
매칭 문제 (Matching Problem)
N명의 유치원생이 소풍을 가는데, 단독 행동을 막기 위해 둘씩 짝을 이뤄 같이 다니게 하려고 한다. 단 서로 사이가 안 좋은 학생끼리 짝을 지어 주면 떨어져서 따로 다니기 때문에, 사이가 좋은 학생끼리만 짝을 지어 주고 싶다.
- 이런 규칙 하에서 모든 학생에게 짝을 지어 줄 수 있을까?
- 불가능하다면 최대 몇 쌍이나 만들 수 있을까?
그래프로 간단하게 표현할 수 있다. 각 학생을 표현하는 정점을 만든 뒤, 사이 좋은 학생들을 간선으로 연결한다. 이때 서로 짝을 이룬 학생들을 연결하는 간선들을 모아 보면, 이들은 끝점을 공유하지 않는 간선의 집합이 된다. 이런 간선의 집합을 이 그래프의 매칭(matching)이라고 부른다.
- (a) 굵은 회색으로 표시한 간선들은 끝점을 공유하지 않기 때문에 올바른 매칭 결과이다.
- (b) 반대로 굵은 회색으로 표시한 간선들이 끝점을 공유하는 경우가 있으므로 올바른 매칭이 아니다.
- 이때 가장 큰 매칭을 찾아내는 문제를 최대 매칭 문제(maximum matching), 흔히 매칭 문제라고 부른다.

매칭 문제는 앞에서 소개한 바와 같이 직관적인 정의를 가진 중요한 문제이다. 하지만 모든 그래프에 대해 매칭 문제를 해결하는 일반적인 알고리즘(Edmond's matching alogrithm)은 꽤나 복잡하고 까다롭다. 덕분에 대회에서는 매칭의 좀더 단순한 형태가 자주 등장하는데, 바로 이분 그래프에서 최대 매칭을 찾는 것이다.
이분 그래프 (Bipartite Graph)
정점을 두 그룹으로 나눠서 모든 간선이 서로 다른 그룹의 정점들을 연결하도록 할 수 있는 그래프들을 이분 그래프라고 한다. 다음 그림은 단순한 이분 그래프의 예를 보여준다.
- 정점의 집합을 검은색과 흰색으로 나눠보면, 모든 간선이 서로 다른 색의 정점을 연결하고 있는 것을 볼 수 있다.
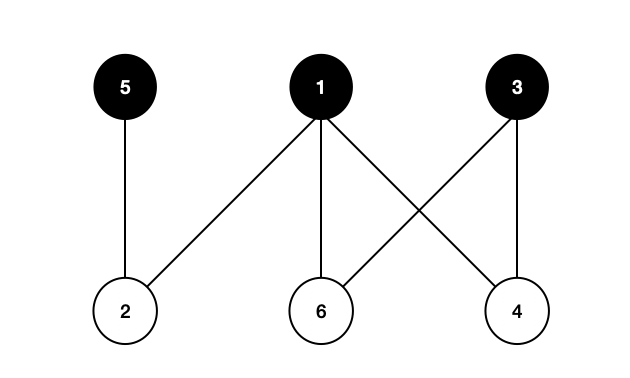
이분 그래프로 작업 배분하기
이분 그래프는 두 집합 간의 대응 관계를 표현하기 위해 흔히 사용된다. 가장 전형적인 예로 작업 배분을 들 수 있다. N명의 사람들에게 N개의 작업을 하나씩 배정하려는데, 모든 사람이 다 모든 작업을 할 수 있는 것은 아니라고 하자. 이와 같은 제약 조건을 이분 그래프로 쉽게 표현할 수 있다.
- 각 사람을 나타내는 정점과 작업을 나타내는 정점들을 갖는 그래프를 만든 뒤,
- 각 사람과 그 사람이 할 수 있는 작업을 간선으로 연결하면 된다.
- 이와 같은 이분 그래프에서 최대 매칭은 가능한 한 많은 작업과 사람을 짝지을 수 있는 방법을 나타낸다.
이렇게 이분 그래프는 현실 세계에서 직관적인 의미를 가지기 때문에 중요하다. 앞으로는 이분 그래프에서 최대 매칭을 찾는 문제를 간단하게 이분 매칭(Bipartite Matching)이라고 부른다.
이분 매칭 (Bipartite Matching)
네트워크 유량과 연계되는 개념인 이분 매칭(Bipartite Matching) 알고리즘 문제이다.
- 이분 매칭은 이분 그래프에서 최대 매칭을 찾는 문제를 간단하게 이분 매칭이라고 부른다.
이분 매칭은 네트워크 유량을 이용하면 쉽게 풀 수 있다. 이 때 모든 간선의 용량은 1로 한다.
- 왼쪽에 있는 정점들을 그룹 A, 오른쪽 정점들을 그룹 B라고 하자.
- 그룹 A의 왼쪽에 소스를 추가하고, 그룹 B의 오른쪽에 싱크를 추가하자.
- 그 후 소스에서 A의 모든 정점으로 간선을 연결하고, B의 모든 정점에서 싱크로 간선을 연결하면 유량 네트워크를 만들 수 있다.
이 그래프의 최대 유량을 구한 뒤 유량이 흐르는 간선들을 모으면 최대 매칭이 되는 것이다.

이분 매칭 (Bipartite Matching) 구현
포드-폴커슨 알고리즘을 응용해 이분매칭을 구현할 수 있지만, 이분 매칭은 네트워크 유량보다 출제 빈도수가 높기 때문에 좀더 단순한 형태의 코드를 알아 둘 필요가 있다. 알고리즘 자체는 다를 게 없지만 이분 그래프의 단순한 형태를 이용하기 때문에 구현이 더 간략해진다.
시뮬레이션
이분 매칭 구현은 포드-폴커슨 알고리즘처럼 증가 경로를 찾은 뒤 유량을 보내는 것을 반복해주면 된다. 백준 2188번 축사 배정에서 주어진 예제를 통해 시뮬레이션을 돌려보자.
1번 소 축사 배정하기
- 1번 소는 (2, 5)에 매칭이 가능하므로, 일단 2번에 매칭한다.

2번 소 축사 배정하기
- 1번 소는 (2, 5),
- 2번 소는 (2, 3, 4)에 매칭이 가능하다.
- 2번 소가 가장 먼저 도착한 축사는 2이다. 따라서 1번 소가 다른 축사 배정이 가능한지 확인하고 가능하면 배정을 바꿔준다.
- 1번 소는 5, 2번 소는 2에 매칭한다.

3번 소 축사 배정하기
- 3번 소는 (1, 5)에 매칭이 가능하므로, 1번에 매칭한다.

4번 소 축사 배정하기
- 4번 소는 (1, 2, 5)에 매칭이 가능하다.
- 1번 매칭? (재귀로 탐색함)
- 3번 소가 5번에 매칭해야 된다.
- 그러려면 5번을 점유하고 있는 1번 소가 2번에 매칭해야 된다.
- 그러면 2번을 점유하고 있는 3번에 매칭해야 된다.
- 따라서 (1번 소 - 2), (2번 소 - 3), (3번 소 - 5), (4번 소 - 1)로 매칭이 된다.

5번 소 축사 배정하기
- 5번 소는 (2)에 매칭이 가능한데, 2번에 매칭하려면 최종적으로 재귀 탐색을 해보면 4번 소가 다른 곳을 매칭해야 되는데 (1, 2, 5)모두 소들이 점유하고 있으므로 재매칭이 안된다.
- 따라서, 5번 소는 축사를 배정할 수 없다.
전체 코드
이 코드가 이용하는 첫 번째 속성은 이분 매칭을 푸는 유량 네트워크에서 최대 유량은 O(|V|)로 정해져 있다는 것이다. 이렇게 최대 유량이 제한되어 있는 경우 DFS을 사용해도 문제없다. 그래서 총 시간 복잡도는 O(V*E)이다.
import java.io.*;
import java.util.*;
public class Main {
static List<Integer>[] list;
static boolean[] check;
static int[] d;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
list = new ArrayList[n+1];
for(int i=1; i<=n; i++) {
list[i] = new ArrayList<>();
}
check = new boolean[m+1];
d = new int[m+1];
for(int i=1; i<=n; i++) {
st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
for(int j=0; j<s; j++) {
list[i].add(Integer.parseInt(st.nextToken()));
}
}
int cnt = 0;
// 1번 ~ n번 소 순차대로 축사 배정
for(int i=1; i<=n; i++) {
Arrays.fill(check, false);
if(dfs(i)) cnt++; // 축사가 배정되었으면 cnt
}
System.out.println(cnt);
}
static boolean dfs(int here) {
for(int nxt : list[here]) {
if(!check[nxt]) {
check[nxt] = true;
// 비어있거나 점유 노드에 더 들어갈 공간이 있는 경우
if(d[nxt] == 0 || dfs(d[nxt])) {
d[nxt] = here;
return true;
}
}
}
return false;
}
}
'Dot Algo∙ DS > 알고리즘 개념' 카테고리의 다른 글
| [알고리즘] 균형잡힌 이진 검색 트리 Balanced BST - 트립(Treap) (Java) (0) | 2022.01.17 |
|---|---|
| [알고리즘] 펜윅 트리(Fenwick Tree) 빠르고 간단한 구간 합 구하기 (Java) (0) | 2022.01.03 |
| [알고리즘] 네트워크 유량, 포드-폴커슨(Ford-Fulkerson) 알고리즘 (Java) (0) | 2021.12.27 |
| [알고리즘] SCC(Strongly Connected Component) (백준 2150번 풀이) (0) | 2021.12.05 |
| [알고리즘] 단절점 (백준 11266번 풀이) (0) | 2021.12.03 |



