
해시 테이블 Hash Table
해시 테이블은 키를 저장하거나 해당 키와 관련된 값을 저장하는 데 사용되는 자료구조다. 삽입, 삭제, 조회가 평균 O(1) 시간에 수행된다.
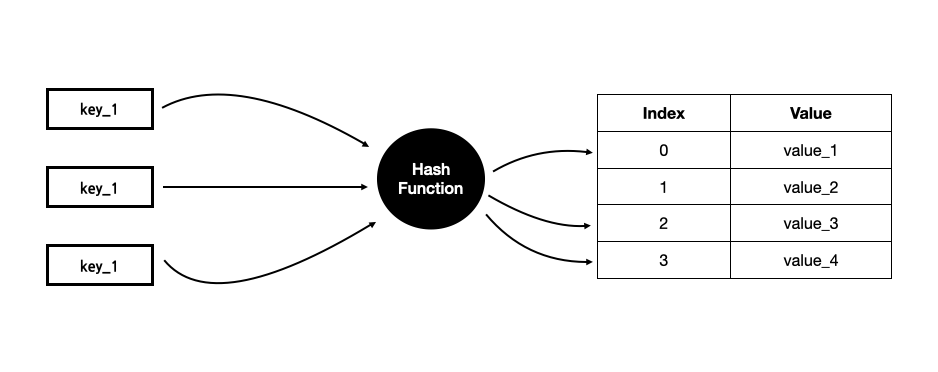
기본 개념은 키를 배열에 저장하는 것이다. 배열에 저장되는 위치(슬롯)는, 키를 '해시 코드(hash code)'한 결과에 따라 결정된다. 해시 코드란 키값에 해시 함수를 적용해서 계산된 정수값을 말한다. 해시 함수를 잘 고른다면, 객체를 배열에 균일하게 분배할 수 있다.
해시 충돌 Hash Collision
1) 연결리스트를 통해 객체 저장
다른 두 개의 키가 동일한 위치(해시 코드가 일치)로 매핑되면 충돌이 발생했다고 한다. 충돌을 처리하는 일반적인 방법 중 하나는 각 배열의 인덱스에서 연결리스트를 통해 객체를 저장하는 것이다.
해시 함수가 객체를 충분히 균등하게 저장할 만큼 잘 동작하고 해시 코드를 계산하는 데 O(1) 시간이 걸린다면, 조회, 삽입, 삭제 연산을 하는 데 평균적으로 O(\(n+m\over m\))시간이 걸린다. n은 객체의 개수이고, m은 배열 길이이다. n은 계속 커지는 데, m이 그대로면 \(n\over m\)의 값도 증가한다. 해당 방식은 갈수록 성능 저하를 일으키게 된다.
2) 해시 테이블에 재해싱 적용
이 때는 해시 테이블에 재해싱(rehashing)을 적용해야 한다. 더 많은 공간을 이루어진 새로운 배열을 할당하고, 객체를 새로운 배열로 옮긴다. 더 많은 공간으로 이루어진 새로운 배열을 할당하고, 객체를 새로운 배열로 옮긴다. 재해싱은 O(n+m) 시간이 걸리는 만큼 비용이 큰 연산이지만, 재해싱이 드물게 발생한다면, 분할 상환 비용은 낮아진다.
- 예를 들어 크기를 두배로 늘릴 때마다 재해싱이 이루어진다면, 매번 조회, 삽입, 삭제 연산을 O(1 + \(n\over m\))로 이루는 것보다 O(1)로 진행하고 1번 재해싱 O(n+m)을 하는 것이 성능상 더 효율적이다.
- T*O(1 + \(n\over m\)) vs T*O(1) + O(n+m) 이를 요약하면 \(T \over m\) vs 1 + \(m \over T\)가 된다. 이 때 m은 양수이고, T는 연산이 이루어질수록 계속해서 증가하기 때문에 많은 연산이 이루어질 수록 전자의 경우의 값이 훨씬 커지게 된다.
해시 테이블 비교하기
vs 정렬된 배열
해시 테이블은 정렬된 배열과 질적으로 다르다. 해시 테이블은 키가 순서대로 저장될 필요가 없으며, 랜덤화(특히, 해시 함수)가 중심 역할을 한다.
vs 이진 탐색 트리
재해싱이 드물게 발생한다는 가정하에 이진탐색 트리(BST)와 비교해보면 해시 테이블에서의 삽입과 삭제 연산이 훨씬 효율적이다. 해시 테이블에 단점이 있다면 좋은 해시 함수가 필요하다는 점인데 실무에선 크게 문제가 되지 않는다. 이와 비슷하게 재해싱도 실시간 시스템이 아니라면 크게 문제되지 않고, 실시간 시스템이라 해도 다른 스레드를 사용해서 재해싱을 하면 된다.
해시 함수
해시 함수의 필수 요구사항 중 하나는 키값이 같으면 해시 코드도 같아야 한다는 점이다. 데이터 자체가 아닌 주소값을 이용해 해시 함수를 만든다든가 프로필 데이터를 포함해서 해시 함수를 만든다면 키값이 같더라도 해시 코드가 달라질 수 있다.
- 필수는 아니지만 좋은 해시 함수는 키를 가능한 한 널리 퍼뜨린다. 즉, 객체의 부분 집합에 대한 해시 코드가 배열 전체에 걸쳐 균등하게 분배되는 게 좋다. 또한 효율적으로 계산하는 해시 함수가 좋다.
- 실수는 해시 테이블에 있는 키값을 갱신할 때 발생할 수 있다. 잘못하면 해당 키가 해시 테이블에 있더라도 찾지 못할 수 있다. 키값을 갱신하고 싶으면 먼저 해당 키를 제거하고 갱신한 뒤, 해당 키값을 다시 해시 테이블에 추가해야 한다. 그래야 갱신된 키를 새로운 위치로 옮길 수 있다. 기본적으로 가변 객체(mutable object)를 키로 설정하면 안 된다.
해시 함수 설계 방법
해시 함수는 문자열의 모든 문자를 사용해야 한다. 넓은 범위의 값을 생성해야 하고, 문자 하나가 해시 코드를 결정짓도록 해서는 안 된다.
- 예를 들어 문자를 숫자로 바꾼 뒤 이 들을 모두 곱한값을 해당 문자열의 해시코드라 해 보자. 0으로 매핑되는 문자가 하나라도 있다면, 해시 코드가 언제나 0이된다.
또한, 롤링 해시(rolling hash), 즉 문자열 맨 앞의 문자를 삭제하고 맨 뒤에 문자를 추가하는 방식의 해시 함수는 새로운 해시 코드 O(1) 시간 내에 계산할 수 있다. 다음 해시 함수가 이러한 롤링 해시의 속성을 가지고 있다.
public static int stringHash(String str, int modulas){
int kMult = 997;
int val = 0;
for(int i=0; i<str.length(); i++){
char c = str.charAt(i);
val = (val * kMult + c) % modulas;
}
return val;
}
해시 테이블은 사전, 즉 문자열 집합을 표현하기 좋은 자료구조이다. 트라이(Trie)라는 트리 자료구조는 동적으로 변하는 문자열 집합을 저장할 때 유용한데, 애플리케이션이 트라이를 사용하면 계산이 효율적이다. 트라이는 이진 탐색 트리와 달리 노드에 키를 저장하지 않고 노드의 위치 자체가 키가 된다.
'Dot Algo∙ DS > 자료구조' 카테고리의 다른 글
| [자료구조] 힙(Heap) 구현하기 - 우선순위 큐 (Java) (0) | 2022.01.05 |
|---|---|
| 트라이(Trie) 문자열 탐색 트리 개념 정리 (Java) (0) | 2021.09.08 |
| [자료구조] 세그먼트 트리 Segment Tree (Java) (0) | 2021.06.16 |
| [자료구조] BinaryTree 정리 (Java) (0) | 2021.04.09 |
| [자료구조] Stack와 Queue 정리 (Java) (0) | 2021.04.06 |



