
#2352 반도체 설계
난이도 : 골드 2
유형 : 이진탐색/ DP
2352번: 반도체 설계
첫째 줄에 정수 n(1 ≤ n ≤ 40,000)이 주어진다. 다음 줄에는 차례로 1번 포트와 연결되어야 하는 포트 번호, 2번 포트와 연결되어야 하는 포트 번호, …, n번 포트와 연결되어야 하는 포트 번호가 주
www.acmicpc.net
▸ 문제
반도체를 설계할 때 n개의 포트를 다른 n개의 포트와 연결해야 할 때가 있다.
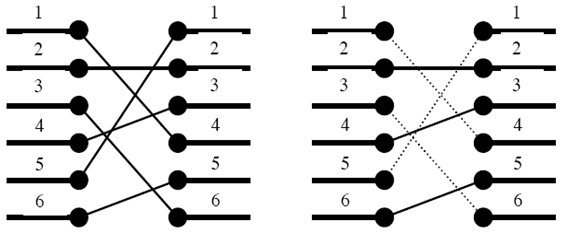
예를 들어 왼쪽 그림이 n개의 포트와 다른 n개의 포트를 어떻게 연결해야 하는지를 나타낸다. 하지만 이와 같이 연결을 할 경우에는 연결선이 서로 꼬이기 때문에 이와 같이 연결할 수 없다. n개의 포트가 다른 n개의 포트와 어떻게 연결되어야 하는지가 주어졌을 때, 연결선이 서로 꼬이지(겹치지, 교차하지) 않도록 하면서 최대 몇 개까지 연결할 수 있는지를 알아내는 프로그램을 작성하시오
▸ 입력
첫째 줄에 정수 n(1 ≤ n ≤ 40,000)이 주어진다. 다음 줄에는 차례로 1번 포트와 연결되어야 하는 포트 번호, 2번 포트와 연결되어야 하는 포트 번호, …, n번 포트와 연결되어야 하는 포트 번호가 주어진다. 이 수들은 1 이상 n 이하이며 서로 같은 수는 없다고 가정하자.
▸ 출력
첫째 줄에 최대 연결 개수를 출력한다.
문제 풀이
먼저 해당 문제의 풀이는 선이 꼬이지 않기 위해서는 연결되는 수가 역행을 하면 안되기 때문에 가장 긴 증가하는 부분 수열(LIS)임을 알 수 있다. LIS의 풀이로는 이중 포문을 사용하여 일반 DP로 풀거나 좀 더 효율적인 탐색을 위해 이진탐색을 곁들여 푸는 방법이 있다.
해당 문제 정수의 최댓값은 4만이기 때문에 이중 포문을 사용해도 O(n^2)으로 가까스로 풀이가 가능하지만 위험한 방법이다. 거의 16억번의 연산이 이루어지기 때문이다.

LIS 최적화 풀이
그래서 잘 알려진 방법으로 최적화된 LIS 풀이 방법이 있다. 해당 풀이의 핵심 키는 '매 탐색마다 길이가 len인 LIS들의 마지막 값중 최솟값'을 찾아주는 것이다.
시뮬레이션을 통해 위의 핵심 키를 어떻게 도출해는지 알아보자.
- 총 4번의 탐색을 통해 [ 5, 6, 2, 3 ]의 원소를 알아냈다.
- LIS1 = [5, 6]
- LIS2 = [2, 3]
- 다음 탐색을 통해 7를 알아냈다. [ 5, 6, 2, 3 ,7 ]
- LIS1 = [5, 6, 7]
계속해서 연산을 진행한다고 했을 때 현재까지 구한 LIS의 정보는 과연 의미가 있을까? 반반이다. 한마디로 매 탐색을 통해 얻어내는 LIS의 데이터에 의존하기에는 불확실한 미래가 펼쳐진다.
길이가 len인 LIS들의 마지막 값중 최솟값
그런데 항상 데이터들을 최적화되게 찾아올 수 있는 방법이 있다. 길이가 len인 LIS들의 마지막 값중 최솟값을 저장하는 것이다. 왜냐하면 배열의 첫 4개 원소가 [5, 6, 2, 3]일 때 길이가 2인 LIS는 [5, 6], [2, 3]이 있다. 그 다음 수가 무엇이 될지 모르겠지만 작은 정보를 유지할 때는 LIS를 문제없이 구할 수 있다.
- 마지막 수가 4일 때나 11111일 때 모두 [2,3]은 LIS를 만들어 낼 수 있지만 [5,6]일 때는 만들어내지 못한다.
- 또, 마지막 수가 7일 때를 보면 [5,6]은 LIS를 만들어낼 수 있고 또한 [2,3]도 만들어낼 수 있다.
즉, 같은 크기의 증가수열에서 마지막 값 중 최솟값만 기억하면 다음 LIS, 즉 최적화된 단서를 알아낼 수 있다는 것이다.
- [5, 6, 2, 3, 7]의 데이터를 통해 구해보면 다음과 같다.
- 길이가 1인 LIS들의 ([5], [6], [2], [3], [7]) 의 마지막 값중 최솟값은 2이다.
- 길이가 2인 LIS들의 ([5, 6], [2, 3]) 의 마지막 값중 최솟값은 3이다.
- 길이가 3인 LIS들의 ([5, 6, 7], [2, 3, 7]) 의 마지막 값중 최솟값은 7이다.
이진탐색
이제 위의 탐색을 하는 과정에서 dp에 저장되는 값은 자동 오름차순으로 저장되는 것을 알 수 있기 때문에 이진탐색을 사용해서 연산 횟수를 낮출 수 있다.
[4, 2, 6, 3, 1, 5]의 배열을 시뮬레이션을 돌려보면 다음과 같다.
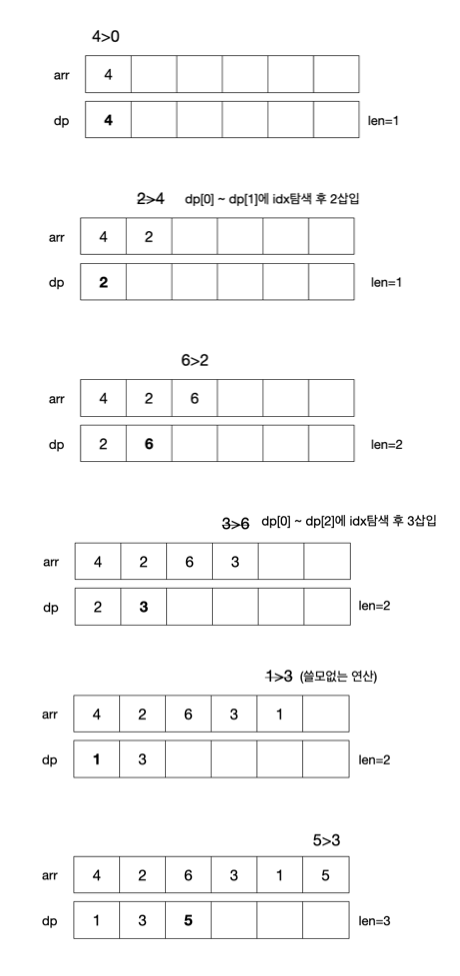
설계
- if(arr[i] > dp[len]) 새로운 숫자(arr[i])이 현재 dp[len]의 값보다 크다면 새로운 LIS가 갱신된다.
- dp[++len] = num;
- if(arr[i] <= dp[len]) 새로운 숫자(arr[i])이 수열 최솟값과 최댓값 사이에 있는 값이라면 이진탐색을 통해 기존 값을 바꿔준다.
- 이진탐색을 통해 dp[i-1] <= arr[i] <= dp[i]인 곳을 찾아(idx) 값을 갱신해준다.
- dp[idx] = arr[i];
- 모든 탐색이 끝나면 len이 해당 LIS의 길이가 된다.
일반 DP 풀이
import java.io.*;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[] arr = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i=0; i<n; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
int[] dp = new int[n];
dp[0] =1;
for(int i=1; i<n; i++) {
dp[i] = 1;
for(int j=0; j<i; j++) {
if(arr[i]>arr[j]) {
dp[i] = Math.max(dp[j]+1, dp[i]);
}
}
}
int max =-1;
for(int num : dp) {
max = Math.max(num, max);
}
System.out.println(max);
}
}
DP 최적화 풀이
import java.io.*;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[] arr = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i=0; i<n; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
int[] dp = new int[n+1];
int len =0;
int idx =0;
for(int i=0; i<n; i++) {
if(arr[i]>dp[len]) {
dp[++len] = arr[i];
}else {
for (idx = 1; idx <= len; idx++) {
if (arr[i] <= dp[idx]) break;
}
dp[idx] = arr[i];
}
}
System.out.println(len);
}
static int binarySearch(int[] dp, int left, int right, int key) {
int mid =0;
while(left<right) {
mid = (left+right)/2;
if(dp[mid] < key) {
left = mid+1;
}else {
right = mid;
}
}
return right;
}
}
이진탐색 DP 최적화 풀이
import java.io.*;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[] arr = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i=0; i<n; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
int[] dp = new int[n+1];
int len =0;
int idx =0;
for(int i=0; i<n; i++) {
if(arr[i]>dp[len]) {
dp[++len] = arr[i];
}else {
idx = binarySearch(dp, 0, len, arr[i]);
dp[idx] = arr[i];
}
}
System.out.println(len);
}
static int binarySearch(int[] dp, int left, int right, int key) {
int mid =0;
while(left<right) {
mid = (left+right)/2;
if(dp[mid] < key) {
left = mid+1;
}else {
right = mid;
}
}
return right;
}
}
실행결과 비교



메모리 사용량은 다 똑같지만 실행 시간을 보면 최적화 작업과 이진탐색을 사용할수록 확실히 줄어드는 것을 확인할 수 있다.
'Dot Algo∙ DS > PS' 카테고리의 다른 글
| [BOJ] 백준 2467번 용액 (Java) (0) | 2021.11.12 |
|---|---|
| [BOJ] 백준 3020번 개똥벌레 (Java) (0) | 2021.11.11 |
| [BOJ] 백준 7453번 합이 0인 네 정수 (Java) (0) | 2021.11.09 |
| [BOJ] 백준 2512번 예산 (Java) (0) | 2021.11.08 |
| [BOJ] 백준 2805번 나무 자르기 (Java) (1) | 2021.11.08 |



