 부하가 발생하거나 비어버리게 되는 불균형이 생기게 된다.
이 전략은 Range를 정의하고 해당 Range에 속하면 데이터를 저장한다. 그런데 이렇게 데이터를 나누면 특정 Range 서버에만 부하가 몰릴 가능성이 높다. 예로, 이벤트 때문에 가입한 유저가 한 곳을 차지하게 될 경우가 그렇다. 다음 그림에서 10001~20000 서버에만 유독 회원 데이터가 몰려있다. 이는 이벤트에 엄청 가입한 유저 데이터이다.
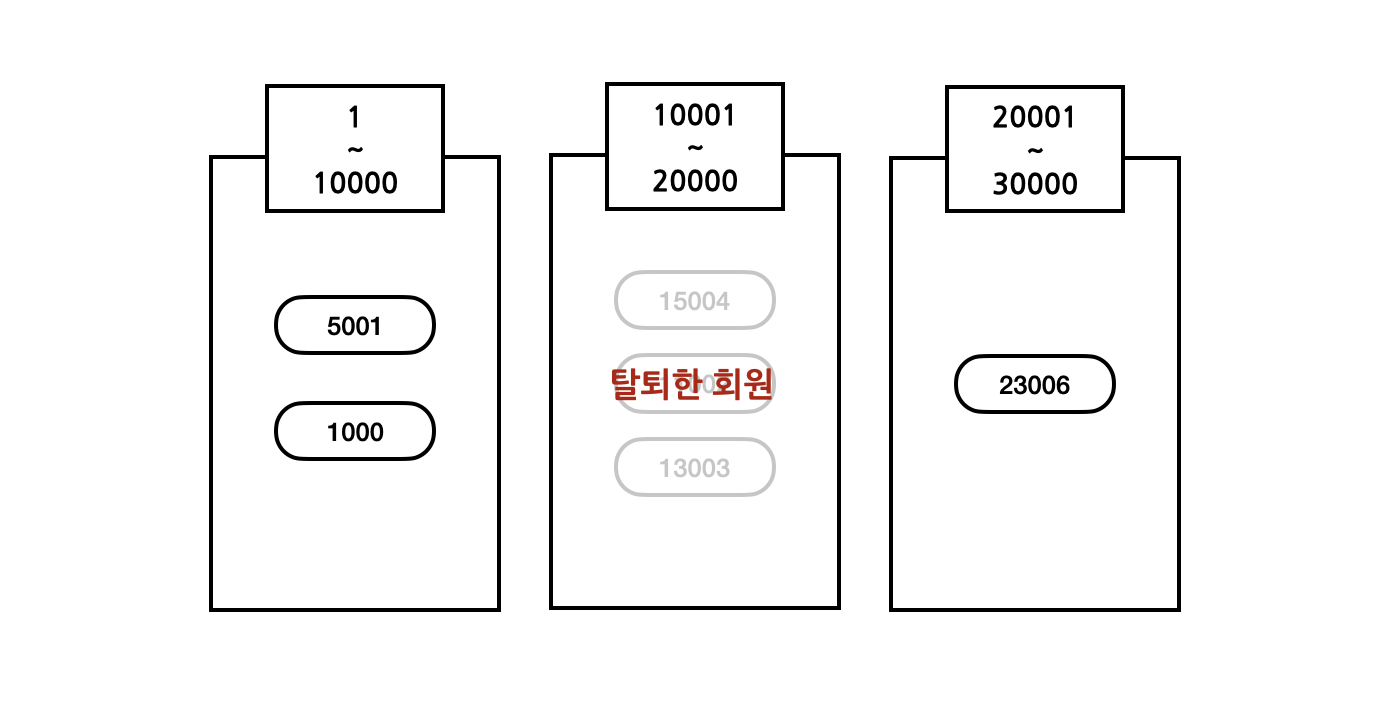
이들은 이벤트를 위해 잠시 가입했기 때문에 다음주에 대부분의 회원이 다 나가버리는 상황이 발생해버렸다.
- 그러면 해당 서버는 계속 놀게 되어서 서버 사용량이 극심하게 차이가 나는 문제가 발생하게 된다.
- 데이터가 많은 다른 서버에서 해당 서버로 데이터를 옮길 수도 없다. Range를 기준으로 데이터를 나눴기 때문에 다른 데이터가 해당 서버로 이동할 수도 없다.
1-2) Modular
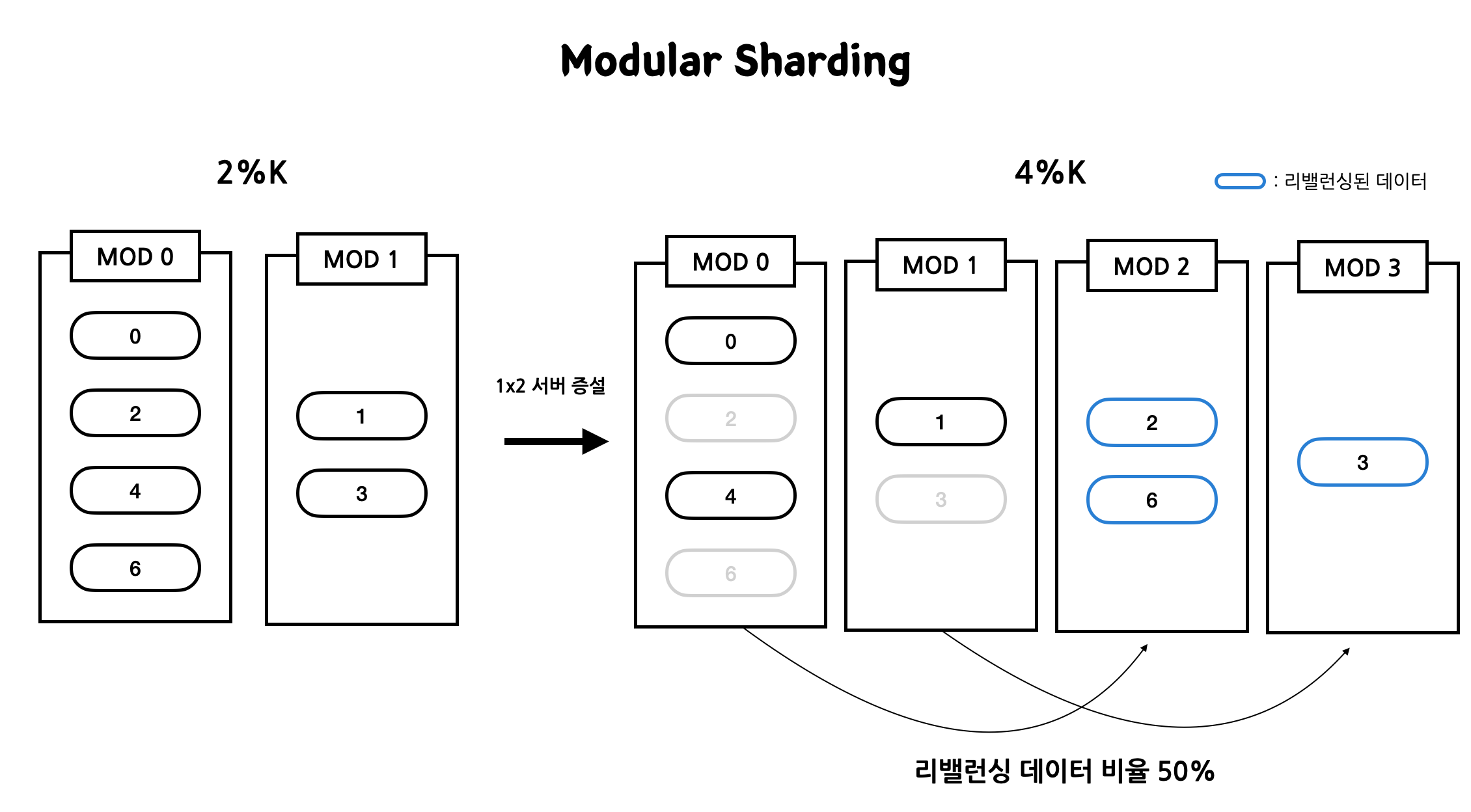
Modular Sharding은 PK를 모듈러 연산한 결과로 데이터를 분산한다. N%K로 서버의 데이터를 결정한다.
- Range보다는 데이터를 균등하게 분배한다.
- 그러나 서버 수의 증감에 따라 rebalancing할 데이터가 많아진다. 위에서 Consistent Hashing을 적용하지 않아서 데이터 쏠림 현상이 있는 경우 Modular Sharding 방식이 서버를 1대씩 추가할 때 데이터 리밸런싱이 얼마나 심한지 알아봤다.
해당 전략을 사용할 때 리밸런싱의 횟수를 줄이기 위해 2의 배수만큼 서버를 증설해줘야 한다. 다음 그림을 보면 서버 2대로 늘리면 리밸런싱 되는 비율이 50%로 1대를 늘리는 경우에 비교해 봤을 때 확연히 줄어드는 것을 확인할 수 있다.
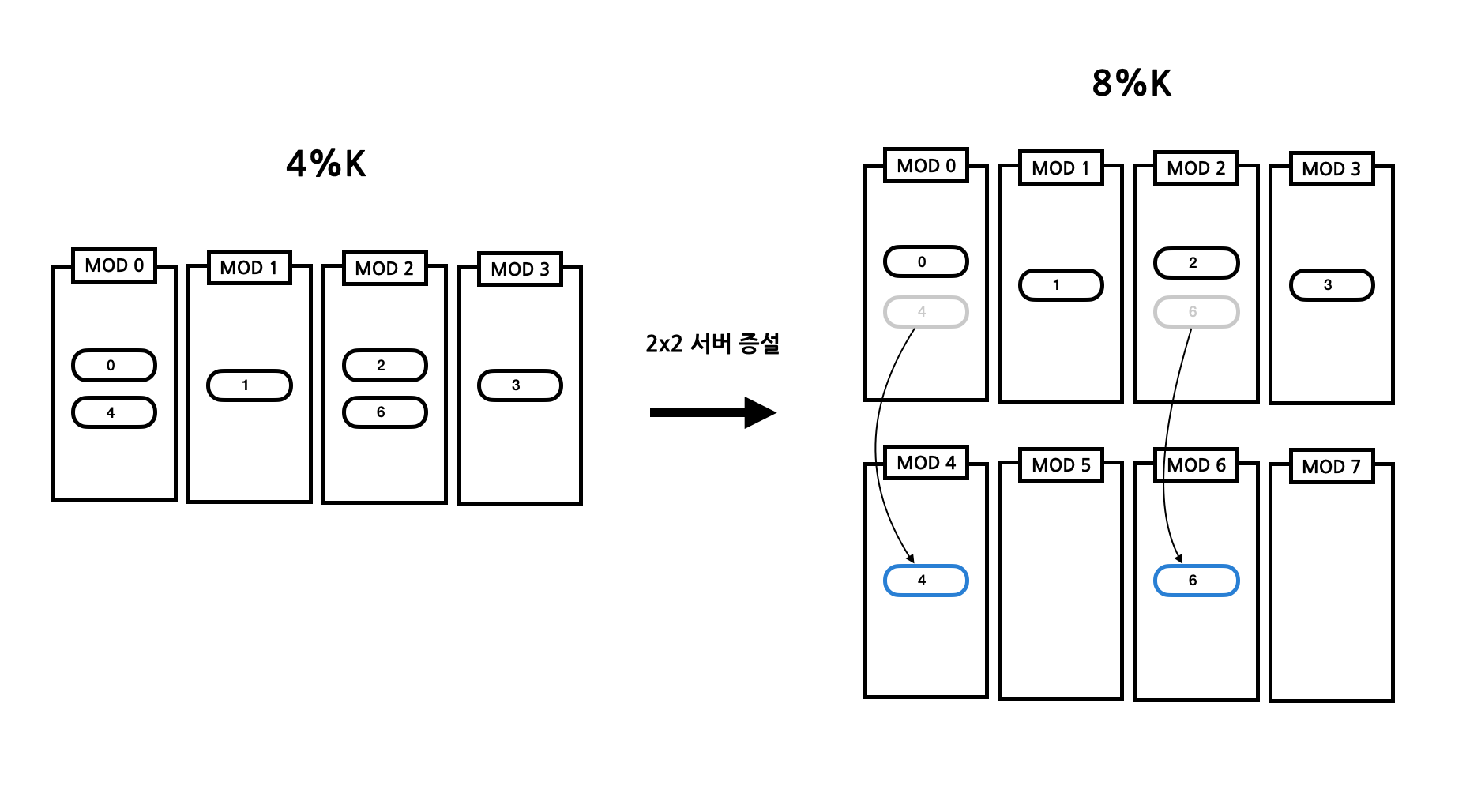
한 번 더 증설을 해보자. 4대를 늘려서 8대가 된다해도 데이터 리밸런싱 비율이 높지 않은 것은 마찬가지이다. 자세히 보면 규칙을 발견할 수 있는데 이는 모듈러의 특성을 이용해서 그렇다.
- 2대를 늘릴 때 MOD 0, MOD 1에 있던 데이터는 각 MOD 2, MOD 3 서버로 이동했다.
- 4대를 늘릴 때도 마찬가지이다. (MOD 0 → MOD 4), (MOD 1 → MOD 5), (MOD 2 → MOD 6), (MOD 3 → MOD 7)로 이동한다.
이와 같이 Modular Sharding도 데이터 리밸런싱에 대한 단점을 극복할 수 있다. 하지만 이에도 문제점이 있는데 서버 증설의 갯수가 너무 빠르게 증가한다는 것이다. 그래서 여러 전략을 알맞게 섞어서 사용해줘야 한다.
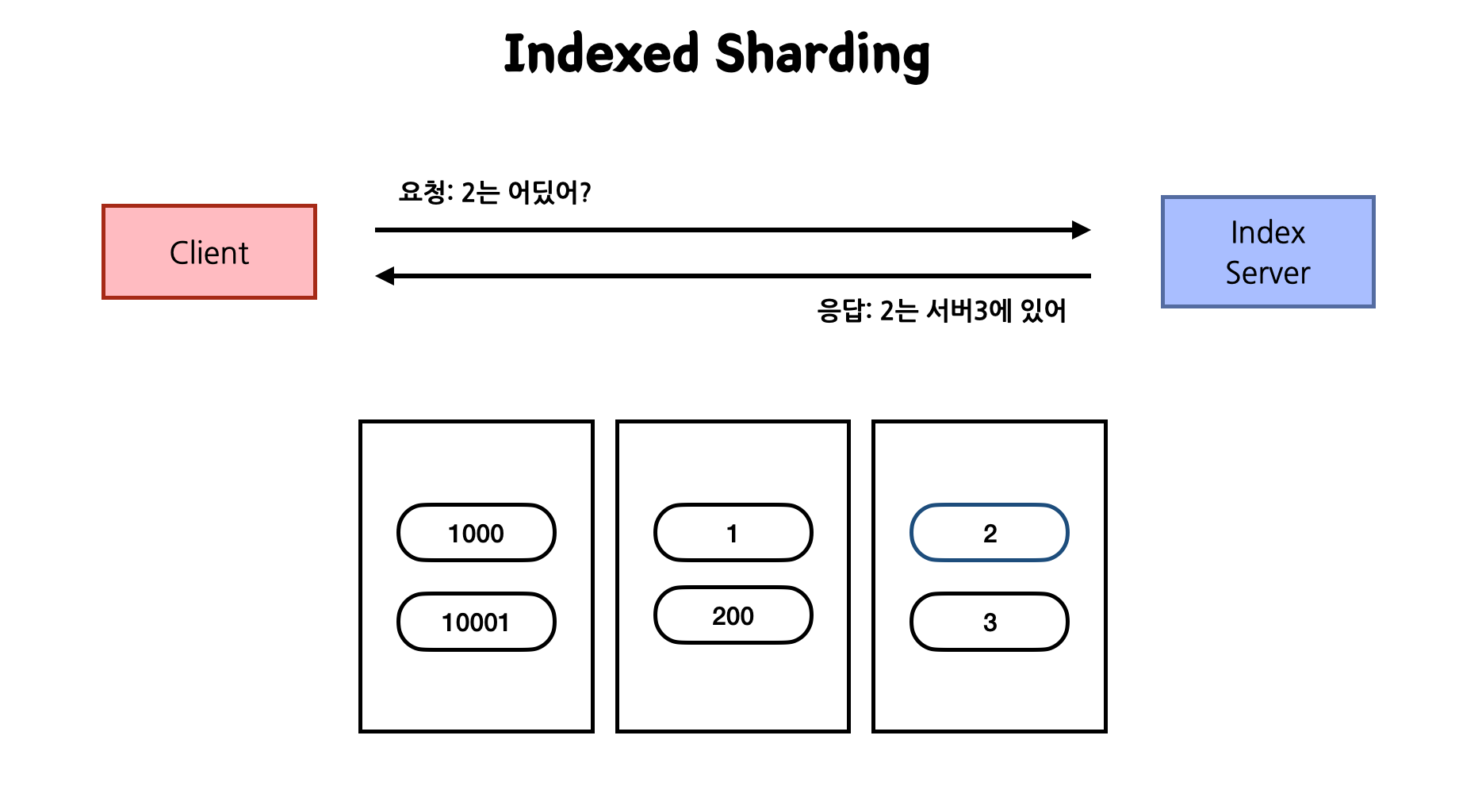
1-3) Indexed
특정 Key가 어디로 이동해야 하는지 알려주는 인덱스 서버를 따로 두고 데이터를 분산한다. 이 방식을 사용하면 이전 Range Sharding에서 나왔던 단점을 커버할 수 있다. 데이터가 없어서 노는 서버에 더 많이 넣어주고 데이터가 많은 서버에는 적게 넣어 조절할 수 있다.
- 해당 Key가 어디에 저장되어야 할지 관리 서버가 따로 존재한다.
- Index 관리 서버에 의존적이기 때문에 장애 포인트가 늘어난다.
2. Hash Slot: Redis Cluster 모드로 데이터 분산 저장하기
Redis Cluster 모드로 데이터를 분산 저장하여 운영할 수 있다. 해당 모드에서는 Consitent Hashing 동작 방식과 유사한 Hash된 값이 자기 Slot이 속한 Redis Cluster 서버로 이동하는 분산 키 알고리즘을 사용한다. crc16으로 한 값을 모듈러 16384의 값을 구해서 해당 값에 속한 서버로 이동하게 된다. 이는 서버가 아무리 늘어나도 16384대를 넘어갈 수 없다는 뜻이기도 하다.
- Hash 기반으로 Slot 16384로 구분
- Hash 알고리즘은 CRC16을 사용
- Slot = crc16(key) % 16384 (서버 최대 개수: 16384)
- Key가 Key{hashKey} 패턴이면 실제 crc16에 hashKey가 사용된다.
- 특정 Redis 서버는 slot range를 가지고 있고, 데이터 migration은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다. (migrateCommand 이용)
동작 방식
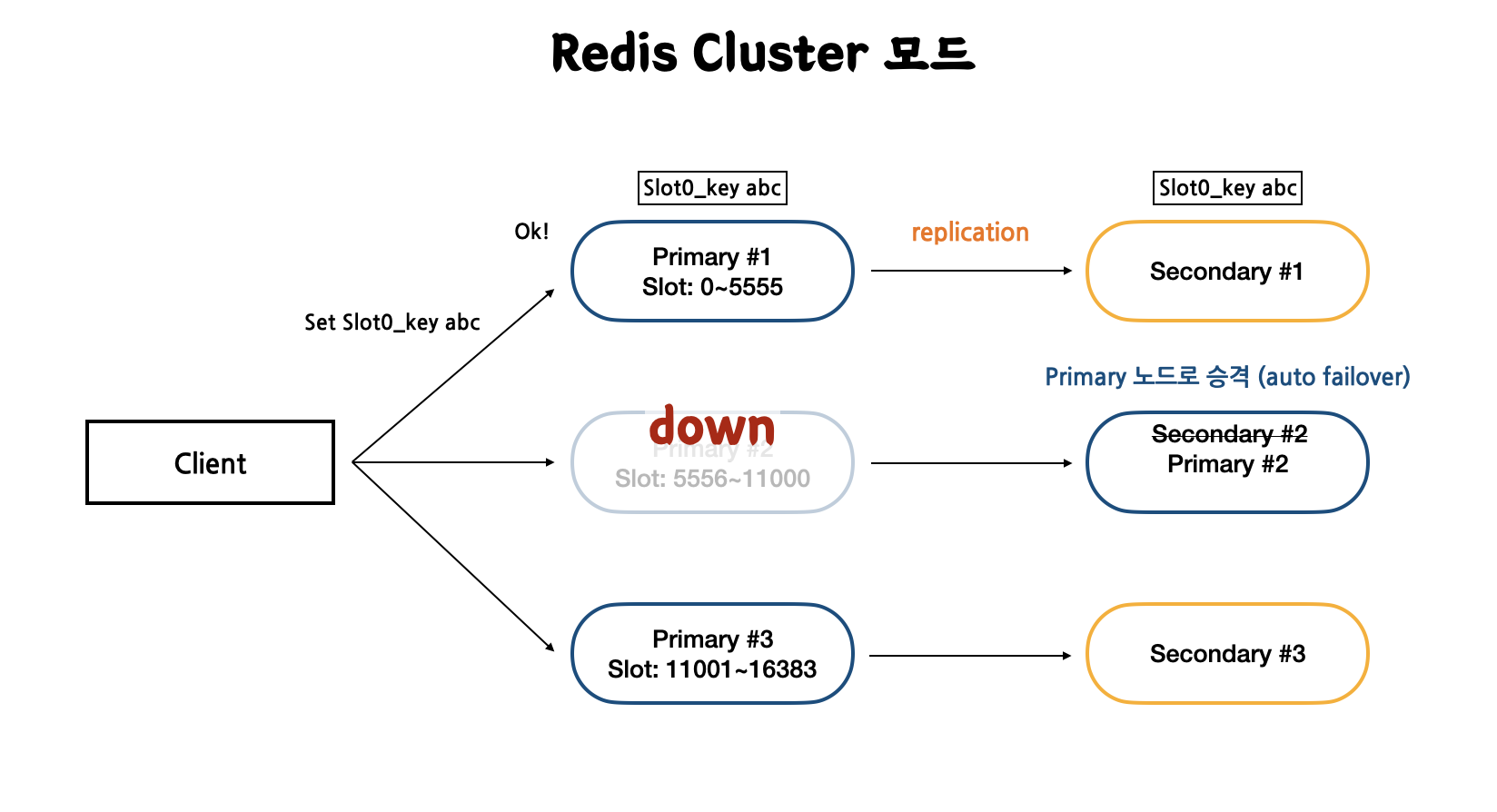
Redis Cluster는 primary 노드와 secondary 노드 세트로 이루어져 있다. primary 노드마다 slot range가 할당되어 쓰기 작업으로 들어오는 데이터의 Slot이 자신의 range에 속하면 저장하는 방식이다.
Cluster 모드의 HA는 replication과 auto failover 기능으로 기존 Redis와 같다. primary에 쓰기 작업이 들어오면 secondary에도 그 값이 복사되어 저장된다. 그리고 만약 장애로 primary 노드가 죽으면 secondary 노드가 마스터로 선출된다.
- Slot0인 key를 지닌 값을 Primary #1에 저장하면 replication 기능으로 인해 자동으로 Secondary #1에도 저장된다.
- Primary #2 장애가 발생하게 되면 auto failover 기능으로 인해 Secondary #2가 Primary #2로 선출되어 Client에게는 지속적으로 정상 서비스를 제공한다.
Cluster 모드는 라이브러리에 의존적이다
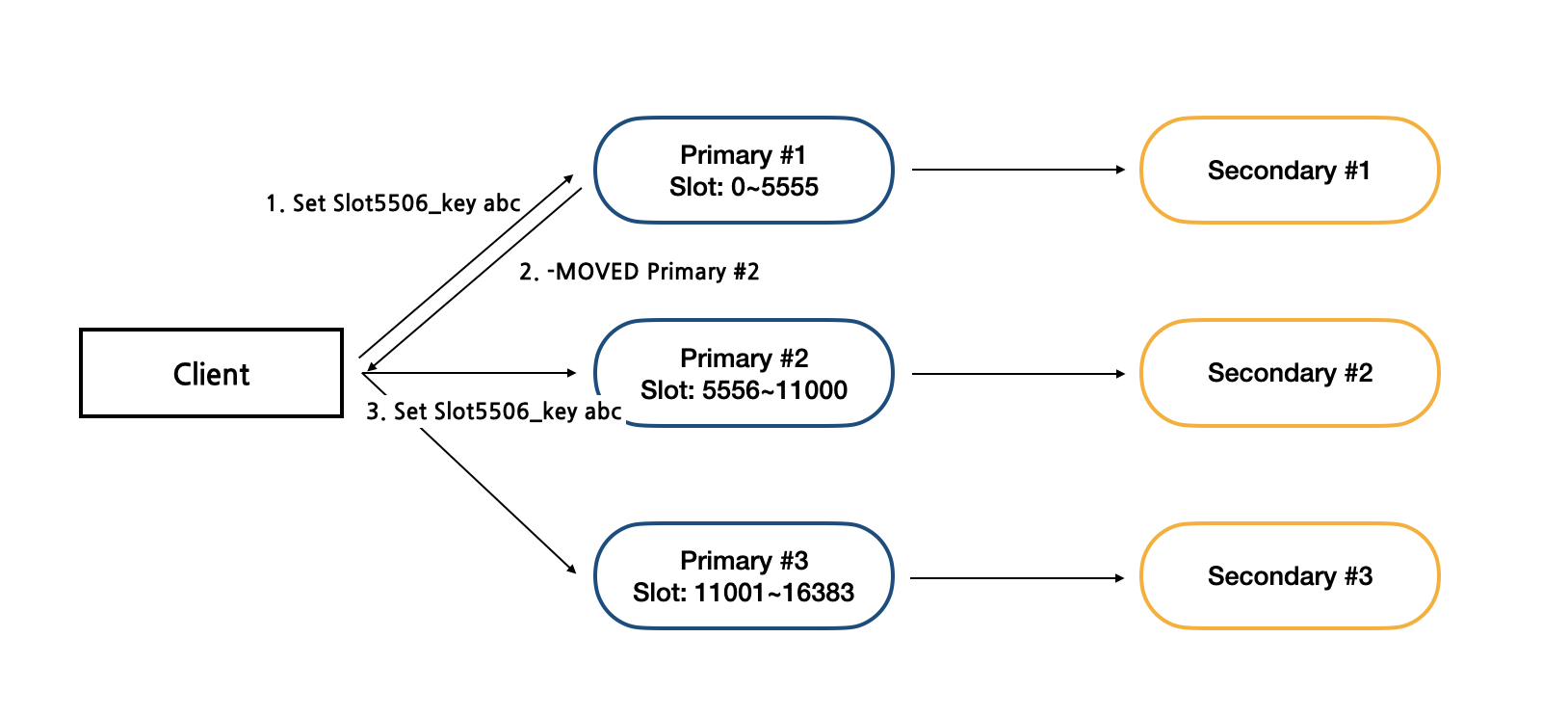
만약 클라이언트가 보낸 slot이 일치하지 않는다면 서버는 이를 다시 클라이언트에게 몇 번 노드로 전송해야 하는지 알려주면서 돌려준다. 그리고 클라이언트는 이를 다시 해당 노드로 전송해야 한다. 즉, 라이브러리가 없으면 한 번에 저장이 안되는 것이다. 대부분 라이브러리가 들어가있지만 만약 직접 커스텀하여 구현한다면 이 라이브러리 처리를 안해주면 Redis Cluster 모드를 사용할 수 없다.
- 클라이언트는 Slot5506인 key를 가진 데이터를 Primary #1 노드에 쓰기 요청을 한다.
- 해당 노드는 자신의 범위에 해당하지 않아 이 범위에 해당하는 Primary #2 노드로 전송하라고 메세지를 보낸다.
- 클라이언트는 다시 Slot5506인 key를 가진 데이터를 Primary #3 노드에 쓰기 요청을 한다.
장점
- 자체적인 Primary, Secondary Failover: Sentinel처럼 다른 health check가 필요없다. cluster내에서 health check를 해주고 죽으면 자동으로 secondary를 primary로 승격시켜준다.
- Slot 단위의 데이터 관리: slot 단위로 데이터를 관리하기 때문에 a 키는 어디에 전송, b 키는 어디에 전송 일목요연하게 전송할 수 있다.
단점
- 다른 운영 모드에 비해 Slot 관리와 같은 기능 때문에 메모리 사용량이 더 많다.
- Migration 자체는 관리자가 시점을 결정해야 한다.
- Library 구현이 필요하다. 많이 쓰는 언어는 다 구현해주는데 그렇지 않은 것은 직접 구현해야 함.
- redis-cli cluster 모드로 접근하면 알아서 해주는 것처럼 보이지만 redis-cli에서 받은 것을 다시 원래 서버로 보내기 때문에 정상적으로 처리가 되는 것이다. 원칙적으로 redis 안에서는 안해준다.
3. Consistent Hashing
Consistent Hashing은 분산 처리 환경에서 사용하는 알고리즘이다. 이 방식을 사용하면 서버의 증감된 데이터 분량만 리밸런싱 하도록 줄일 수 있다. 이러한 비슷한 방식에서 데이터 리밸런싱을 최소화하는 알고리즘 또한 포함되어 있기에 이에 대해 더 자세히 알아보고자 한다.
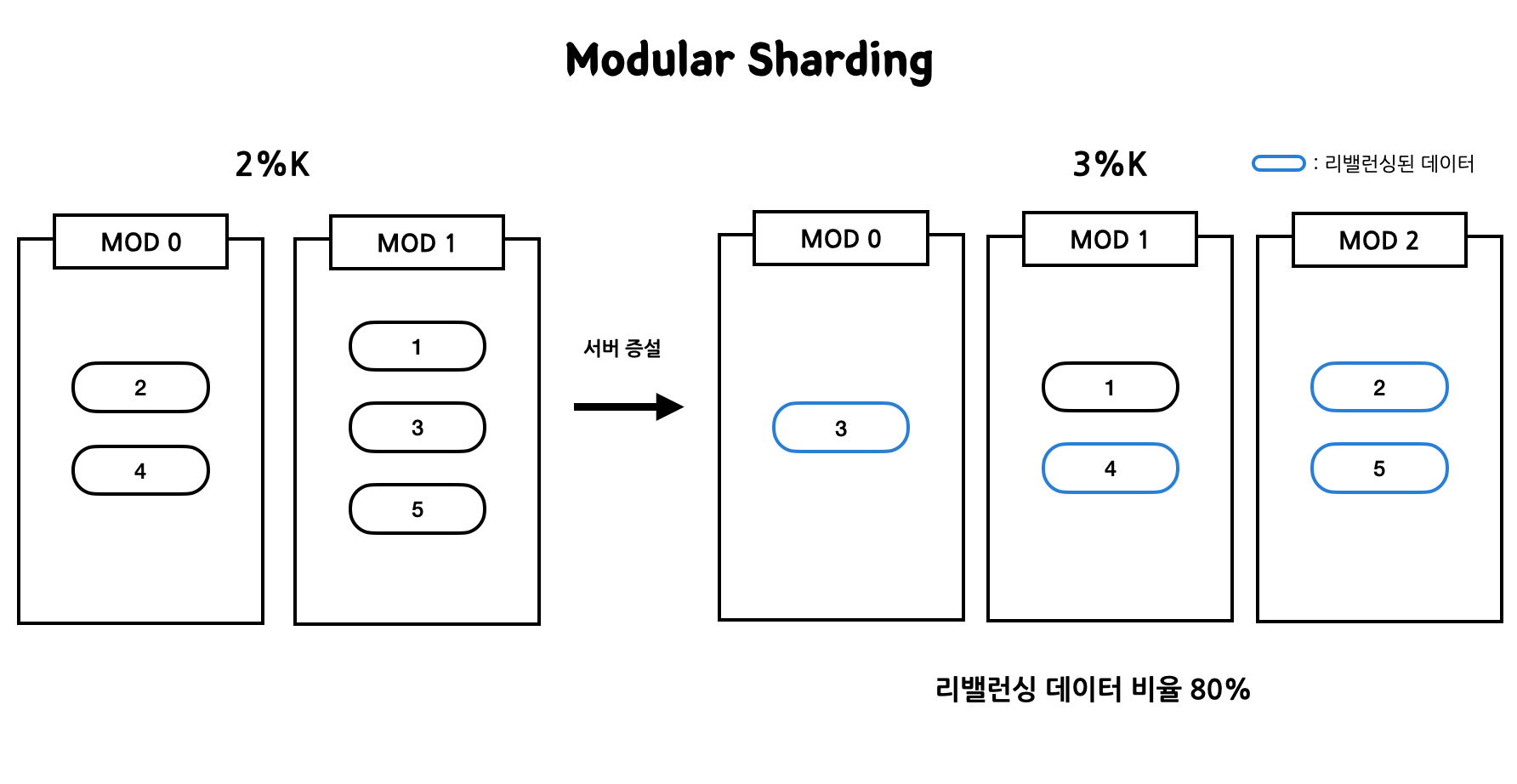
예시) Modular Sharding 데이터 리밸런싱 과정
서버 수 2대일 경우 2%k로 데이터를 분배해놓았다가 서버가 증가하면 3%k로 적재되어 있는 데이터들이 리밸런싱된다. 리밸런싱 되는 데이터 수를 보면 무려 80%나 재배치되는 것을 볼 수 있다. 여기서 만약 MOD2 서버가 죽으면 리밸런싱된 데이터가 다시 움직인다.
- 만약 장애가 발생하면 엄청나게 많은 데이터가 리밸런싱이 되어 매우 취약한 환경을 지녔다고 볼 수 있다. 서버 증감하는 경우도 마찬가지이다.
3-1) Consistent Hashing란?
Consistent Hashing을 사용하면 이러한 단점을 커버할 수 있다. 이 방식을 사용하면 서버 증감 여부에도 \(1\over n\)만 데이터가 리밸런싱된다. 데이터 분산 처리 과정은 새로운 데이터 Key가 들어오면 hash 알고리즘을 적용해서 자신의 hash 값보다 크면서 가장 가까운 hash 값을 지닌 서버로 이동하게 된다. 이는 key의 데이터가 항상 일정하면 그 hash 값 또한 항상 일정하기 때문에 나올 수 있는 방법이다.
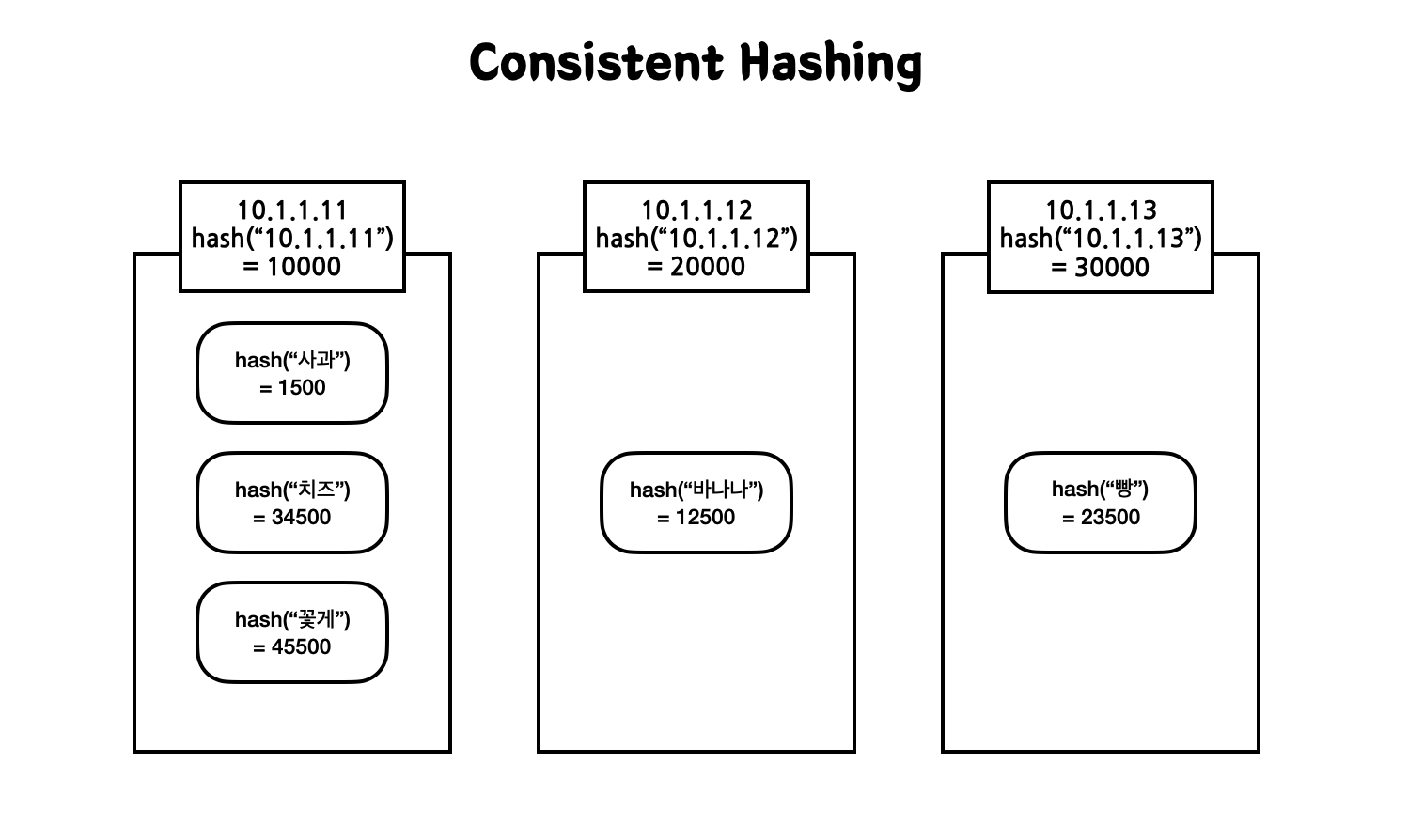
3-2) Consistent Hashing 서버 장애 발생시
여기서 만약 "20000" hash 값을 지닌 서버가 장애로 다운된다고 해도 기존 데이터는 리밸런싱이 일어나지 않는다. 장애가 발생한 서버의 데이터만 그 다음으로 큰 hash 값을 지닌 서버로 이동하게 된다.
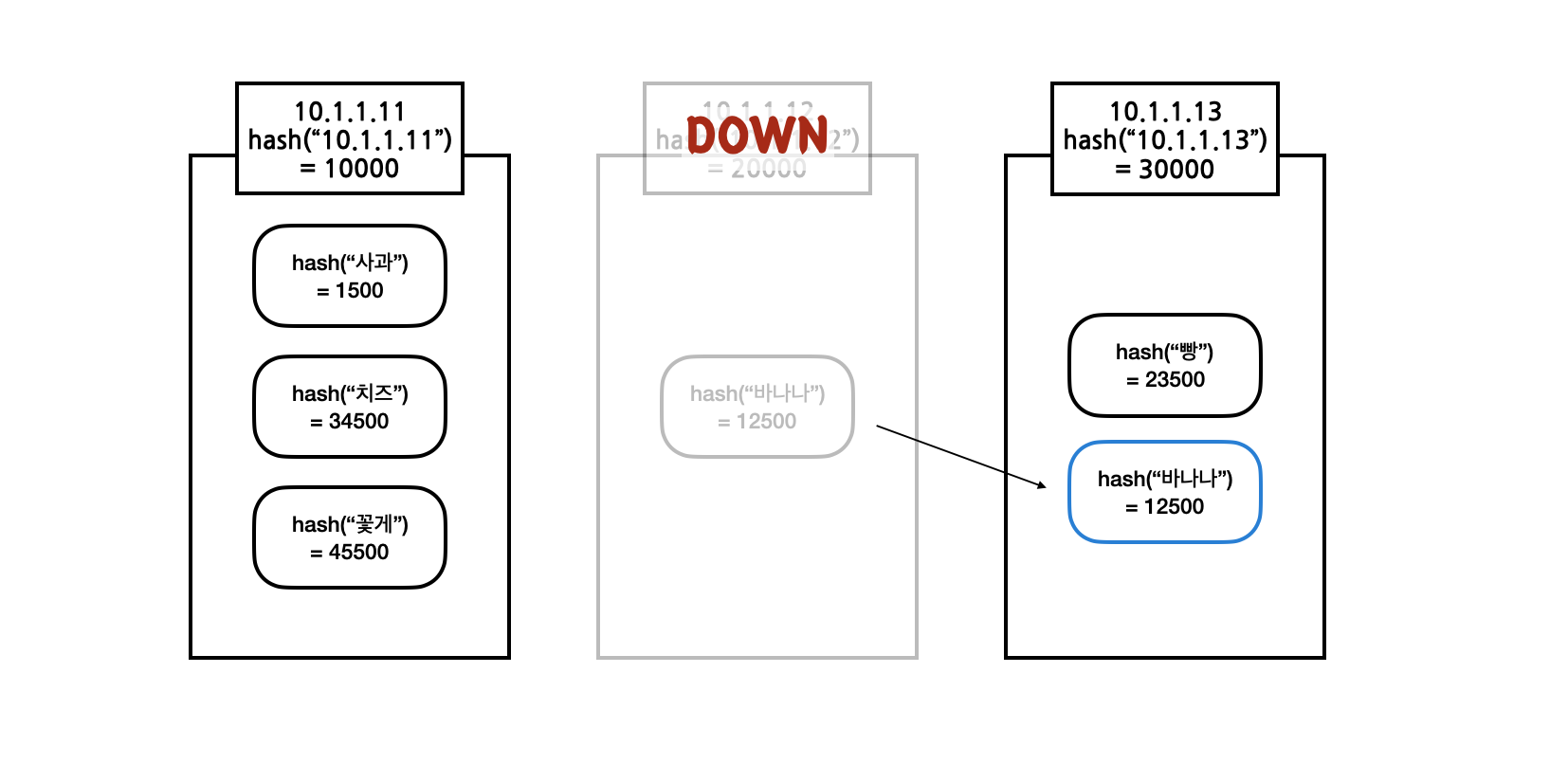
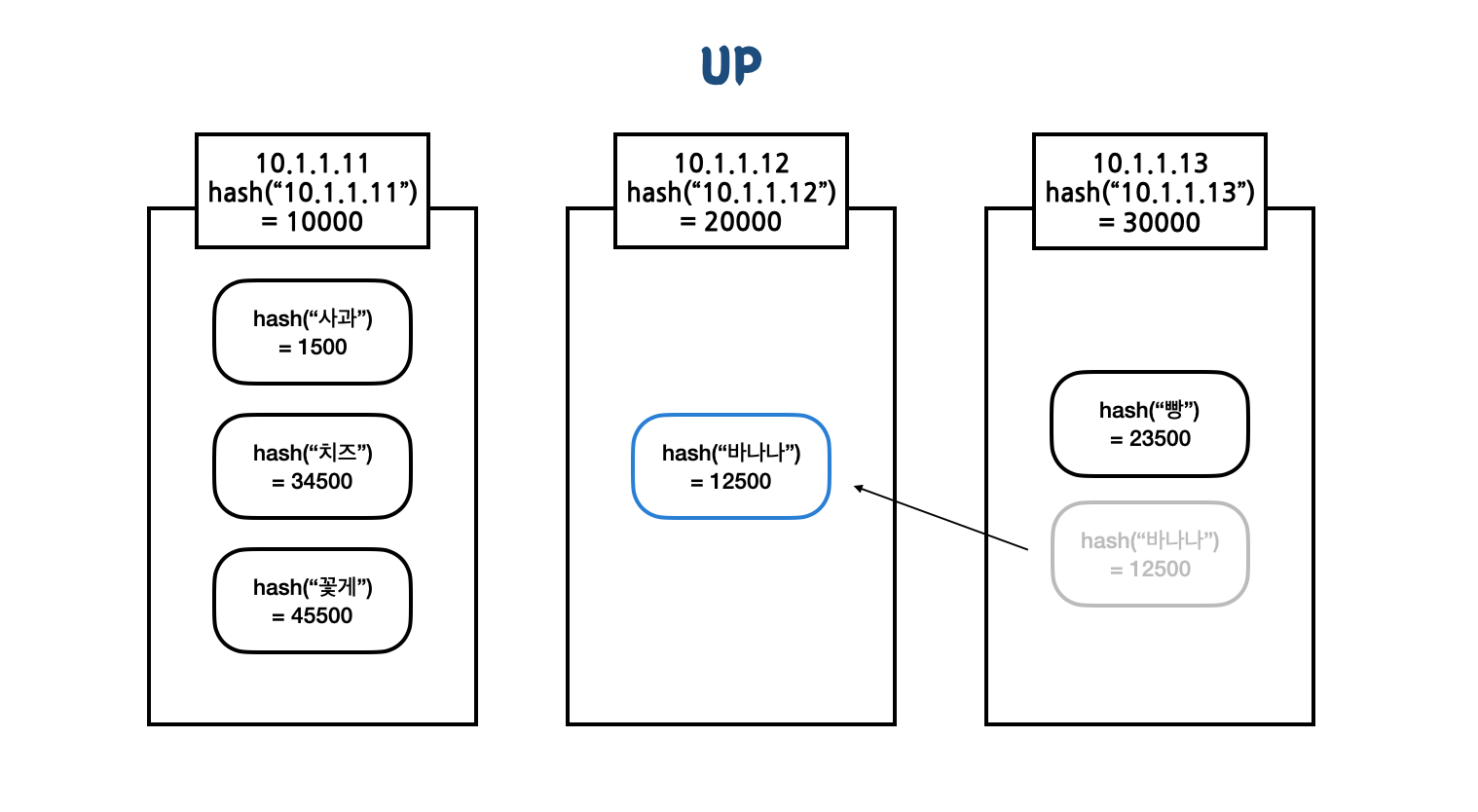
다시 "20000" 서버가 복구되면 이동했던 데이터들만 다시 제자리로 리밸런싱된다.
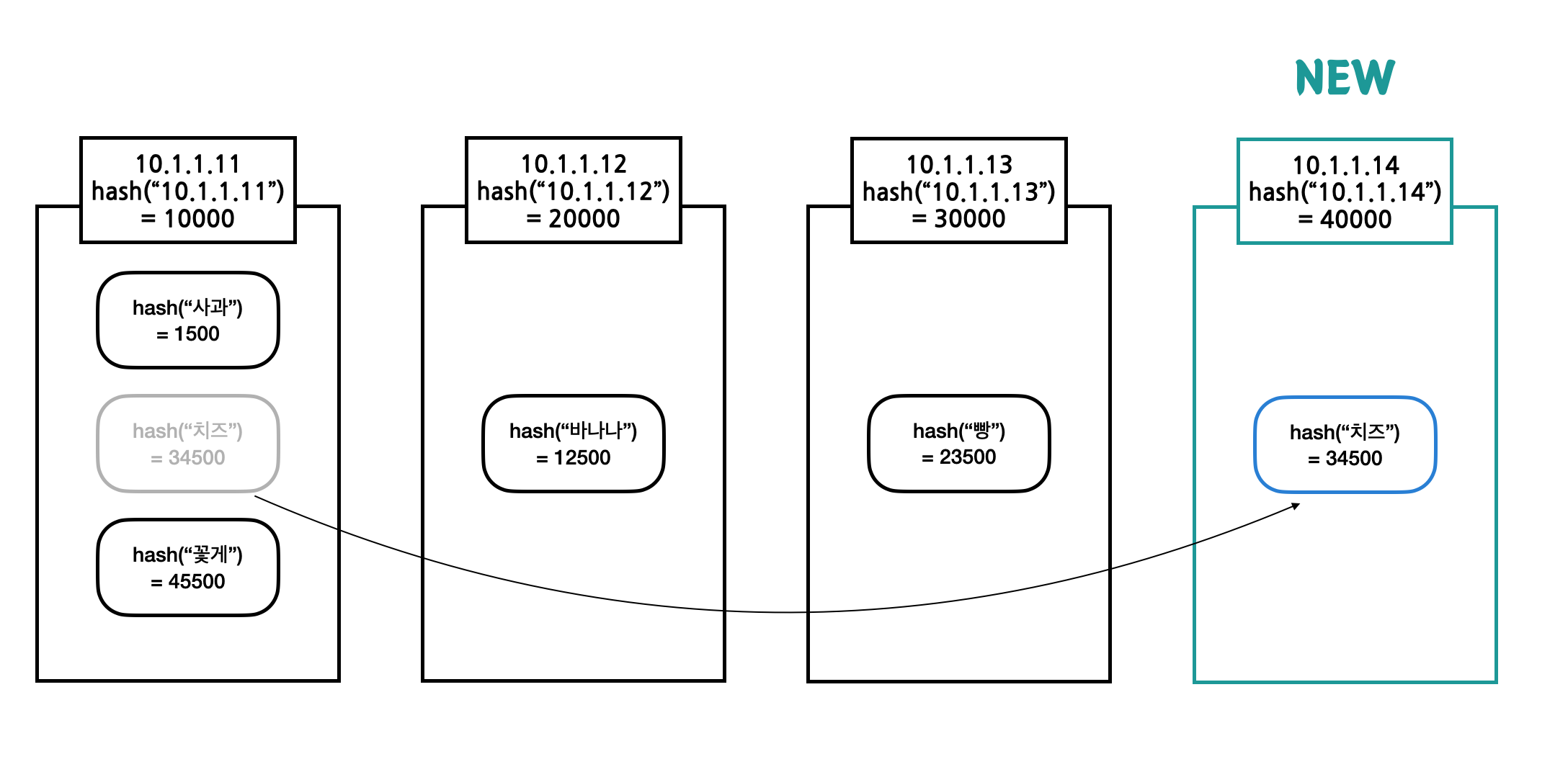
3-3) Consistent Hashing 서버 증설 \(1\over N\)
만약 데이터가 많아져 서버를 증가하게 되면 \(1\over N\) 만큼의 데이터만 리밸런싱된다. 이런식으로 서버를 배치하는 로직을 설계하면 서버 장애가 발생하거나 증설하는 경우에도 데이터가 골고루 분배되어 있기 때문에 데이터 리밸런싱은 크게 발생하지 않게 된다.
단, \(1\over N\)만 리밸런싱된다는 조건은 데이터가 N개의 저장소에 각 골고루 분포되어있다는 가정하에 이루어진다. 해시 알고리즘은 범위대로 균등한 결과를 도출해내는 함수가 아니다. 그러면 당연히 데이터가 골고루 분포되지 않는 경우가 존재하게 된다.
3-4) Hash Ring
hash 값이 한 서버에만 몰리게 되는 경우가 발생할 확률은 분명히 존재한다. 다음 Hash Ring을 보면 A, B, C의 공간이 균일하지 않다. B가 죽는다면 B의 부하는 전부 C로 넘어가게 된다. 자칫 해당 서버가 장애라도 발생하게 된다면 Consistent hashing이 갖는 최대 장점은 사라지게 된다.

3-5) VNodes
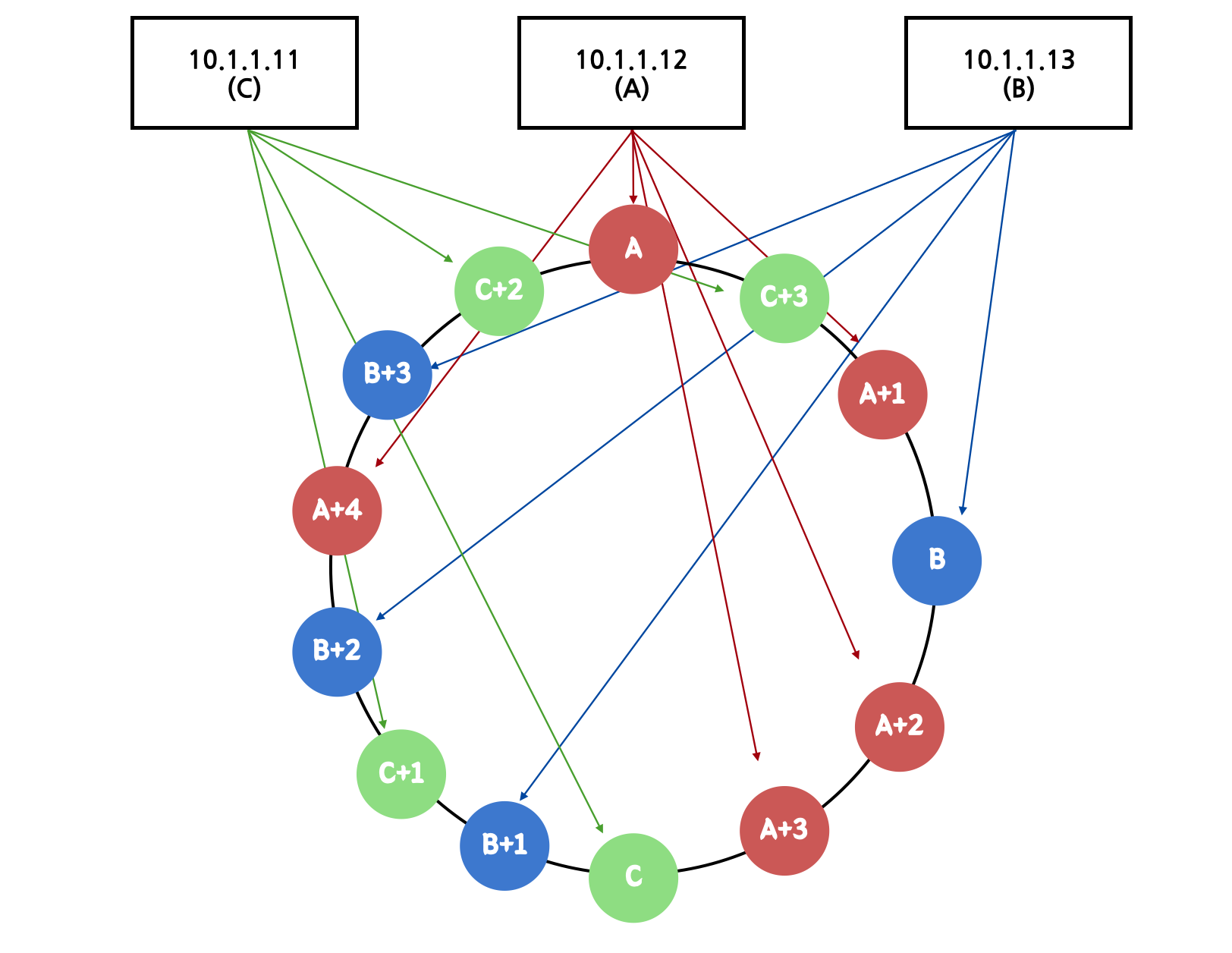
그래서 이를 해결하기 위해 VNode라고 하는 가상의 친구들을 더 만들어낸다. 각 노드에 가상의 친구들을 3개씩 더 만들어보자. 총 3개의 서버를 12개로 보이게 하는 것이다.
- A는 hash(‘A’)외에 hash(‘A+1’), hash(‘A+2’), hash(‘A+3’)를 추가한다.
- B는 hash(‘B’)외에 hash(‘B+1’), hash(‘B+2’), hash(‘B+3’)를 추가한다.
- C는 hash('C')외에 hash(‘C+1’), hash(‘C+2’), hash(‘C+3’)를 추가한다.
A+1, A+2, A+3는 실체는 A이지만 hash ring에서 가상적으로 다른 노드로 보이게 된다. 그림을 보면 알 수 있다시피 hash ring 자체도 더 촘촘해진 것을 볼 수 있다. 이렇게 되면 어떤 서버에서 장애가 발생하더라도 그 부하가 적절하게 나머지 두 서버로 나눠지게 된다. 실제 서비스에서는 서버 당 수십개의 가상 노드를 만들어서 처리한다(2~3개도 너무 적다).
결국 Hash Ring의 핵심은 서버 이름으로 hash 값을 만들어서 정렬한 것을 하나의 Ring처럼 생각해서 key를 hash값에 저장한다는 것이다.
3-6) 별칭으로 Hash해야 하는 이유
위 1-2), 1-3) 예제에서는 Consistent hashing을 많이 쓰는 libmemcached의 서버 주소를 해싱하는 방법을 사용했다.
- “1.1.1.1:11211”, “1.1.1.2:11211”, “1.1.1.3:11211”
그런데 이러한 방식에는 문제가 있다. 만약 1.1.1.2 서버에 장애가 발생하여 새로운 장비를 받아야 하는 상황이 발생했다고 하자. 그런데 그 장비의 IP는 "1.1.1.4"이다. 그러면 이미 적절히 분배된 Hash Ring이 꼬여버릴 수도 있다. 이런 문제를 해결하려면 위의 직접적인 이름 대신에 다른 별칭으로 Consistent Hashing을 구성해줘야 한다.
- redis001, redis002, redis003, redis004 이런 이름으로 Hash Ring을 구성하게 되면 서버를 중간에 교체하더라도 IP주소가 달라도 상관없이 Hash Ring이 꼬이지 않게 된다. 그리고 Consistent hashing의 결과로 가져올 값만 다르게 가져오면 설정해주면 된다.
분산 데이터 처리 알고리즘 Has Slot vs Consistent Hashing
Hash slot과 Consitent hashing 두 알고리즘 모두 해시 함수를 통해 저장 위치를 결정하는 해시 테이블을 사용하며, 분산 컴퓨팅 환경에서 효율적으로 데이터를 저장하는 방법을 제공한다.
redis cluster 모드에 hash slot을 채택한 것은 단순성이다. Hash slot은 슬롯의 수가 고정(16,384) 되어 있어서 배포 메커니즘이 간단하다. 또한 고정 슬롯을 사용하면 노드를 새롭게 추가, 삭제하는 수평 스케일 인/아웃이 상대적으로 효율적이다. 한마디로 말하면 관리가 쉽다.
Consitent hashing은 스케일링 조절에 있어서 발생하는 리밸런싱은 노드 이웃 경계 근처 데이터만 움직이기 때문에 리밸런싱은 더 효율적이다. 하지만 가상 노드, Ring 기반 시스템이라서 다소 관리가 복잡할 수 있다는 단점이 있다. (특히 핫스팟을 방지하고 밸런싱 조절을 해주는 가상 노드는 관리자 입장에서 예측 불가능하기 때문이다)
참고
https://redis.io/docs/manual/scaling/
https://www.slideshare.net/charsyam2
https://ssup2.github.io/theory_analysis/Consistent_Hashing/
https://severalnines.com/blog/hash-slot-vs-consistent-hashing-redis/
'Dot Database > Redis' 카테고리의 다른 글
| 싱글 쓰레드인 Redis가 빠른 이유: In-Memory, I/O Multiplexing (0) | 2023.01.24 |
|---|---|
| [Spring/ Redis] Spring으로 ElasticCache for Redis 사용해보기 (0) | 2022.04.20 |
| [Database] Redis 고가용성을 위한 Sentinel 모드 직접 다뤄보기 (0) | 2022.04.18 |
| [Database] Redis 간단한 사용 방법 (Stand Alone, Replication 기능) (0) | 2022.04.18 |
| [Database] Redis에 대해 알아보자 (Redis 컬렉션, Sentinel, Cluster, 운영시 장애 포인트) (0) | 2022.04.14 |



