
깊이 우선 탐색 DFS
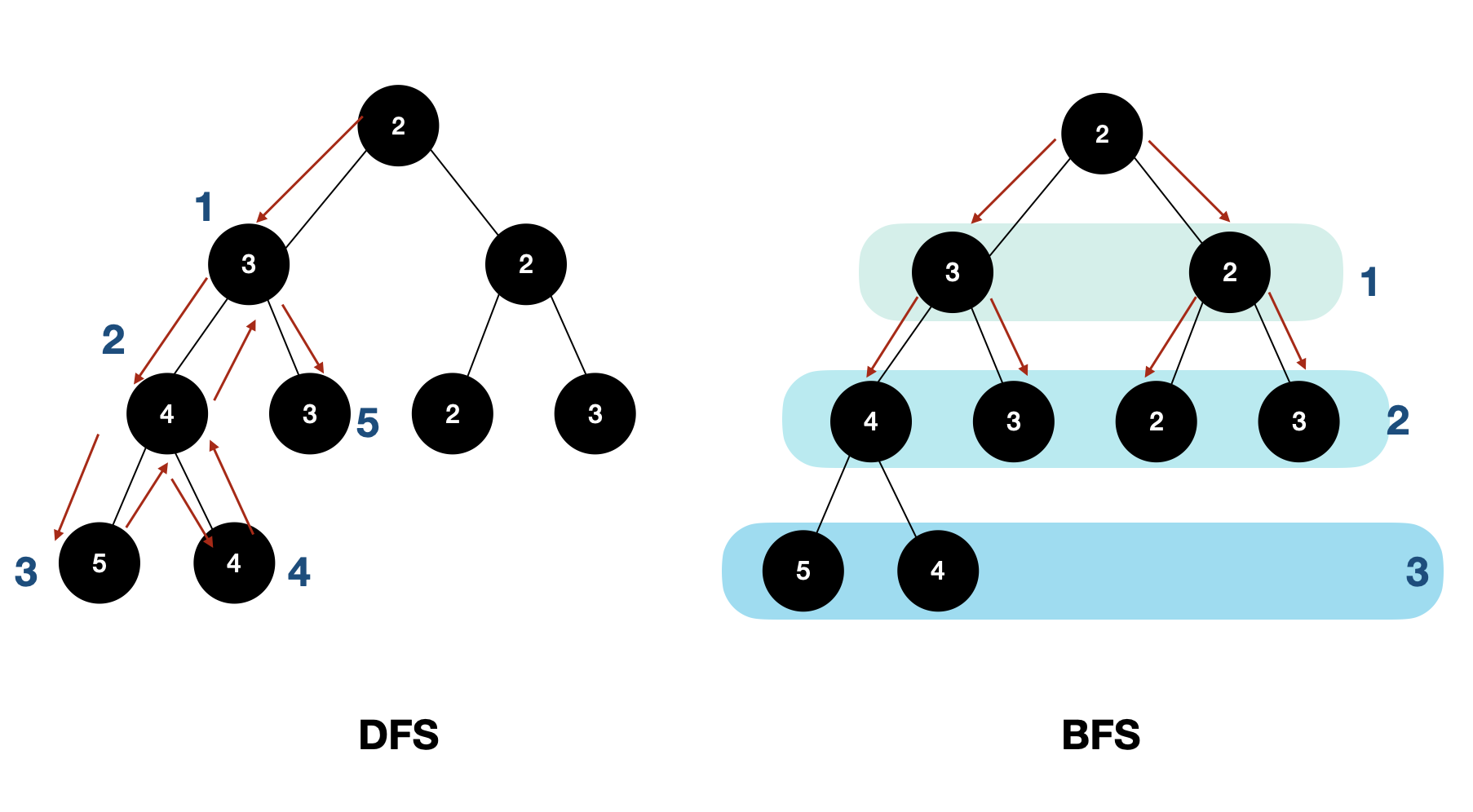
각 정점 노드를 깊게 탐색하는 방식으로 매 탐색을 stack으로 쌓으면서 갈 수 있는 최대한 깊이를 탐색하고 갈 곳이 없다면 이전 정점으로 돌아간다.
- 모든 정점을 발견하는 가장 단순하고 고전적인 방법이다.
- 현재 정점과 인접한 간선들을 하나씩 검사하다가, 아직 방문하지 않은 정점으로 향하는 간선이 있다면 그 간선을 무조건 따라간다. 더이상 갈 곳이 없는 막힌 정점에 도달하면 포기하고, 마지막에 따라왔던 간선을 뒤돌아간다.
깊이 우선 탐색은 탐색의 각 과정에서 가능한 한 그래프 안으로 깊이 들어가려고 시도하며, 막힌 정점에 도달하지 않는 한 뒤로 돌아가지 않는다.
인접 행렬 DFS
DFS 하나에 for loop을 V번을 탐색하기 때문에 O(V) , 정점을 방문할 때 마다 DFS를 부르는데, V개의 정점을 모두 방문하므로 O(V) 이다. 따라서 인접행렬 DFS의 전체 시간복잡도 = V * O(V) = O(V^2) 이다
void dfs(int x){
check[x] = true;
for(int i = 1; i <= V ; i++){
if(graph[x][i] == 1 && !check[i]){
dfs(i);
}
}
}
인접 리스트 DFS
인접리스트로 구현할 경우, DFS 하나당 각 정점에 연결되어 있는 간선의 개수만큼 탐색을 하게 되어 DFS 하나의 수행 시간이 일정하지 않다. DFS를 총 모든 정점인 V번 탐색하고 DFS의 정점마다 인접한 노드 E번을 검사하므로 O(V+E)
그래서 인접리스트로 구현할 경우 O(V+E)의 시간이 걸린다고 말할 수 있다.
- Java에서의 인접리스트는 Arraylist[] 방식이나 ArrayList<new ArrayList<>()>() 등이 있다.
void dfs(List[] list, boolean check, int x) {
check[x] = true;
for(int i = 0; i < list[x].size(); i++){
int next = (int)list[x].get(i);
if(!check[next])
dfs(next);
}
}
너비 우선 탐색 BFS
가까운 인접 노드부터 탐색하는 방식으로 재귀함수가 쓰이지않고 queue를 사용해서 현재 노드에서 인접해 있는 노드를 queue에 넣는 방식으로 작동한다.
- 다익스트라, 프림 알고리즘은 BFS를 근간으로 이루어진 알고리즘이다.
- DFS에 비해 동작 과정은 비교적 이해하기 쉽다.
너비 우선 탐색은 각 정점을 방문할 때마다 모든 인접 정점들을 검사한다. 이 중 처음 보는 정점을 발견하면 이 정점을 방문 예정이라고 기록해 둔 뒤, 별도의 위치에 저장한다. 인접한 정점을 모두 검사하고 나면, 지금까지 저장한 목록에서 다음 정점을 꺼내서 방문하게 된다.
- 따라서 너비 우선 탐색의 방문 순서는 정점의 목록에서 어떤 정점을 먼저 꺼내는지에 의해 결정된다.
모든 정점은 세가지 상태를 거치게 된다.
- 아직 발견되지 않은 상태 (!check[i])
- 발견되었지만 방문하지 않은 상태
- 방문된 상태 (check[i])
인접 행렬 BFS
시간 복잡도를 계산할 때 가장 핵심이 되는 코드는 if(graph[now][i] == 1 && !check[i]) 부분이다. 정점 하나당 for loop으로 인해 해당 코드가 실행하는데 O(V)이다. 게다가, 이 for loop은 while loop을 통해 모든 정점을 한 번씩 방문할 때마다 실행되므로 V번 반복이므로 인접 행렬로 구현할 경우 BFS의 시간 복잡도 = V * O(V) = O(V^2) 이다. (for문 V * while문 V)
void BFS(int v, int start){
queue<Integer> q = new LinkedList<>();
boolean check[] = new boolean[v+1];
check[start] = true;
q.add(start);
while(!q.empty()){
int now = q.poll();
for(int i = 1; i <= v; i++){
if(graph[now][i] == 1 && !check[i]) {
check[i] = true;
q.add(i);
}
}
}
}
인접 리스트 BFS
인접 리스트를 바탕으로 구현된 DFS의 시간 복잡도를 구할 때와 비슷한 논리로 시간 복잡도를 구할 수 있다. BFS 또한 인접리스트로 구현하면 for loop를 인접한 노드만 반복하므로 총 E번이므로 각 정점을 한 번씩 모두 방문하여 V의 시간이 걸릴 것이다. 따라서, 인접 리스트로 구현한 BFS의 시간 복잡도는 O(V+E) 이다.
void BFS(List[] list,int v, int start){
Queue<Integer> q = new LinkedList<>();
boolean check[] = new boolean[v+1];
check[start] = true;
q.add(start);
while(!q.empty()){
int now = q.poll();
for(int i = 0; i < list[now].size(); i++){
int next = (int)list[now].get(i);
if(!check[next]){
check[next] = true;
q.add(next);
}
}
}
}
BFS와 DFS 시간복잡도 비교
BFS / DFS 둘 다 인접행렬보다 인접리스트 방식으로 구현하는 것이 더 효율적이다.
| 인접행렬 | 인접리스트 | |
| DFS | O(V^2) | O(V+E) |
| BFS | O(V^2) | O(V+E) |
BFS / DFS 언제 어느 것을 사용해야하나?
각각의 장단점이 있으므로 문제의 유형을 잘 파악하고 그에 적합한 방식을 대입하는 것이 중요하다
- 모든 노드를 방문하고자 하는 경우에 DFS를 선택함
- 깊이 우선 탐색(DFS)이 너비 우선 탐색(BFS)보다 좀 더 간단함
- 검색 속도 자체는 너비 우선 탐색(BFS)이 더 빠름
따라서
- 검색 대상 그래프가 정말 크다면 DFS (깊이우선)
- 검색 대상의 규모가 크지 않고, 검색 시작 지점으로부터 원하는 대상이 별로 멀지 않다면 BFS (너비우선)을 선택하자.
문제 유형별로 따지면 다음과 같다.
1) 그래프의 모든 정점을 방문하는 것이 주요한 문제
단순히 모든 정점을 방문하는 것이 중요한 문제의 경우 DFS, BFS 두 가지 방법 중 어느 것을 사용해도 상관없다
→ 둘 중 편한 것 사용
2) 경로의 특징을 저장해둬야 하는 문제
예를 들면 각 정점에 숫자가 적혀있고 a부터 b까지 가는 경로를 구하는데 경로에 같은 숫자가 있으면 안 된다는 문제 등, 각각의 경로마다 특징을 저장해둬야 할 때는 DFS를 사용한다
→ BFS는 경로의 특징을 가지지 못함
3) 최단거리 구해야 하는 문제
미로 찾기 등 최단거리를 구해야 할 경우, BFS가 유리하다. 왜냐하면 깊이 우선 탐색으로 경로를 검색할 경우 처음으로 발견되는 해답이 최단거리가 아닐 수 있지만, 너비 우선 탐색으로 현재 노드에서 가까운 곳부터 찾기 때문에 경로를 탐색 시 먼저 찾아지는 해답이 곧 최단거리기 때문이다.
→ 최단거리는 BFS
'Dot Algo∙ DS > 알고리즘 개념' 카테고리의 다른 글
| [알고리즘/ 그래프] 위상 정렬 (topology Sort) (Java) (0) | 2021.04.23 |
|---|---|
| [알고리즘/ 그래프] 최소 스패닝 트리 - 크루스칼(Kruskal)과 프림(Prim) 알고리즘 (Java) (0) | 2021.04.22 |
| [알고리즘/ 그래프] 서로소 집합 자료구조 Union-find (Java) (0) | 2021.04.21 |
| [알고리즘] 동적계획법 DP (Dynamic Programming) 정리 (Java) (7) | 2021.03.09 |
| [알고리즘/ 그래프] 다익스트라(Dijkstra) vs 플로이드 와샬(Floyd Warshall) (JAVA) (0) | 2021.03.05 |



