
최소 공통 조상 LCA(Lowest Common Ancestor) 알고리즘
LCA(Lowest Common Ancestor)는 주어진 두 노드 a,b의 최소 공통 조상을 찾는 알고리즘이다.
예를들어 아래의 트리에서 5번과 6번노드의 최소 공통 조상 LCA는 2번 노드이다.

일반적인 LCA 풀이방법
- 1번 루트노드를 기준으로 DFS탐색을 하면서 각 노드의 트리의 높이(h)와 부모 노드(parent)를 저장해준다.
- LCA를 구하기 위한 a,b번 노드가 주어지면 해당 두 노드의 h를 일정하게 맞춘다 (a의 높이 == b의 높이)
- 높이가 맞춰졌으면 각 부모노드가 일치할 때 까지 비교하여 구한다. (최대 LCA는 루트노드 1)
LCA를 찾는 과정을 보면 탐색을 할 때 편향트리를 만나게되면 엄청나게 많은 반복을 돌려줘야할 수도 있고, 중복 연산을 할 수도 있다. 그러면 O(NM)이라는 시간복잡도를 갖게 되어 범위가 더 크게 주어질 경우 해당 알고리즘은 느려질 것이다.
그래서 범위가 더 큰 데이터를 다뤄야 할 경우 더 효율적인 방식을 사용하여 구해야한다.
LCA + DP
첫 번째 방식으로는 DP를 활용하는 방법이 있다.
DP 값 할당
일반적인 방법으로 만약 부모노드와 현재노드의 거리가 100이면 100번의 반복을 통해 부모노드를 구해줘야 한다. 하지만 2^h의 부모를 알고 있으면 64+32+4 = 100으로 총 3번 만에 부모노드를 구할 수 있다.
이렇게 DP를 활용하면 편향트리를 만나도 연산횟수를 급격하게 줄여줌으로써 시간복잡도를 O(MlogN)으로 단축시켜준다.
dp 2차원 배열에 해당 cur 노드의 2^h번째 부모노드를 저장해줌으로써 연산 횟수를 줄여주고 중복되는 연산을 제거해준다.
- dp[cur][h]
1. 트리의 최대 높이(h)를 구해준다.
static int getTreeHeight() {
return(int)Math.ceil(Math.log(n)/Math.log(2)) +1;
}
2. DFS탐색을 통해 각 노드의 높이(depth)와 2^0(1)번째 부모노드의 값으로 초기화시켜준다.
dp[cur][0] = 1번째 부모노드
static void init(int cur, int h, int pa) {
depth[cur] = h;
for(int nxt : list[cur]) {
if(nxt != pa) {
init(nxt, h+1, cur);
parent[nxt][0] = cur; // nxt의 부모 cur
}
}
}
3. 나머지 2^0, 2^1, ... , 2^h-1번째의 부모노드를 채워준다.
static void fillParents() {
for(int i=1; i<h; i++) {
for(int j=1; j<n+1; j++) {
parent[j][i] = parent[parent[j][i-1]][i-1];
}
}
}
시뮬레이션으로 해당 트리의 dp값을 할당해보자.
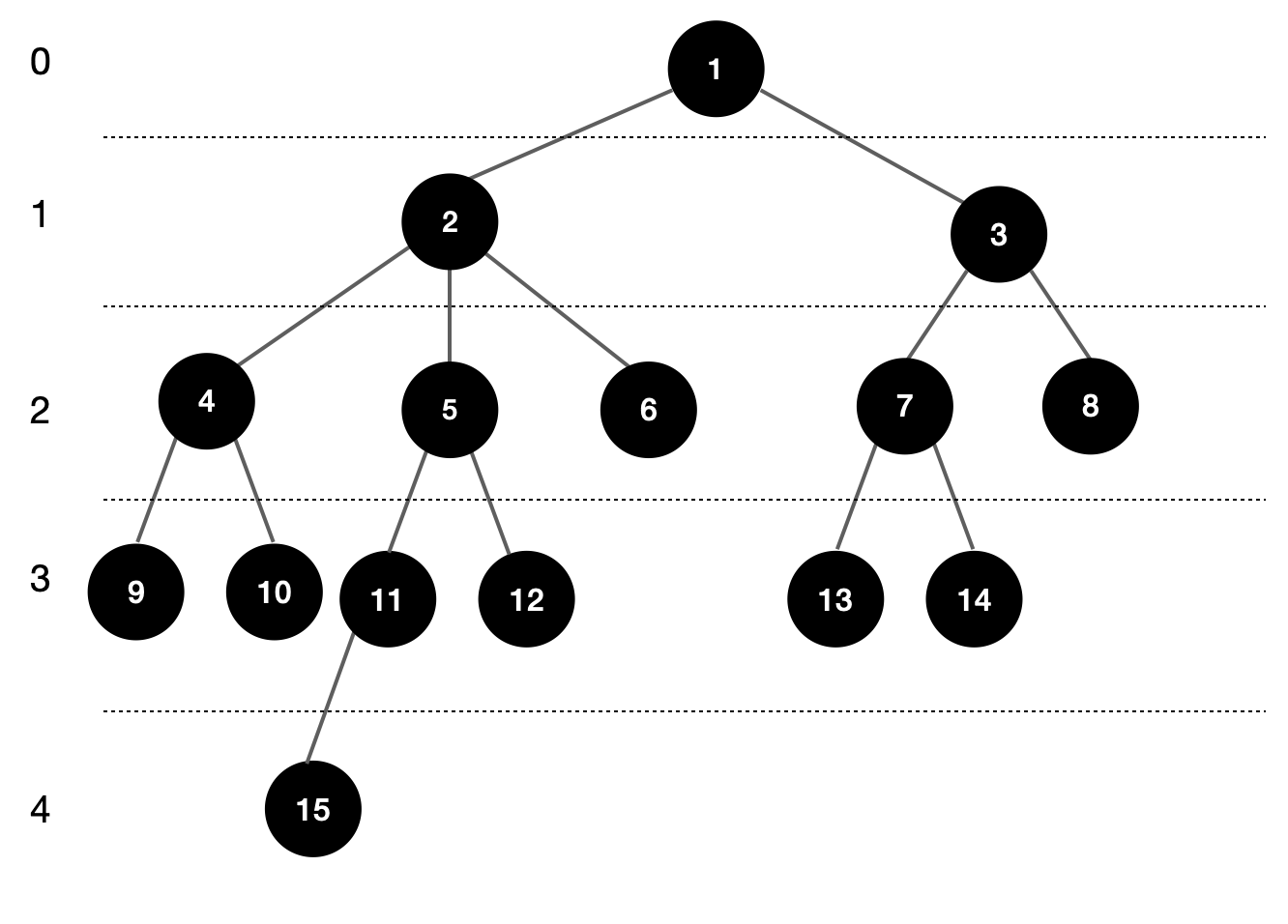
dp[cur][log(h)]의 값은 다음과 같이 저장된다.
| cur | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 1 | 0 | 1 | 1 | 2 | 2 | 2 | 3 | 3 | 4 | 4 | 5 | 5 | 7 | 7 | 11 |
| 2 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 3 | 3 | 5 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
☛ 예로, 15번의 4번째 부모노드 dp[15][log4]= dp[15][2] = 1 임을 알 수 있다.
LCA 구하기
dp값을 모두 할당해줬으면 이제 해당 데이터로 LCA를 구해주면 된다.
- a와 b노드가 주어지면 해당 노드의 높이가 낮은 노드를 기준으로 높이를 맞춰준다.
- 이때 dp에 저장된 2^h부모노드의 정보를 활용하여 연산 횟수를 단축시켜준다.
- 높이를 맞췄는데 a==b이면 LCA = a이므로 바로 출력해준다. (LCA가 1일때 예외처리이기도 함)
- a와 b노드의 dp값을 비교해가며 LCA를 찾아준다.
static int LCA(int a, int b) {
int ah = depth[a];
int bh = depth[b];
// ah > bh로 세팅
if(ah < bh) {
int tmp = a;
a = b;
b = tmp;
}
// 1. 높이 맞추기
for (int i=h-1; i>=0; i--) {
if(Math.pow(2, i) <= depth[a] - depth[b]){
a = parent[a][i];
}
}
if(a==b) return a;
// 2. LCA찾기
for(int i=h-1; i>=0; i--) {
if(parent[a][i] != parent[b][i]) {
a = parent[a][i];
b = parent[b][i];
}
}
return parent[a][0];
}
LCA + 세그먼트 트리
두 번째 방식으로는 세그먼트 트리를 활용하는 방법이 있다.
세그먼트 트리 초기화
세그먼트 트리 리프노드에 트리의 전위 순회한 방문 순서를 노드를 기준으로 저장하여 최소 세그먼트 트리의 형태로 부모 노드에 저장하는 식으로 형성된다. 해당 방식 또한 DP와 마찬가지로 O(MlogN)의 시간복잡도를 가진다.
예를 들어, 1 2 3 4 3 2 5 2 1 6 1의 순으로 전위 순회를 한다면 구간 2~6 (2 3 4 3 2 5)에서 LCA를 구해본다면 2번째 순서를 갖는 노드가 가장 빠른 순으로 조회되기 때문에 LCA임을 알아내는 방식이다.
- 왜 가장 빠른 순서인 노드가 LCA이나면 전위 순회는 root > left > right순으로 조회하므로 부모노드인 root를 가장 빠르게 순회하기 때문이다.
다소 복잡한 풀이로 인해 아래의 트리를 예시로 설명을 하는게 편할 것 같다.

세그먼트 트리를 활용한 LCA 풀이에 필요한 데이터 자료구조는 다음과 같다.
- depth : 해당 노드의 높이 1번 노드 1, 4번노드 3
- trip: 해당 트리 전위 순회 방문순서 ( 1 2 4 6 4 2 5 2 1 3 1 )
- locInTrip : trip에 처음으로 저장된 노드번호 index [0 1 9 2 6 3 ] // 1번노드 trip.get(0), 3번노드 trip.get(9)
- no2serial : 노드 번호에 따른 전위 순회 탐색 순서 [1 2 6 3 5 4] // 3번노드는 6번째 순서로 방문
- serial2no : 전위 순회 탐색 순서에 따른 노드 번호 [1 2 4 6 5 3] // 3번째 순서로 방문한 노드는 4번노드
구상
- 주어진 트리를 전위 순회 탐색한다.
- 노드 번호에 따른 순서(no2serial)를 기록한다.
- 순서에 따른 노드 번호(serial2no)를 기록한다.
- 전위 순회로 방문되는 순서(no2serial)를 차례대로 모두 trip이라는 List 자료구조에 기록해준다. (방문한 노드의 경로도 모두 기록해야 한다.)
- 노드 번호가 첫 방문된 trip의 위치(locInTrip)를 기록한다.
- 1번에서 기록한 전위 순회에 대한 노드 번호 순서(serial2no)를 세그먼트 트리 리프노드에 넣어 초기화 시켜준다.
- 해당 세그먼트 트리는 먼저 탐색한 노드(MIN)를 부모노드에 기록해주어 최소 세그먼트 트리의 형태를 가진다.
- 전위 순회 탐색은 root > left > right순이기 때문에 결국 가장 최솟값은 루트노드가 될 것이다.
- LCA를 구하기 위해 주어진 a,b의 노드가 처음으로 저장된 trip의 index를 찾아준다. (locInTrip[a], locInTrip[b])
- 왜냐하면 해당 index(locInTrip)이 세그먼트 트리 구간이기 때문이다. (ex, a=6, b=5, locInTrip[a]=3, locInTrip[b]=6)
- query문을 사용하여 해당 구간에 가장 먼저 들어온(MIN) 순서를 찾는다.
- 해당 순서에 따른 노드 번호(serial2no)를 출력해주면된다.
로직 1번. traversal (전위 순회)
static void traversal(int cur, int h, int pa) {
depth[cur] = h;
no2serial[cur] = serialNum;
serial2no[serialNum] = cur;
serialNum++;
locInTrip[cur] = trip.size();
trip.add(no2serial[cur]);
for(int nxt : list[cur]) {
if(nxt != pa) {
traversal(nxt, h+1, cur);
trip.add(no2serial[cur]);
}
}
}
로직 2번. init (최소 세그먼트 트리 초기화)
static int init(int start, int end, int node) {
if(start == end) {
return tree[node] = trip.get(start);
}
int mid = (start+end)/2;
return tree[node] = Math.min(init(start, mid, node*2), init(mid+1, end, node*2+1));
}
로직 3번. query (a,b 노드의 LCA 찾기)
해당 query는 LCA의 해당 구간에 가장 먼저 들어온 순서를 출력하기 때문에 답은 해당 순서에 따른 노드 번호 serial2no[lca]를 출력해줘야 한다.
static int query(int start, int end, int left, int right, int node) {
if(right < start || end < left) return Integer.MAX_VALUE;
if(left <= start && end <= right) {
return tree[node];
}
int mid = (start+end) /2;
return Math.min(query(start, mid, left, right, node*2),
query(mid+1, end, left, right, node*2+1));
}
성능 비교
자세히 비교해보면 DP는 O(NlogN + MlogN)이고 세그먼트 트리는 O(N + MlogN)이다. 그러므로 풀이 결과 DP를 활용환 최적화 풀이보다 세그먼트 트리를 이용한 풀이가 연산속도가 더 빠른 것을 볼 수 잇다.


그러나 세그먼트 트리는 자료구조가 간단하게 설계되어 있지 않아서 구현이 상당히 복잡하다 실제로 공간복잡도는 좀 더 높은 것을 볼 수 있다. 효율성을 위한 알고리즘 설계가 아니라면 평소에는 DP로 접근하고 후에 성능 이슈를 다룰 때 세그먼트 트리를 활용하는 것이 좋을 듯 싶다.
'Dot Algo∙ DS > 알고리즘 개념' 카테고리의 다른 글
| [알고리즘] 최장 공통 부분 수열 LCS - DP & 이진탐색 LIS (Java) (0) | 2021.08.10 |
|---|---|
| [알고리즘] 가장 긴 증가하는 부분 수열 LIS - DP & 이진탐색 (Java) (2) | 2021.08.09 |
| [자료구조] 세그먼트 트리 + Lazy Propagation (Java) (0) | 2021.07.08 |
| [알고리즘] 투 포인터와 슬라이딩 윈도우 (Java) (0) | 2021.07.07 |
| [알고리즘] 순열, 조합 알고리즘 정리 (Java) (0) | 2021.06.22 |



